Comments
- No comments found

This particular article is a discussion about a recommendation to a given standard, that of SPARQL 1.1. None of this has been implemented yet, and as such represents more or less the musings of a writer, rather than established functionality. Read at your peril!
Lately, I've been spending some time on the Github archives of the SPARQL 1.2 Community site, a group of people who are looking at the next generation of the SPARQL language. One challenge that has come up frequently has been the lack of good mechanisms in SPARQL for handling ordered lists, something that has proven to be a limiting factor in a lot of ways, especially given that most other languages have had the ability of handling lists and dictionaries for decades. As I was going through the archives, an answer occurred to me that comes down to the fact that RDF and SPARQL, while very closely related, are not in fact the same things.
RDF has had the notion of both a collection and a list type practically from the beginning. The RDFList structure is a fairly complex one, and, in essence, represents the underlying notion of a linked list. For example, suppose that you had a list of chapters in a book. Those chapters occur in a very definite order. For instance, my latest novel has the following chapters (with more removed for brevity) as given in Turtle:

Internally, Turtle uses the () braces to indicate a sequence, providing a kind of syntactical sugar over what is a considerably uglier structure.

This is a pretty basic structure using blank nodes in a chain that can be walked up one step at a time until you finally hit the predefined rdf:nil value. Each of the blank nodes can thought of as pointers to the next item in the list and to the current value of the current item in the list. The _:listPointer blank node here can then be thought of as the pointer to the whole list.
Turtle hides this unfortunate syntax, but it's still there at the foundation of RDF, and it has been causing problems almost from the moment that the syntax was introduced in 2004. When SPARQL 1.0, came along in 2007, it borrowed the Turtle syntax for an ordered list, but couldn't really do all that much about the structure itself. Worse, one of the unstated assumptions in SPARQL about the order in which a SPARQL query returned results, so that traversing lists in SPARQL could not guarantee that the ordered list would in fact remain ordered.
In 2013, with the advent of SPARQL 1.1, there might have been an opportunity to fix it. Sadly, it didn't happen, and even as list manipulation became the order of the day in most modern computer languages, SPARQL remained mysteriously broken, though most implementations did in fact honor the implicit ordering of an ordered list.
One thing that's worth noting here, and what may actually be the key to the impass, is to recognize that a list in RDF can be thought of as a datatype, but so can a list in Sparql. The distinction here is that the RDF type is actually based in the notion of triples as pointers because it is a static description of the structure, but the requirement for SPARQL is actually subtly different - the need for an interim data structure that can help facilitate queries.
Put another way, it may be worth talking about a SPARQL sequence as being different from an RDF List. What I'm proposing here is the concept that a Sequence in SPARQL should be considered closer to being an intermediate structure that may, but doesn't necessarily have to, be represented in RDF.
For instance, consider what may be seen as a trivial function called split(), which takes a string as an argument and splits the string based upon a character sequence into multiple other strings. The result of this operation would be a Sequence, with components accessed by giving the position of the sequence.

The value of ?result in this particular case would be "test", Note that ?seq in this particular case holds a sequence of items. Depending upon the implementation the variable named ?seq would actually contain an array or list if the output was JSON,
A sequence is a set of multiple items. These items do not have to be of the same type, and can even be other sequences, dictionaries, or triples as well as literal values. They will usually be used in bind statements, but the behavior of such sequences in matching statements would depend upon the items in the sequence and the position. For instance, a sequence of iri's in the subject position would of a matching statement would propagate into a list of matching subjects:

would expand out into the four matches:

Similarly, in the object position, you'd have the corresponding associations:

which maps to the rdf list equivalent.

By differentiating the rdfList (an RDF structure) from the sequence (a SPARQL datatype) the debate of datatype vs rdf rendition can finally be put to bed.
One benefit of going this route is that it becomes possible to start working with higher order functions, something that SPARQL desperately needs. For instance, consider the following sequence functions.

This retrieves the indexed item from the sequence.
Example:

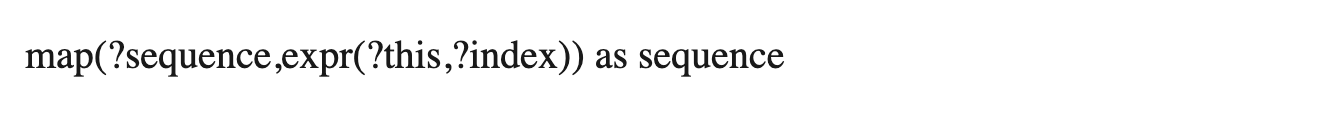
This iterates over an input sequence and then uses an expression to create a new sequence based upon each item in turn. The ?this property holds the current iterated value, while the ?index property gives the location of the item in the sequence.
Example:

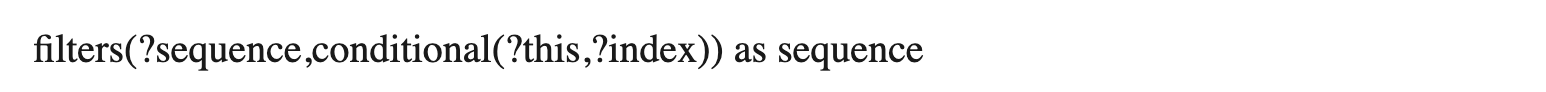
This iterates over the sequence and returns a subsequence of those items for which the conditional expression resolves to true. This returns a sequence that will be smaller than or equal to the size of the input sequence.
Example:

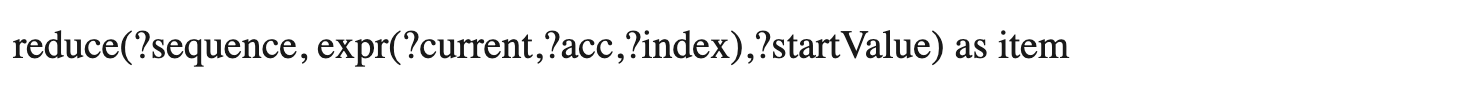
This performs a reduce operation on a sequence doing things like adding a sequence of numbers together or computing statistical operations.
Example:

sequence(?item1 ?item2 ...) as sequence
This creates a sequence of items from a list of items.
Example:

toSequence(?) as sequence
This takes an rdf list pointer and converts it into a sequence of items, Note that this is a lossy operation - the blank nodes used as item pointers are lost in the conversion.
Example:

fromSequence(?sequence, ?template) as triples*
The behavior of this is somewhat more complex, as it generates the triples necessary to support an RDF list. The exact behavior needs to be determined.
Example:

split(?str, ?regex) as Sequence
This takes a string and splits it into ordered items in a sequence, based upon a regular expression joining characters together.
Example:

join(?sequence, ?separator) as String
This constructs a string from a sequence, using the ?separator characters to join the items together. Note that this is just a specialized form of the reduce() function.
Example:

Other functions, such as subsequence, can be derived in much the same manner from the existing sequence operators such as map(), filters(), and reduce().
Beyond lists there are other features that can be introduced in the next iteration of SPARQL, beyond just simply the RDF-Star features currently being discussed. These include, most notably, the use of Dictionary objects (which have a corresponding RDF equivalent in Containers), which have both obvious application and relatively minimal performance impact. An important aspect of both Sequences and Dictionaries is that they are immutable - they are side-effect free.
Sequences would also enable other potential additions, including two that have transformed Javascript: arrow functions and template literals. An arrow function (or Monoid) is the generalization of a function. It takes a sequence of parameters and uses these parameters to define a function that can in turn return a sequence of values. The function itself is side-effect-free. It should be noted that in the map() function above, it was necessary to predefine the variables ?item and ?index, because that cannot currently be done in Sparql. However, the operator => could be used to make such functors within bind() statements:

which would generate the message "World Hello". The params function() turns a sequence of variable names and associates them with the expressions as a function
Template Literals are used in several languages (under various names), and work by replacing parameters within a specialized string (in Javascript denoted by the backtick character ( ` ) with the values of those parameters. For instance,

If the labels of person1 and person2 are "Jane" and "Mary" respectively and the relationship is "is married to" then the assertion() arrow function creates the string "Jane is married to Mary.".
What's so significant about this is that this approach makes it possible to create declarative SPARQL functions without having to express these functions as RDF, which is both awkward and inconvenient. What's more, by using sequences and declarative arrow functions, it makes it far easier to compose functions together in a pipeline, permitting faster processing and pre-optimization.
It should be stressed that all of these are contingent upon having a sequence object in place, and that none of what is given above currently exists in any implementation. Efficient and readily codable sequence processing is essential for so many tasks, including analytics and machine learning, and it is time for SPARQL to be upgraded, or risk seeing it becoming increasingly irrelevant.
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest