
GPT-3 is generating a lot of hype.
The main aim of this article is to understand the future of artificial intelligence (AI), GPT-3 model and NLP.
This article is intended to enable those with a non-technical background to understand how the mechanisms work and what the business use cases are. However, there is a section at the end for those with a more technical background including hyperlinks to more technical articles.

Transformers with Self-Attention mechanisms have been revolutionising the fields of NLP and text data since their introduction in 2017.
The most high profile and advanced Transformer based model GPT-3 (see below) has attained a great deal of attention in the press recently including authoring an article that was published in the Guardian.
What is GPT-3?
Generative Pre-trained Transformer 3 (GPT-3) is an autoregressive language model that uses Deep Learning to produce human-like text and was introduced in May 2020. GPT-3 was introduced by Open AI.
How Does GPT-3 Work?
GPT-3 is a Deep Neural-Network language model that predicts the probability of a given sentence existing in the world. An example may be I am going to meet my best friend for a walk is more likely than I am going to meet an apple for a walk (albeit in the Covid world a Zoom call with my best friend might be more apt) with the language model able to label meeting my friend as more probable than meeting an apple.
Dale Markowitz in OpenAI’s new GPT-3 language explained notes that GPT-3 is trained on an unlabelled dataset using the Common Crawl and Wikipedia with a random removal of words leaving the model to learn to fill the gaps by application of solely the neighbouring words used as context.
The architecture of the model is based upon a Transformer Deep Neural Network model.
The model is truly vast with 175 billion parameters and is the biggest language model created to date. The vast size of the model is responsible for GPT-3 appearing to be intelligent and sounding like a real person at times.
An advantage that GPT-3 possesses unlike other language Transformer models is the capability without specific tuning to conduct a specific task such as language translation or authoring a poem or an article with less than 10 training examples required to complete the task, due to its vast size. A reason why Natural Language Machine Learning practitioners are so excited about GPT-3 is that other Natural Language models may require a huge number of examples in order to for example perform English to Greek translation.
GPT-3 is able to perform custom language tasks without the need for the vast training data required with other models.
What is a Transformer and what is Self-Attention?
The Transformer is a neural network architecture that uses attention layers as its primary building block. It is a relatively new technique that was only introduced in 2017 and has been rapidly yielding exciting results in the field of NLP and text data.
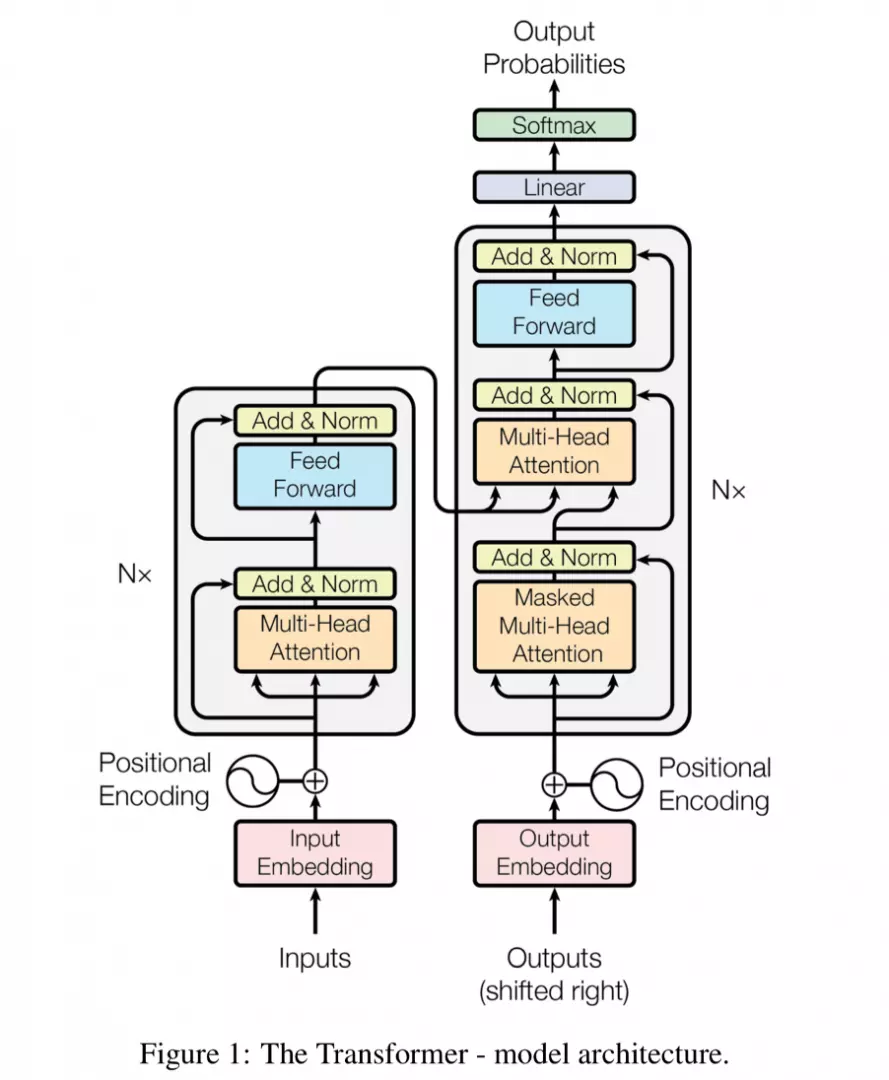
Transformers with Self-Attention mechanisms were introduced in 2017 by a team at Google with Vaswani et al., in a paper entitled Attention is All You Need. The paper caused a great deal of surprise within the Natural Language Processing (NLP) research community that a model using no convolution or recurrence was able to outperform the existing existing Sequence-to-Sequence neural machine translation models of Google.
Attention all you need refers to a Sequence-to-sequence (or Seq2Seq) architecture relating to a Neural Network that transforms a particular sequence comprising elements, for example the words in a given sentence into a different sequence.
Such models are particularly effective at translating taking a sequence of words from a given language and transforming it into another sequence of words that belong to a different language.
Giuliano Giacaglia in How Transformers Work observes that Transformers were devised with the aim of solving the problem of neural machine translation also known as sequence transduction. It refers to a given task that results in the transformation into an output sequence from an input sequence. Examples include speech recognition and text-to-speech transformation.

Sequence transduction. The input is represented in green, the model is represented in blue, and the output is represented in purple. Source of Gif above and for more details see Jay Alammar Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Previously Recurrent Neural Networks and in particular Long-Short-Term-Memory (LSTM) based models were applied to this task.
Seq2Seq models consist of a combination of an Encoder and a Decoder with the Encoder taking sequences as inputs and mapping to what is known as a n-dimensional vector or higher spaced dimension. The vector is then placed into a Decoder that generates a resulting output sequence that may for example be in a different language.
We can picture this taking English and Greek as an example. In order to translate the English language sentences into Greek the English sentence will be amended by Encoder into an abstract language and as the Decoder is familiar with that abstract language it will translate it into Greek. Hence we are able to perform effective English to Greek translation and vice versa. In order for a model to learn the abstract language the model is trained on a large data set of examples of the language. The Attention mechanism focuses on the input sequence and determines the importance of other constituents of the sentence at each point for example the way in which you as a human may hold key words in your head as you read an entire sentence.
Source for image above Vaswani et al., 2017 entitled Attention is All You Need
An important part of the Attention-mechanism is that it enables the Encoder to focus on keywords that are relevant in relation to the semantics of a given sentence, and provides them to the Decoder alongside the regular translation. This in turn allows the Decoder to understand the parts of the sequence in the sentence that are significant and provide contrast to the sentence.
A further significant milestone in Transformers and natural language relates BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Business and Real-World Applications
The business applications of Transformers with Self-Attention Mechanism include the following (non-exhaustive list):
- Language Translation for example Bidirectional Encoder Representations from Transformers (BERT) is a technique for natural language processing (NLP) pre-training developed by Google. BERT was created and published in 2018 by Jacob Devlin and his colleagues from Google. Google is leveraging BERT to better understand user searches and perform text classification;
- Transformers with Self-Attention have been used for language translation as noted above;
- Sentiment Analysis for the Financial Sector work that my team and I engaged on within the Fintech world;
- Healthcare and Electronic Health Records (EHRs): for example Li et al. authored BEHRT: Transformer for Electronic Health Records that was published in Nature and reported that they presented "A deep neural sequence transduction model for electronic health records (EHR), capable of simultaneously predicting the likelihood of 301 conditions in one’s future visits. When trained and evaluated on the data from nearly 1.6 million individuals, BEHRT shows a striking improvement of 8.0–13.2% (in terms of average precision scores for different tasks), over the existing state-of-the-art deep EHR models. In addition to its scalability and superior accuracy, BEHRT enables personalised interpretation of its predictions";
- Drug Discovery for example Maziarka et al. presented Molecule Attention Transformer.
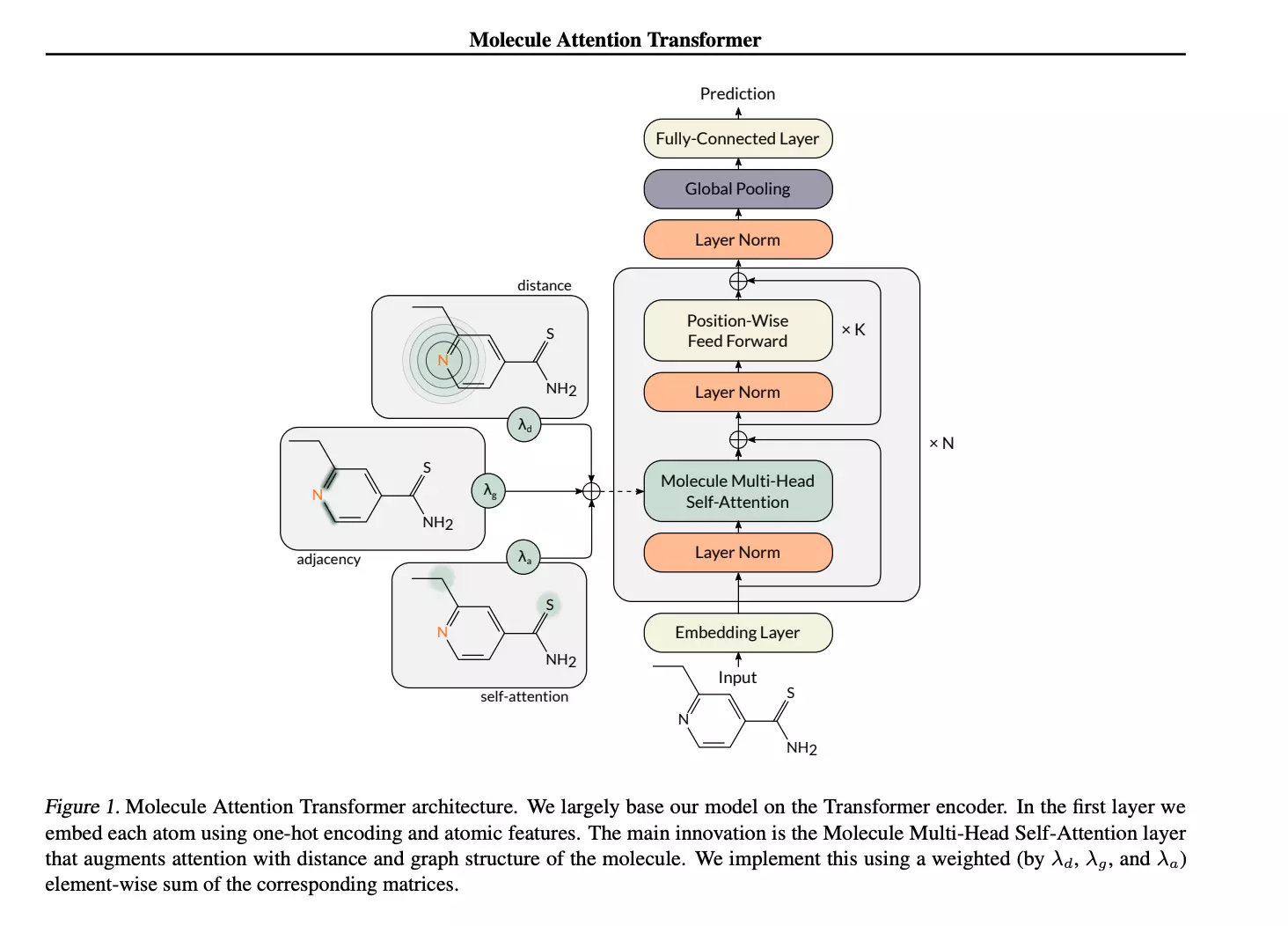
Source for image above Maziarka et al. Molecule Attention Transformer
- Another example of a research application in healthcare is provided by Daria Grechishnikova Transformer neural network for protein-specific de novo drug generation as a machine translation problem who notes that "Drug discovery for the protein target is a very laborious, long and costly process. Machine learning approaches, and deep generative networks in particular, can substantially reduce development time and costs. However, the majority of methods imply prior knowledge of protein binders, their physicochemical characteristics or three-dimensional structure of the protein. The method proposed in this work generates novel molecules with predicted ability to bind target protein relying on its amino acid sequence only. We consider target specific de novo drug design as a translational problem between amino acid "language" and SMILE (Simplified Molecular Input Line Entry System) representation of the molecule. To tackle this problem, we apply Transformer neural network architecture, the state-of-the-art approach in sequence transduction tasks. The Transformer is based on a self-attention technique which allows capturing long-range dependencies between items in sequence. The model generates realistic diverse compounds with structural novelty."
- Text to speech;
- Transformers have also been combined with Convolutional Neural Networks to Streamline the Computer Vision process by Facebook AI Research (FAIR). An article in VentureBeat noted that "Six members of Facebook AI Research (FAIR) tapped the popular Transformer neural network architecture to create end-to-end object detection AI, an approach they claim streamlines the creation of object detection models and reduces the need for handcrafted components. Named Detection Transformer (DETR), the model can recognize objects in an image in a single pass all at once."

Source for image above DETR Facebook AI Research
- VentureBeat also noted that "DETR is the first object detection framework to successfully integrate the Transformer architecture as a central building block in the detection pipeline, FAIR said in a blog post. The authors added that Transformers could revolutionize computer vision as they did natural language processing in recent years, or bridge gaps between NLP and computer vision."
- A Transformer architecture has also been used alongside an LSTM and Deep Reinforcement Learning in a gaming context by DeepMind in the strategy game AlphaStar. See also the DeepMind post A new model and dataset for long-range memory that introduces a new long-range memory model, the Compressive Transformer.
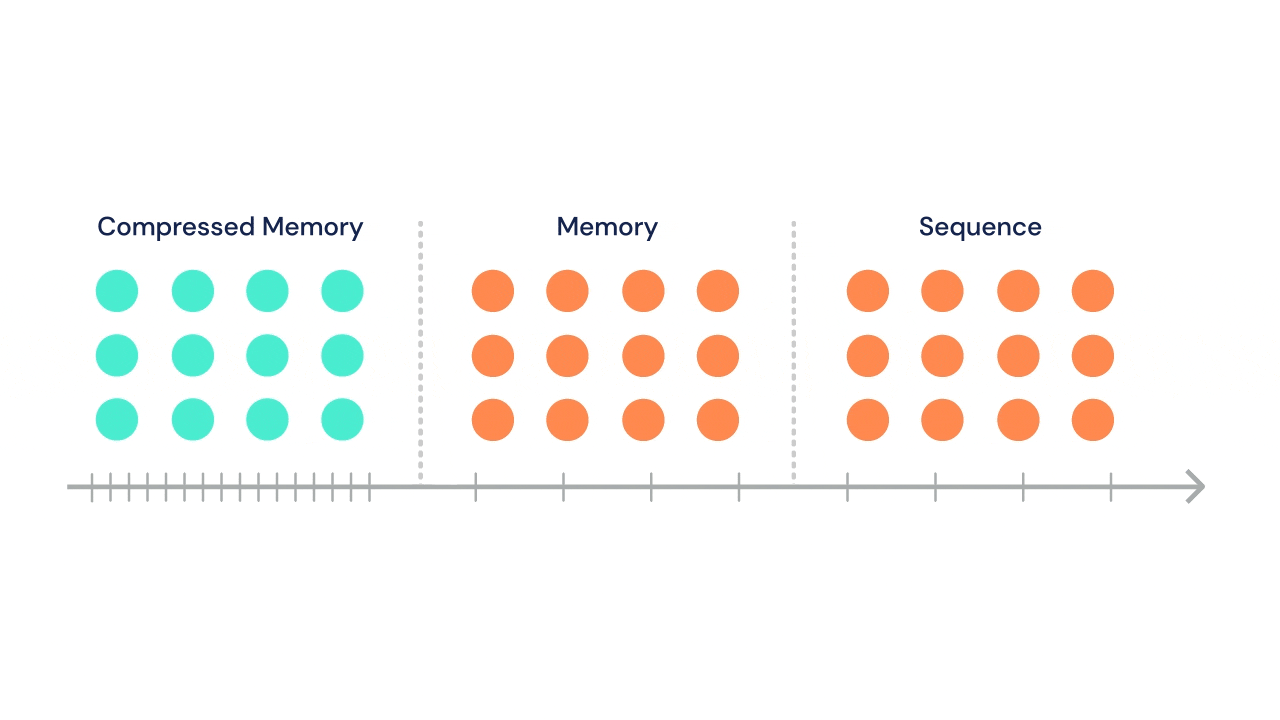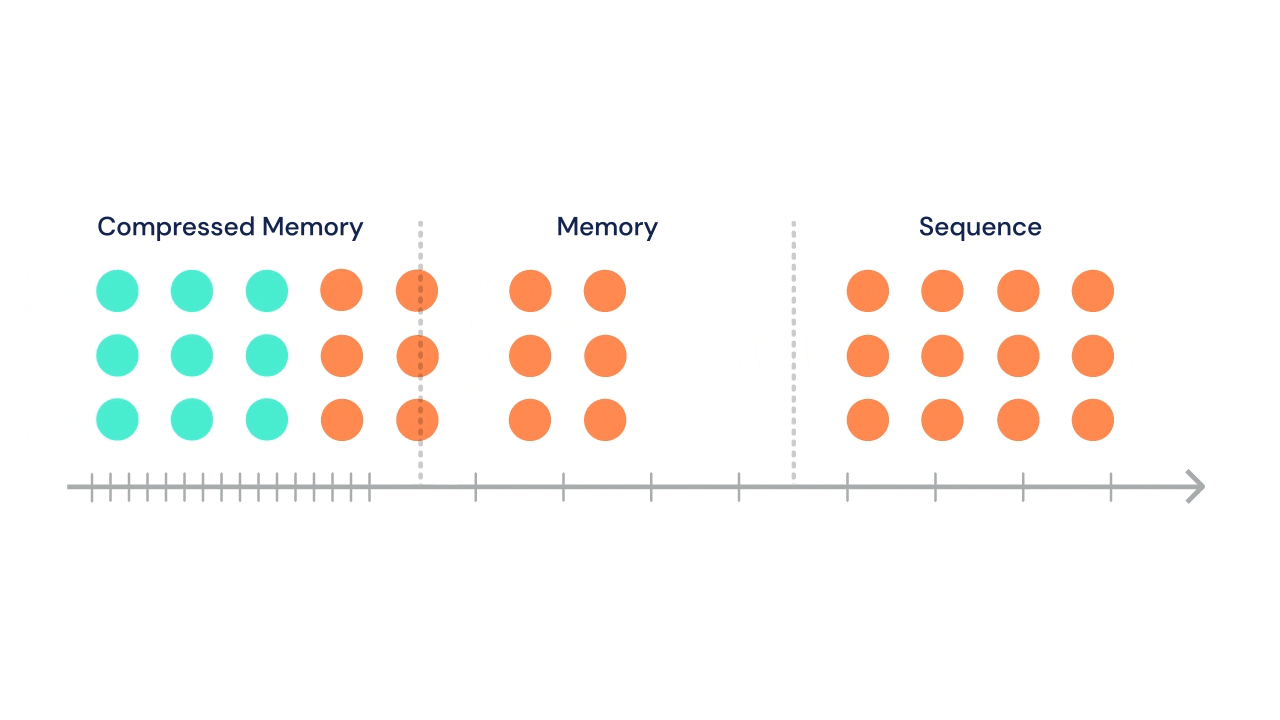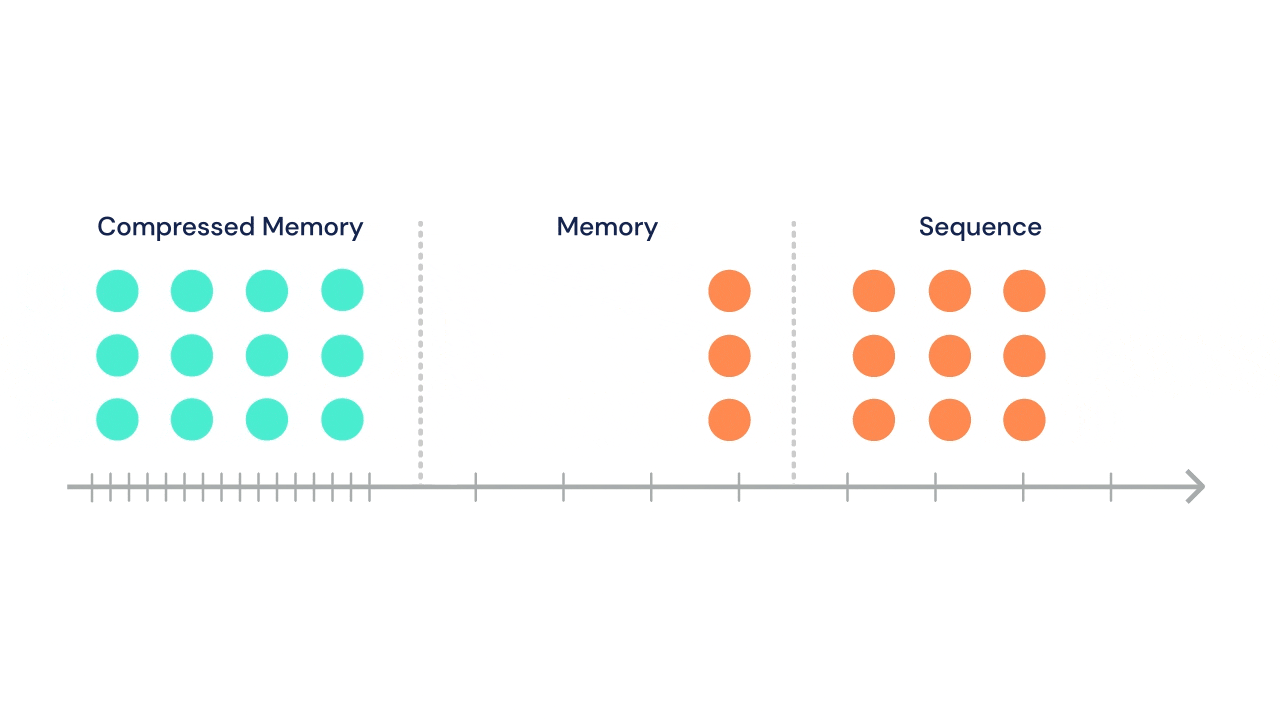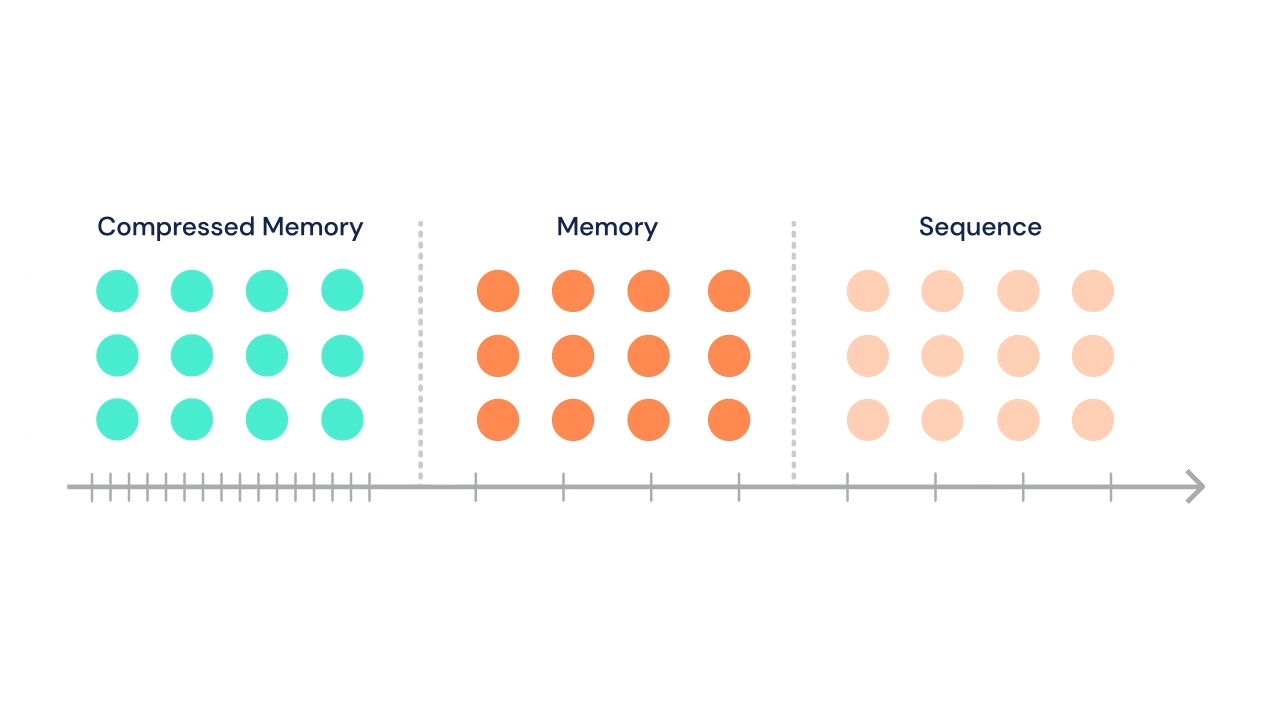
Source for gif above DeepMind Compressive Transformer: a long-range sequence attentive sequence model which characterises the past with a granular short-term memory with a coarse compressed memory
- Anti Social Online Behaviour Detection with BERT;
- Neural Document Summarization;
- Wu et al. argued in Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case that Transformer models could also produce favourable results in Time Series forecasting;
- Transformers have also been used in recommender systems, see Order Matters: Alibaba’s Transformer-based Recommender System;
- Furthermore in my vision of the not too distant future with 5G enabled AR glasses, language will be no barrier with Transformers enabling Neural Machine Translation to allow brands to interact with the user irrespective of what language the user speaks as they walk around in any location and even a different country from where they normally reside. The translation could be played from text to speech to the end user via headphones and allow them to interact with objects around them thereby merging the physical and digital world with both Computer Vision (CNNs) with object detection and Transformers working side by side to enable a highly personalised experience (see video below as an example).

An example of the research work by Microsoft and others using Transformers for Neural Translation is provided by Xia et al. Tied Transformers: Neural Machine Translation with Shared Encoder and Decoder.
I believe that the application of Transformers alongside Computer Vision will provide the next big wave of digital transformation and product when 5G enabled augmented reality (AR) and mixed reality (XR) glasses hit the market over the next few years.
The sections below look at the history and more technical aspects of Attention and also why the Transformer with Self-Attention is a step change relative to the previous Deep Learning approaches in the field. It is more intended for those who wish to go deeper into the topic and resources are provided via the hyperlinks to help provide more details.
For those who wish to watch videos on GPT-3 and Transformers note:
Jay Alammar How GPT-3 Works - Easily Explained with Animations

And The A.I. Hacker - Michael Phi Illustrated Guide to Transformers Neural Network: A step by step explanation

Where Did The Attention Come From? The history of Attention-Mechanism in Natural Language
Attention first appeared in the NLP domain in 2014 with Cho et al. and Sutskever et al. with both groups of researchers separately arguing in favour of the use of two recurrent neural networks (RNN), that were termed an encoder and decoder.
For a more detailed look at the history of the development of Attention and Transformers in this domain see the article by Buomsoo Kim "Attention in Neural Networks - 1. Introduction to attention mechanism."
A selection of key papers to note are shown below:
- Seq2Seq, or RNN Encoder-Decoder (Cho et al. (2014), Sutskever et al. (2014))
- Alignment models (Bahdanau et al. (2015), Luong et al. (2015))
- Visual attention (Xu et al. (2015))
- Hierarchical attention (Yang et al. (2016))
- Transformer (Vaswani et al. (2017))
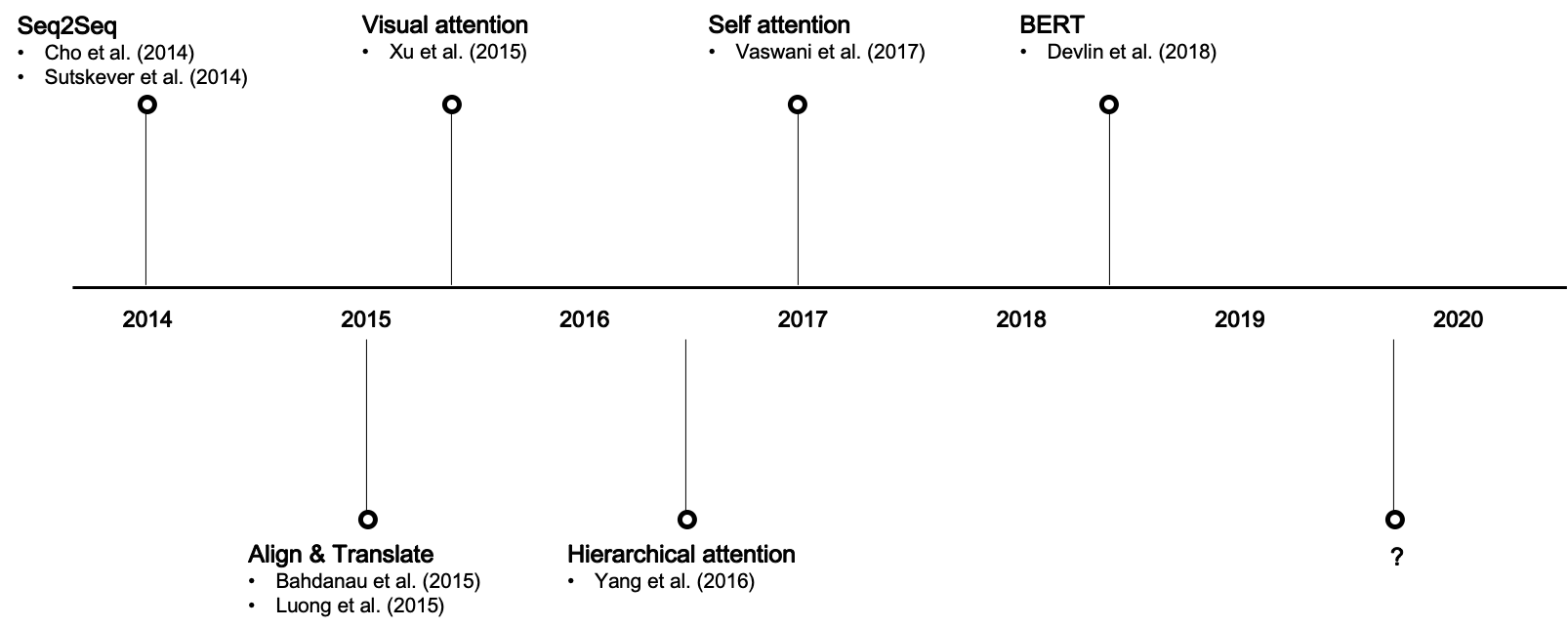
Source for image above Buomsoo Kim "Attention in Neural Networks - 1. Introduction to attention mechanism."
Will Future Versions of the GPT-3 Lead to AGI? The Rivalry between Connectionists vs Symbolists / Logic Proponents in AI
The capabilities of GPT -3 has led to a debate between some as to whether or not GPT-3 and its underlying architecture will enable Artificial General Intelligence (AGI) in the future against those (many being from the school of logic and symbolic AI) who believe that without some form of logic there can be no AGI. The truth of the matter is that we don't know as we don't really fully understand the human brain. With science and engineering we work upon the basis of observation and testing. This section also addresses points raised by Esaú Flores.
Gary Grossman in an article entitled Are we entering the AI Twilight Zone between AI and AGI? observed that in February 2020, Geoffrey Hinton, the University of Toronto professor who is a pioneer of Deep Learning, noted: “There are one trillion synapses in a cubic centimeter of the brain. If there is such a thing as general AI, [the system] would probably require one trillion synapses.”
The human brain has a huge number of synapses. Each of the 1011 (one hundred billion) neurons has on average 7,000 synaptic connections (synapses) to other neurons. It has been estimated that the brain of a three-year-old child has about 1015 synapses (1 quadrillion). This number declines with age, stabilizing by adulthood. Estimates vary for an adult, ranging from 1014 to 5×1014 synapses (100 to 500 trillion). An estimate of the brain's processing power, based on a simple switch model for neuron activity, is around 1014 (100 trillion) synaptic updates per second (SUPS)."
I have noted arguments that Transformer architecture that underlies GPT-3 maybe combined with Deep Reinforcement Learning for a pathway towards AGI (note the research by DeepMind above in the business applications section relating to gaming) in particular when we develop larger models and higher performing hardware whilst others argue that without logical or symbolic AI there will be no AGI.
Those outside of AI research may not be aware that there has been a constant debate within AI research of what the best approach is to advancing the field of AI between rival approaches.
The rivalry between two different schools of AI goes back to the early days of the founding of AI as an academic area of research. TheConnectionist school of thought is aligned to the approach of Artificial Neural Networks (referred to as Deep learning when there are multiple hidden layers) and the rival school of Logical and Symbolic AI that dominated much of AI research and practice in the 1950s and into the 1980s and was championed by John McCarthy. Some have suggested that Marvin Minsky was the champion of connectionism but MIT report that Minsky often argued that a purely “connectionist” Neural Network-focused approach would never be sufficient to imbue machines with genuine intelligence on its own. It is also worth noting that the field of Deep Learning was combined with Reinforcement Learning by DeepMind with the resulting Deep Reinforcement Learning field providing exciting developments in gaming environments with AI agents. Furthermore, DeepMind combined DeepReinforcement Learning with a (Monte Carlo) Tree Search Approach in the AlphaGo model that defeated the then WorldGo Champion Lee Sedol. Hence many Deep Learning researchers have in fact been willing to experiment.
The two AI professors who taught me were from opposite schools of thought. One Professor came from the school of Logic and stated Neural Networks were just a series of Logistic Regressions with a Softmax function in the final layer at the end and without logic there would be no real AI (AGI) and that person was really not interested in Deep Learning. The other professor was a connectionist and believed that continued research in Deep Neural Networks were essential for achieving AGI and encouraged me to research the field including looking at ways to connect ANNs with other approaches. I had to learn both approaches (solving the Barber's paradox and solving back-propagation for a multi-layer neural network with a non programmable and basic calculator in the same exam was challenging from a time perspective!) but I fell in love with the Deep Neural Network architecture the moment that I saw one. That said many in the AI space, myself included, would use whatever system yields the best results otherwise commercially we will fail.
Hence if another approach works better than we will adopt it rather than clinging onto an approach that does not perform to best in its class. It is important that tech journalists understand that in a fast moving field such as AI we are constantly looking at what works best and how to improve upon it. AGI will not arrive magically overnight and there are those who have been critical of Deep Learning approaches (criticism is welcome to make one stronger and address the issues) but have not managed to progress their alternative approaches in any material manner for many years.
As Ben Dickson in What is Artificial General Intelligence notes "symbolic AI has some fundamental flaws. It only works as long as you can encode the logic of a task into rules. But manually creating rules for every aspect of intelligence is virtually impossible." Logic or Symbolic AI was heavily in fashion in the 1980s until it failed to scale and the Second AI winter arose. It may be that combining Logic or symbolic AI with Deep Learning may yield useful results.
It is also worth noting that Expert Systems such as LISP once had a huge amount of investment and dominated the field, for example it is observed that "corporations around the world began to develop and deploy expert systems and by 1985 they were spending over a billion dollars on AI, most of it to in-house AI departments." Adjust 1 billion dollars to its equivalent today and it is an awful lot of money. However, the market collapsed in 1987 leading to the second AI winter. "Commercially, many LISP companies failed, like Symbolics, LISP Machines Inc., Lucid Inc., etc. Other companies, like Texas Instruments and Xerox, abandoned the field." The approach that dominated AI with Expert Systems and the techniques that underlay them in the 1980s failed to scale successfully in the real world.
However, perhaps just as Deep Learning combined with Reinforcement Learning has led to interesting results with AI agents in simulated environments (to date) we may find that Deep Learning combined with symbolic AI or alternatively evolutionary approaches may be the way forward to more advanced AI systems or we may simply find that the more powerful Transformer mechanisms with Self-Attention when combined with advanced and more powerful hardware will get us there (a kind of brute force and power argument) and ensuring that we've solved for catastrophic memory loss to enable true generalisation or multi-tasking.
Interesting research was noted by PureAI editors in an article entitled "Neuro Symbolic AI Advances State of the Art on Math Word Problems" where it is observed that "The new Neurosymbolic AI approach used by Microsoft Research essentially combines two existing techniques: neural attention Transformers (the "Neuro" part of Neurosymbolic AI) and tensor product representation (the "-symbolic" part)."
Research work is also underway in relation to Neuro Symolic AI with the likes of Microsoft Research, MIT with IBM and DeepMind, with Will Knight at MIT reporting that article Two rival AI approaches combine to let machines learn about the world like a child and observing that "Together, Deep Learning and symbolic reasoning create a program that learns in a remarkably humanlike way."
See also: Sai Krishna in Neuro-Symbolic AI: Coming Together of Two Opposing AI Approaches.
Another potential approach towards AGI was set out in detail by DeepMind in the PathNet paper with Carlos E. Perez providing an insightful overview in DeepMind’s PathNet: A Modular Deep Learning Architecture for AGI.
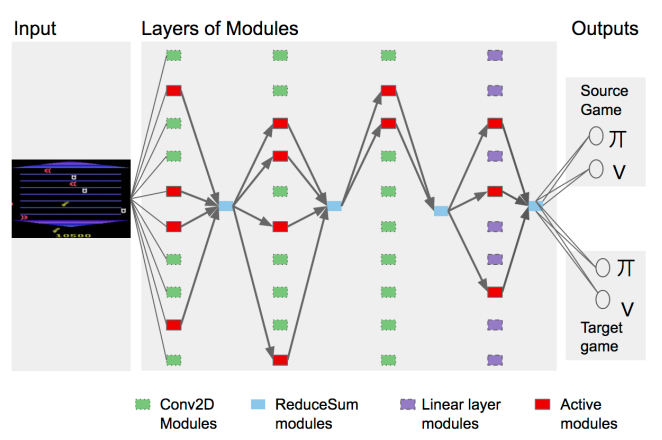
Source for image above : https://arxiv.org/pdf/1701.08734v1.pdf
The reality is that we don't know for certain which approach will genuinely yield AGI or stronger AI. There are competing theories and ideas. If anyone really knows then they should be asked why they have not created AGI yet.
In engineering and science we test and objectively observe and if one system yields better results then there will be no hiding. Different approaches are already well under way in the research side on working towards stronger AI and we'll objectively find out over the years ahead which approach is more likely to yield a successful pathway towards AGI. The next article will review the latest in the advancements in AI techniques and what they mean for us in a real-world context. This will include the exciting areas of Neuroevolution and other recent exciting advancements in the field of AI.
We can state today that GPT-3 is not an AGI, however, it does represent a significant step forwards in language modelling and will likely hold a place in the history of AI as a benchmark model and potential pathway towards AGI or at least stronger AI (time will tell).
Extra Section: Explaining the Encoder Decoder Mechanism in more detail - note for those who want to get more technical
Reda Affane Understanding the Hype Around Transformer NLP Models, Dataiku explains the encoder decoder mechanism in more detail:
"Typically, a machine translation system follows a basic encoder-decoder architecture (as shown in the image below), where both the encoder and decoder are generally variants of recurrent neural networks (RNNs). To understand how a RNN works, it helps to imagine it as a succession of cells. The encoder RNN receives an input sentence and reads it one token at a time: each cell receives an input word and produces a hidden state as output, which is then fed as input to the next RNN cell, until all the words in the sentence are processed."
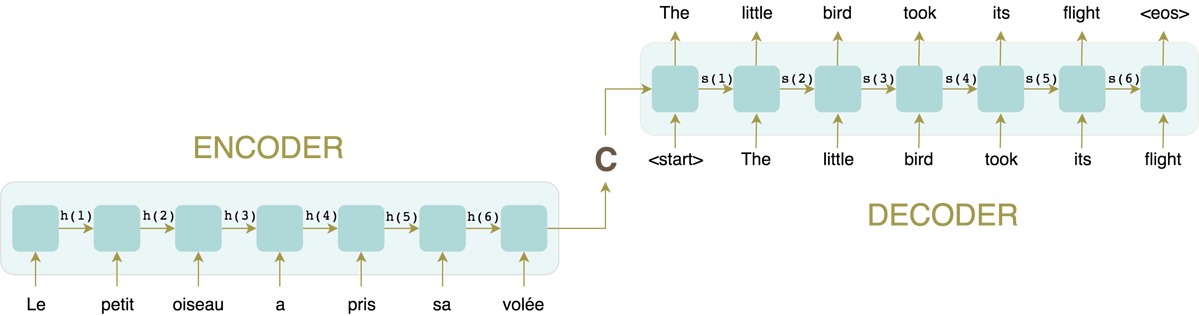
Reda Affane Understanding the Hype Around Transformer NLP Models, Dataiku
"After this, the last-generated hidden state will hopefully capture the gist of all the information contained in every word of the input sentence. This vector, called the context vector, will then be fed as input to the decoder RNN, which will produce the translated sentence one word at a time."
"But is it safe to reasonably assume that the context vector can retain ALL the needed information of the input sentence? What about if the sentence is, say, 50 words long? Because of the inherent sequential structure of RNNs, each input cell only produces one output hidden state vector for each word in the sentence, one by one. Due to the sequential order of word processing, it’s harder for the context vector to capture all the information contained in a sentence for long sentences with complicated dependencies between words — this is referred to as the bottleneck problem."
Solving the Bottleneck Problem With Attention
Attention to particular words was developed by researchers to solve for the bottleneck problem given that a human would give particular attention to a given word they were currently translating.
The process of Attention enabled Neural Networks to achieve a similar behaviour with a focus on a portion of the subset of the sentence that they were provided. As each input to the RNN results in a hidden state vector relating to every word that was input the network is able to concatenate the vectors, acreage them and weight them to give greater important to particular words from the input sentence and that in turn possess greater relevance to the decoding of the following word (output sequence).
Towards Transformer NLP Models
Attention may be viewed as a revolutionary concept in seq2seq approaches like translation.
For more information see Reda Affane Understanding the Hype Around Transformer NLP Models, Dataiku for an excellent summary of the workings of the Transformer NLP models.
A summary of the advantages that result include removing the inherent sequential structure of RNNs, which hinders the parallelization of models.
"Attention boosts the speed of how fast the model can translate from one sequence to another. Thus, the main advantage of Transformer NLP models is that they are not sequential, which means that unlike RNNs, they can be more easily parallelized, and that bigger and bigger models can be trained by parallelizing the training. "
What’s more, Transformer NLP models have so far displayed better performance and speed than RNN models. Due to all these factors, a lot of the NLP research in the past couple of years has been focused on Transformer NLP models.
Some notable Transformer models to be aware of (non-exhaustive list):
- Attention Is All You Need Google 2017
- Bidirectional Encoder Representations from Transformers (BERT) Google 2018
- Open AI GPT June 11, 2018
- GPT-2 February 14, 2019 Open AI
- Megatron NIVIDIA
- DeepSpeed Microsoft AI & Research
- GPT-3 May / June 2020 Open AI
Challenges with the Previous Techniques
This section will address RNNs and LSTMs explaining Vanishing and Exploding Gradient and also explain in more detail where they fell short on NLP relative to the Transformers with Self-Attention.
Vanishing gradients relate to the process of backpropagation and gradient descent. Our objective is to minimise losses in the network.
For those outside of Data Science an intuitive and simplistic way to visualise and understand the issues of exploding and vanishing gradients with gradient descent is a skier going down the hill slope.
If the slope is too steep then the skier will descend too fast and may overshoot the finish line and even crash (this is akin to exploding gradient). Alternatively if the slope is not steep enough then the skier will take a long time to descend and may simply not even get to the finish line (call this vanishing gradient as there is not enough steepness in the slope to enable the skier to reach the finishing line).
Our previous attempts with Deep Learning for NLP focussed on Recurrent Neural Networks (RNNs). RNNs have a tendency to suffer from vanishing gradients when the sentence gets very long.
Exploding Gradient is eloquently explained by Jason Browlee in A Gentle Introduction to Exploding Gradients in Neural Networks
"An error gradient is the direction and magnitude calculated during the training of a neural network that is used to update the network weights in the right direction and by the right amount."
"In deep networks or recurrent neural networks, error gradients can accumulate during an update and result in very large gradients. These in turn result in large updates to the network weights, and in turn, an unstable network. At an extreme, the values of weights can become so large as to overflow and result in NaN values."
Imagine a ski slope and if the skier goes on a slope that is very steep they may go too fast down the mountain slope, overshoot the finish line and crash (we can reference this scenario as exploding gradient).
Ayoosh Kathuria Intro to optimization in deep learning: Gradient Descent

Image source O'Reilly Media
For more on Gradient Descent see:
As Yitong Ren in A Step-by-Step Implementation of Gradient Descent and Backpropagation states "The process of training a neural network is to determine a set of parameters that minimize the difference between expected value and model output. This is done using gradient descent (aka backpropagation), which by definition comprises two steps: calculating gradients of the loss/error function, then updating existing parameters in response to the gradients, which is how the descent is done. This cycle is repeated until reaching the minimum of the loss function.
For an overview on Backpropagation see this video by 3Blue1Brown What is backpropagation really doing?

And also by 3Blue1Brown

And from deeplizard Vanishing & Exploding Gradient explained:
As Arun Mohan explains in Vanishing gradient and exploding gradient in Neural networks stating that "Generally, adding more hidden layers will make the network able to learn more complex arbitrary functions, and thus do a better job in predicting future outcomes. This is where Deep Learning is making a big difference."
"Now during back-propagation i.e moving backward in the Network and calculating gradients, it tends to get smaller and smaller as we keep on moving backward in the Network. This means that the neurons in the Earlier layers learn very slowly as compared to the neurons in the later layers in the Hierarchy. The Earlier layers in the network are slowest to train.This is an issue with deep neural networks with large number of hidden layers. Ie, We know updated weight"
W_new = W_old — η gradient
"For earlier layers this gradient will be very small. So there will be no significant difference between W_new and W_old."
Transformer Neural Network vs LSTM
Long Short Term Memory Cells (LSTMs) were proposed by Sepp Hochreiter and Jürgen Schmidhuber in the period 1995-1997: By introducing Constant Error Carousel (CEC) units, LSTM deals with the vanishing gradient problem. The initial version of the LSTM block included cells, input and output gates. It was a remarkable architecture for its time.
In a more simplistic explanation the LSTM solves for the vanishing gradient problem by using a forget gate and hence could identify what information was deemed important and what to forget. For years they were viewed as state of the art for Time Series and NLP in Deep Learning. However, the rise of the Transformer with Self-Attention has yielded superior results in NLP. It's possible that in the future an amended version of the LSTM may arise again but at this moment in time and for the foreseeable future the Transformers with Self-Attention have been dominating the NLP / NLU space.
For more information see Jae Duk Seo LSTM is dead. Long Live Transformers!
See the following video by Seattle Applied Deep Learning

And Eugenio Culurciello The fall of RNN / LSTM who states that "...the LSTM and GRU and derivatives are able to learn a lot of longer term information, but they can remember sequences of 100s, not 1000s or 10,000s or more."
A great summary is provided by Thomas Wood in Transformer Neural Network:
"LSTMs are a special kind of RNN which has been very successful for a variety of problems such as speech recognition, translation, image captioning, text classification and more. They were explicitly designed to deal with the long-term dependency problem."
"The elaborate gated design of the LSTM partly solves the long-term dependency problem. However the LSTM, being a recurrent design, must still be trained and executed sequentially. This means that dependencies can flow from left to right, rather than in both directions as in the case of the transformer's attention mechanism. Furthermore, its recurrent design still makes it hard to use parallel computing and this means that LSTMs are very slow to train."
"Before the development of the transformer architecture, many researchers added attention mechanisms to LSTMs, which improved performance over the basic LSTM design. The transformer neural network was born from the discovery that the recurrent design, with sequential word input, was no longer necessary, and the attention mechanism alone could deliver improved accuracy. This paved the way for the parallel design of the transformer which enables training on high performance devices such as GPUs."
LSTM was an awesome architecture and ahead of its time. Now we are in the era of Transformers with Self-Attention and a new chapter is currently being charted in the evolution of where we are going in the field of NLP and AI in general.
Leave your comments
Post comment as a guest