As the Text Metadata Services (TMS) Lead in Singapore, I wanted to share my knowledge by writing a short piece on an important aspect of Natural Language Processing (NLP) called Named Entity Recognition (NER). Named Entity Recognition is not to be confused with Named Entity Resolution. A simple example to distinguish between the two is that a machine reading a document might recognize a person, say William Henry Gates and a second person in the same document, say Bill Gates. Named Entity Resolution is a way in which these two names can be resolved to a single person whom we all know as one of the founders of Microsoft, Bill Gates.
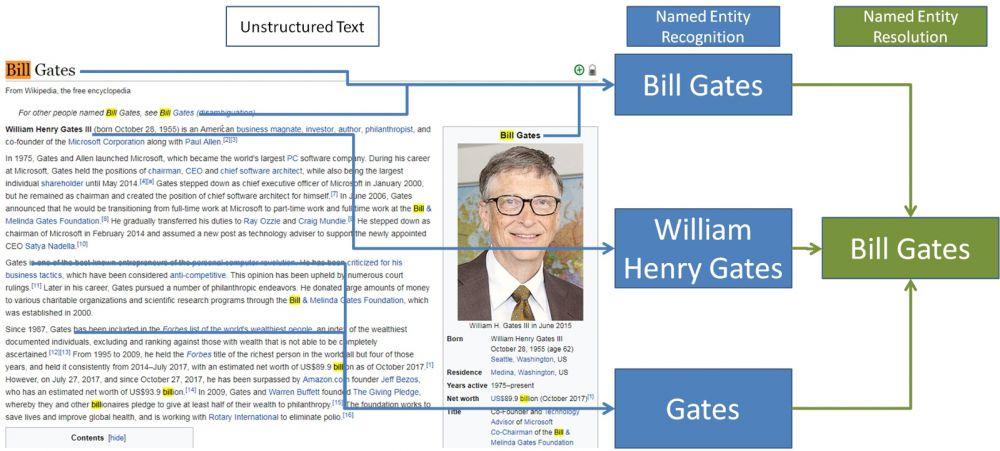
As you can see, there are a few steps that need to happen before we can get to the Named Entity Resolution step.
Context
What is also important to note is the Named Entitity's signature or fingerprint which provides the context of what we are looking for. The fact that this wikipedia page's url is .../wiki/Bill_Gates is useful context that this likely refers to the resolved named entity, Bill Gates.
We've jumped in to this blog and started talking about the term `Named Entities`, for some of you who are not aware, there are widely understood to be three high level types of Named Entities following the AFNER convention
- TIMEX - Times, Dates and so on
- NUMEX - Numbers, Percentages and so on
- ENAMEX - Names, Places, and so on
So you can see that a Named Entity is an object or topic in the real world and that is how we will consider them in this article.
For the purposes of this blog and in the interests of simplicity we will drill in to the ENAMEX type Named Entities. However, for the avoidance of doubt and completeness of examples we note that for NUMEX; 0.1 and 10% might resolve to 10% and for TIMEX; MCMXCII and '92 would likely both resolve to 1992.
Classification
NER can be done in a few ways but before we go in to it, I would like to mention Thomson Reuters Business Classification (TRBC), this as you may have guessed, is part of the ENAMEX universe.
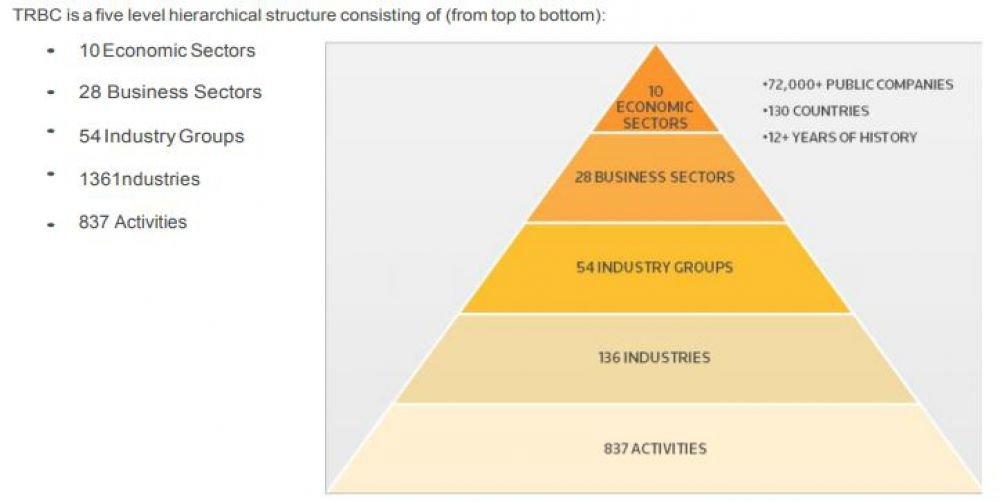
The TRBC is only a classification system and the actual companies (public and private) will fit in to one of these using the TRBC Methodology. It is how we find those companies which is the most important aspect of Named Entity Recognition.
An example of how Named Entities might follow various taxonomies of Person, Organizations, Financial Assets, Locations and Events:
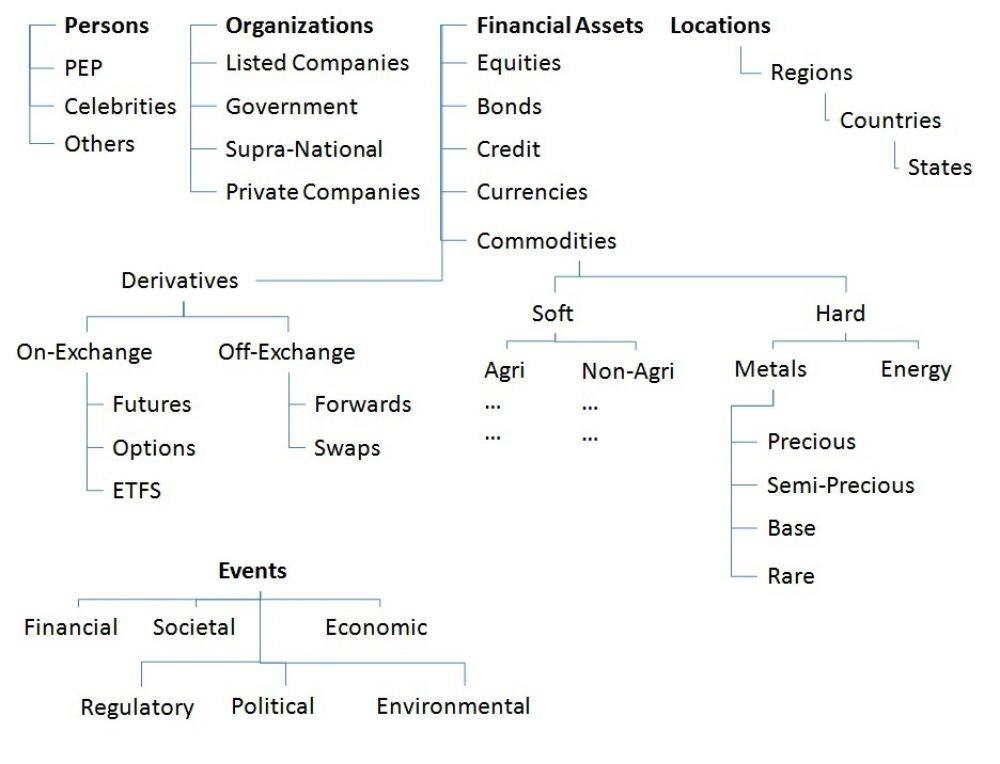
It is not necessary for Named Entities to follow a discrete taxonomy (tree-like structure) they may also follow an ontology (graph-like structure) in which case a Named Entity can be classed in multiple ways simultaneously.
So now that we have established the concepts of Named Entities we can go in to the next step of explaining a little bit of how we can recognise them.
Feature Engineering
A feature is an attribute of the data set that gives a Data Scientist a feeling that a predicting variable is important in determining the value of the predicted variable. An example of a predicting variable is the month of the year and the predicted variable, a temperature range for a specific city (e.g July, London 14° C - 22° C). Another example of a predicting variable are two capitalised words next two each other and the predicted variable is whether these are the first and last name of a person which is usually the case (e.g Salman Jaffer, Person). A feature may be weak or strong. Strong features typically have high positive, that is, closer to 1 or low negative, that is, close to -1 correlation coefficients with the predicted variable.
Word Level Features
Some word level features are:
- Alphanumeric (Usually names are not combinations of numbers and letters)
- Initial Caps (Usually capitalised words are important named entities)
- All numbers (Named entities very rarely are made up of pure numbers, these will likely fall in the TIMEX or NUMEX domains)
- Single Characters (Usually letters by themselves such as I, A are not named entities
From the four examples above can you tell which have high positive and low negative correlation with the predicted variable of whether the term is a named entity or not? On their own, these features have quite low predictability and the feature important depends on the language, for example, Chinese does not use capitalization and in German, all nouns are capitalized.
Dictionary Look-Up
Another approach is to reference a pre-defined dictionary or lexical which can be refreshed and to look up each word in the document against the dictionary. The F1-Score of an approach such as this is usually in the 60-70 range, with one study resulting in a precision, (ratio of terms correctly vs incorrectly classified as Named Entities) of around 74 and a recall, (ratio of terms tagged as Named Entities versus terms that should have been tagged as Named Entities) of around 55.
Part of Speech Tagging (POS)
Part of Speech Tagging, also known as POS Tagging has a much higher F1-Score than the previous two approaches, typically over 80 with a precision and recall both in the low to mid 80s. Important POS tags whose features are
1. Preposition
2. Adjective
3. Noun
4. Pro-Noun
5. Verb
Punctuation
Punctuation marks are also seen as a key indiccator as to what is considered a strong feature. Some examples are;
- Comma
- Period
- Parenthesis
- Exclamation mark
- Question mark
We cite an example from the paper, "Applying machine learning for high performance named-entity extraction" by S. Baluja, V. Mittal, R. Sukhthankar which used Thomson Reuters own data where 29 features were drawn from the above word level, dictionary lookup, part of speech tagging and punctuation based approaches to train various models using tokens of 0, 1, 2 and 6 word sequences.
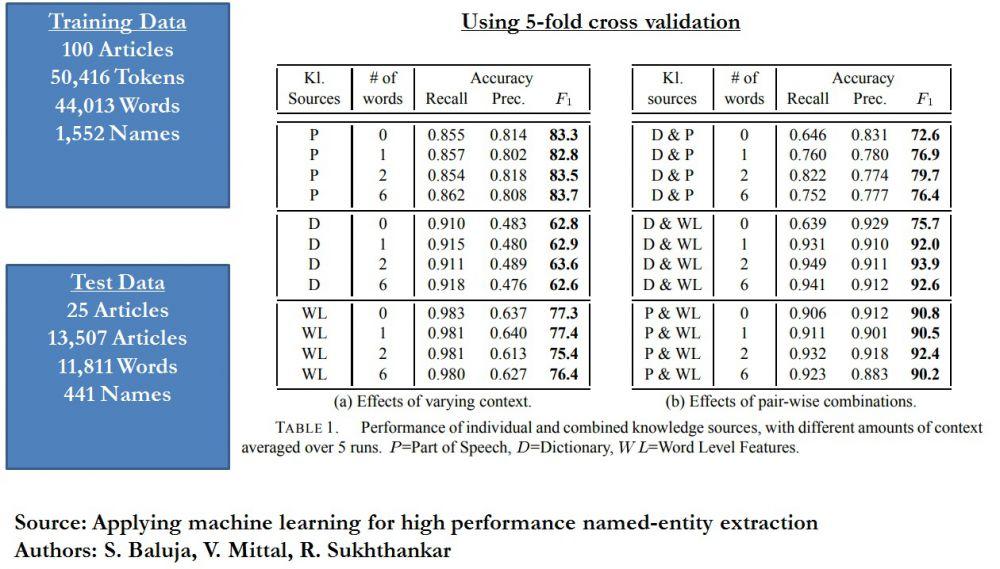
As we can see from the results, the combinations of dictionary lookup and word level features across 2 token word sequences (also known as bi-grams) showed the highest F1 score (93.9), much higher than the F1 scores if they were used individually (63.6 and 75.4 respectively). It can also be seen that the part of speech tagging F1 scores (83.3, 82.8, 83.5 and 83.7) were not as sensitive to the length of the token sequences provided. Combinations of Dictionary Look-Up and Part of Speech tagging did not perform as well.
Summary
Finally, to summarize I would like to illustrate one possible classification structure;
- Entities: (Companies, people, places, products, etc.)
- Relationships: (John Doe works for Acme Corp.)
- Facts: (John Doe is a 42-year old male CFO)
- Events: (Jane Doe was appointed a board member of Acme Corp.)
- Topics: (Story is about M&As in the Pharma industry)
I hope this article has given you an idea of Named Entity Recognition and look forward to your comments!



Leave your comments
Post comment as a guest