Douglas Adams’ A Hitchhiker’s Guide to the Galaxy, a giant computer called Deep Thought, having spent exactly 7.5 million years pondering on Life, the Universe and Everything finally and solemnly announces that the Ultimate Answer is . . . “42”.
If only life were that simple.
Yet at the turn of the century, a math wizard and (at the time) potential Nobel laureate, David Li, had attempted to model complex financial instruments using an elegant and simple formula to create the financial market’s equivalent of “42” to disastrous consequences.
Li had taken one of the toughest nuts to crack in finance — the determination of correlation — how seemingly disparate events can be related — and appeared to have cracked it wide open with a simple and elegant mathematical formula.
Arthur had taken hitchhiking to another dimension.
Silver Bullets Only Work on Werewolves
For almost half a decade, Li’s formula, known as the Gaussian copula function, looked like the silver bullet for hugely complex risks to be modeled with more ease and accuracy than ever before.
And because risk could be more accurately modeled, it made it possible for profit-hungry traders to create and sell vast quantities of new securities, expanding financial markets to unfathomable levels.
From bond investors to Wall Street banks, ratings agencies to regulators, Li’s Gaussian copula function was the financial world’s equivalent of Einstein’s Theory of Relativity.
The moment Ben realized that he forgot to save his work.
And because Li’s Gaussian copula function was making so many people so much money, warnings about its limitations, even by Li himself, went largely ignored.
To understand Li’s Gaussian copula function, we first need to understand the mathematics of correlation better.
Let’s consider a simple example of a kid in elementary school named Alice.
The probability that Alice’s parents get divorced this year is about 5%, the risk of her getting head lice is about 5%, the chance of her seeing her teacher fall down in class is about 5% and the likelihood of her winning the class spelling be is about 5%.
If investors were trading securities based on the chances of any of those things happening only to Alice, they would all trade at more or less the same price.
But something important happens when we start looking at two kids instead of one — not just Alice, but also the kid she sits next to in class, Betty.
If Betty’s parents get divorced, what are the chances that Alice’s parents will get divorced — still about 5% — unless Alice’s parents swapped spouses with Betty’s — the correlation of these two events is zero.
But if Betty gets head lice, considering her physical proximity to Alice in school, the chances of Alice getting head lice will shoot up as well, to something around 50% — which puts the correlation of these two events in the 0.5 range.
What if Betty sees her teacher slip and fall? What are the odds that Alice would have seen that as well? Since the two girls sit next to each other in class, it could be as much as 95% or a correlation of close to 1 (or near perfect correlation).
And what if Betty wins the class spelling bee? What are the chances of Alice winning it? Zero. Because only one person can win the class spelling bee (a classic zero-sum game) the correlation is -1. If Betty wins, there’s no possibility of Alice winning.
So if investors were trading securities based on the chances of any of these things happening to both Alice and Betty, the prices of these securities would be all over the place because the correlations vary so much.
But measuring correlation is a very inexact science.
Even in this simple example, just measuring those initial 5% probabilities involves collecting lots of disparate data points and subjecting them to all manner of statistical and error analysis.
Trying to assess the conditional probabilities — the chance that Alice will get head lice if Betty gets head lice — is an order of magnitude harder since those data points are much rarer.
And as a result of the scarcity of historical data, errors in the calculation of those probabilities is likely to be amplified.
Yet ever since two Scottish ministers in the 18th century, Robert Wallace and Alexander Webster, had somehow managed to combine hard math and hard drinking, to calculate with astonishing precision, the number of orphans and widows the world’s first insurance fund would have to cater for, there has been a long held belief among statisticians that given sufficient data, anyprobability can be calculated and catered for.
But the devil is always in the data.
Bad Data Results in Bad Outcomes
And good data is hard to come by. Which is why in 2000, when Li, while working at JPMorgan Chase, published a paper in The Journal of Fixed Income titled, “On default correlation: a copula function approach,” it was lapped up immediately by the financial world.
Li came up with an ingenious way to model default correlation without even looking at historical data.
In statistics, a copula is nothing more than a measurement of the extent to which two or more variables “couple” or act in sync.
The magic in Li’s formula is that instead of looking at historical data of mortgage defaults, which is a highly disparate and complex dataset, he used market data about the prices of instruments known as credit default swaps, to substitute for the need to measure probabilities accurately.
If you’re an investor you have the choice to either lend directly to borrowers or sell to other investors credit default swaps — which are essentially insurance contracts against those same borrowers defaulting —but either way, if the borrower defaults, the investor stands to lose a lot of money.
The returns on both strategies are nearly identical — you’re using different instruments to bet on the exact same thing. It’s like piggybacking on someone else’s wager at a casino, as opposed to making the bet on your own.
But because an unlimited number of credit default swaps (CDSs) can be sold against each borrower, the supply of swaps isn’t constrained the way the supply of bonds is, which allowed the market for CDSs to grow very rapidly.
When the price of a CDS goes up, Li’s formula suggested that the default risk for that borrower increased. Li’s breakthrough was that instead of waiting to assemble enough historical data about actual defaults, which are rare in the real world, he used historical prices from the CDS market.
And although it’s hard to build a historical model to predict Alice’s or Betty’s behavior, anybody could see whether the price of CDSs on Betty tended to move in the same direction with those of Alice and if they did, then it could be interpreted that there was a strong correlation between Alice’s and Betty’s default risks, as priced by the market.
And therein lies the fatal assumption in Li’s Gaussian copula function — that correlation and causation are one and the same.
Li wrote a model that used price instead of real-world default data as a shortcut, implicitly assuming that financial markets in general and CDS markets in particular can price default risk correctly — a hugely fatal assumption that was plonked into this formula:
Cp represents the copula probability that two members of a pool, in this case uand v will both default. It’s the key that investors were looking for when deciding whether to purchase a CDS and the rest of the formula provides the answer.
But because Cp results in a single number, errors here are massively exaggerated — this is the quant’s magic “42.”
The other parts of the equation relate to survival times — the amount of time between now and when u or v can be expected to default. Li took the idea from a concept in actuarial science, the stuff of Wallace and Webster that charts what happens to someone’s life expectancy when their spouse dies.
But their application to the pricing of securities such as CDSs was grossly misappropriated.
While it is true that no one can predict the exact time of death of any individual, actuaries can calculate the likely life expectancy of a large group of individuals with quite astonishing precision. CDSs are on an entirely different level altogether.
Li’s Gaussian copula function was attempting not to do the latter, but the former, to assign a value for the precise time of death of a CDS. And because there was so little data to base such probabilities on, small miscalculations would leave investors facing much more risk than Li’s formula would have suggested.
It was a brilliant simplification of an otherwise intractable problem.
Instead of working with complex correlations and trying to calculate the nearly infinite correlations between the various loans that made up a pool in a CDS, Li’s function just concerned itself with one clean, simple, all-powerful figure that sums up everything.
The financial world’s equivalent of the number 42.
Yet despite the benefit of hindsight which demonstrated how fatally flawed Li’s Gaussian copula function was in the pricing of CDSs and other collateralized debt obligations (CDOs), this same financial alchemy has started to seep into the cryptocurrency markets.
Copula for Cryptocurrencies
Take Bitcoin and Ethereum for instance, the world’s top two cryptocurrencies by market cap.
Not too long ago, Ripple, the world’s third largest cryptocurrency had pipped Ethereum for the second spot, a position that it held for a few months.
During this period of time, some traders, using Li’s very own Gaussian copula function had calculated that Ethereum was mispriced given its correlation with Bitcoin and its tendency to move in lockstep with the bellwether cryptocurrency.
Benjamin Franklin was unimpressed by your attempts at default correlation.
Snapping up Ethereum, they were eventually proved right — the price of Ethereum eventually rose at a much faster rate compared to the price of Ripple and “balance” was restored to the cryptoverse.
Cryptocurrency traders argued that given the strong correlation between the price of Bitcoin and Ethereum, the market had mispriced Ethereum (inefficiency) providing a trading opportunity — suggesting that Li’s Gaussian copula function works.
But therein lies the dilemma of making such an assumption — correlation implies causation.
What if the mere fact that traders who had noticed that Ethereum was not trading at its typical price gap with Bitcoin had then influenced the price of Ethereum to rise by snapping it up, bringing its price back in lockstep with Bitcoin’s?
What if the action of the observer is what resulted in the conditions which were eventually observed?
It doesn’t mean that Li’s formula worked in cryptocurrency trading and to take the view that it had, is a very dangerous one.
Li’s approach made no allowance for unpredictability — black swan events — and assumed that correlation was a constant, when really, it’s a far more mercurial concept.
Paul Wilmott, a quantitative finance consultant and lecturer argued that no theory should be built on such unpredictable parameters.
“The relationship between two assets can never be captured by a single scalar quantity.”
Yet in the cryptocurrency markets that seems to be precisely what is happening.
Observe the trading pairs on some of the top cryptocurrency exchanges and you’ll soon notice that the price movements of the two digital assets seem to move in lockstep.
And any time there’s deviation from the mean, trade behavior sweeps in to restore that default correlation, which suggests that many traders are using formulas like Li’s Gaussian copula function to determine correlation and to make trades whenever the two cryptocurrencies deviate from their calculated correlations.
But if the financial world, couldn’t be mapped with a simple elegant correlation formula, what more cryptocurrencies which suffer from both limited data and are unconstrained?
Yet it is precisely because formulaic behavior has been demonstrated in cryptocurrency markets that makes them such a tempting proposition for quants who have noticed the space as a target-rich environment.
Given the abundance of automated trading algorithms, running on preset formulas including Li’s flawed Gaussian copula function, it’s no wonder that quant traders who have found it increasingly difficult to generate alpha in the traditional financial markets have been trying their hand in the cryptosphere.
But as the financial markets have demonstrated, reliance on such elegant and beautiful formulas alone is a recipe for disaster.
To be sure, across extremely short timeframes, there may be sufficient correlation between almost anything and given the dearth of data, anything could be correlated with anything else.
If quantitative theories alone were applied to cryptocurrency markets, last year’s Bitcoin Cash war would have caught traders unawares. Yet to anyone in tune with developments in the cryptocurrency world, the tensions and inevitable aftermath of the Bitcoin Cash war had been brewing for months prior to the outbreak of war.
Which is why the cryptocurrency markets are in many respects the ultimate test bed for quantitative theories.
Consider Austrian physicist Erwin Schrödinger’s 1935 thought experiment which postulated that if you placed a cat and something that could kill the cat (a radioactive atom) in a box and sealed it, you would not know if the cat was dead or alive until you opened the box. So that until the box was opened, the cat was (in a sense) both “dead and alive” — the question was then raised whether your act of observation in and of itself had an effect on the outcome.
Similarly, the haphazard use of quantitative formulas derived from the financial markets in cryptocurrency trading begs the question whether the use of such equations themselves causes markets to conform to these formulas or whether the markets confirm the efficacy of the formulas themselves.
The Gov is scared of the Bull run they saw bitcoin and litecoin getting ready to moon so they had to come up with something to buy some time to come up with b.s laws and taxes smh that is what that is all about
Patrick is an innovative entrepreneur and a lawyer passionate about cryptocurrencies and the business world. He is the CEO of Novum Global Technologies, a cryptocurrency quantitative trading firm. He understands the business concerns of founders and business people helping them to utilise the legal framework to structure their companies to take advantage of emerging technologies such as the blockchain in order to reach greater heights. His passion for travel, marketing and brand building has led him across careers and continents. He read law at the National University of Singapore and graduated with Honors in the Upper Division and joined one of Singapore’s top law firms, Allen & Gledhill where he was called to the Singapore Bar as an Advocate & Solicitor in 2005. He created Purer Skin, a skincare and inner beauty company which melds the traditional wisdom of ancient Asian ingredients such as Bird's Nest with modern technology. In 2010, his partner and himself successfully raised $589,000 from the National Research Foundation of Singapore under the Prime Minister’s Office. He has played a key role in the growth of Purer Skin from 11 retail points in Singapore to over 755 retail points in Singapore and 2 overseas in less than a year. He taught himself graphic design, coding, website design and video editing to create the Purer Skin brand and finished his training at a leading Digital Media Company.



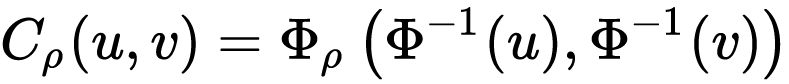


Leave your comments
Post comment as a guest