Comments
- No comments found

The use of deep learning in drug discovery is leading to more accurate results, lower time and innovative discoveries.
Worldwide research efforts have focused on using deep learning on various medical data of COVID-19–positive patients in order to identify various aspects of the disease, with promising reported results.
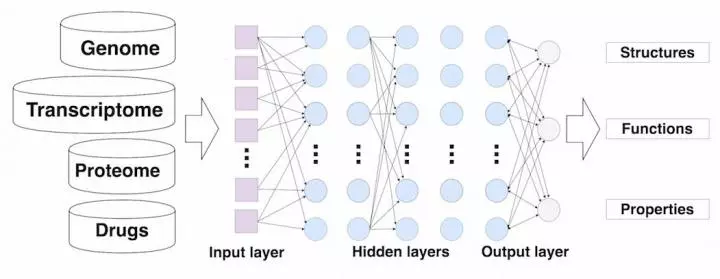
Recent studies have increasingly employed computational methods to systematically predict new drug targets or drug repurposing candidates.
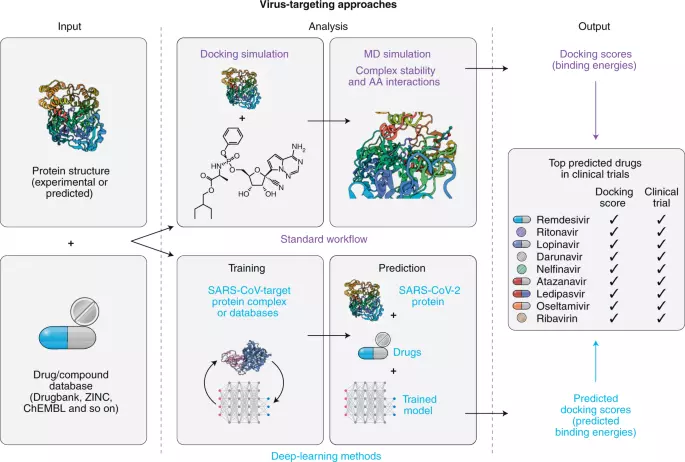
Source: Nature Scientific Journal
According to Pfizer, preliminary laboratory studies demonstrate that three doses of the Pfizer-BioNTech COVID-19 Vaccine neutralize the Omicron variant (B.1.1.529 lineage) while two doses show significantly reduced neutralization titers.
Although two doses of the vaccine may still offer protection against severe disease caused by the Omicron strain, it’s clear from these preliminary data that protection is improved with a third dose of our vaccine.
Albert Bourla, Chairman and Chief Executive Officer, Pfizer.
Almost everyone knows the famous discoverer of the world’s first antibiotic, penicillin - Dr. Alexander Fleming. What fewer people would know is that the discovery of the anti-bacterial drug was a result - not originate from deliberate research and testing (well, not exactly) - but from some accident. The story goes, that upon opening his lab after a long time, bacteriologist Dr. Fleming found his Petri dishes containing Staphylococcus aureus (a kind of bacteria that causes infections and diseases like pneumonia), covered with a layer of penicillium mold (a type of fungus). Upon close examination using a microscope, he found that the mold somehow was able to inhibit the development of the bacteria. By further testing and investigating the mold and its action on bacteria, he was able to confirm the antibacterial property of Penicillium. It was then later discovered by researchers at Oxford University that the agent that actually killed the bacteria was a molecule named penicillin, which is the antibiotic we all know to save millions of lives. However, the time between Dr. Fleming's stumbling upon penicillium's antibacterial property in 1928, the testing and recognition of penicillin as an effective antibiotic, and ultimately its mass production and use for treatment was nearly 15 years. In that period, countless people lost their lives to bacterial infections, which could possibly have been prevented had the process been a little faster. Although fortunately, the process of drug discovery is not as long nowadays, it still takes a while for medicinal chemicals to be identified, tested, approved, produced, and used for treatment. Additionally, organizations that invest by in medical research also incur heavy costs. Read on to know how the use of modern technology like artificial intelligence and deep learning in drug discovery can streamline the process to help find cures for potentially terminal illnesses faster.
Drug discovery is becoming an increasingly deliberate, strictly regulated, and analytically demanding process. Following are the steps in which drugs generally go from discovery to mass application:
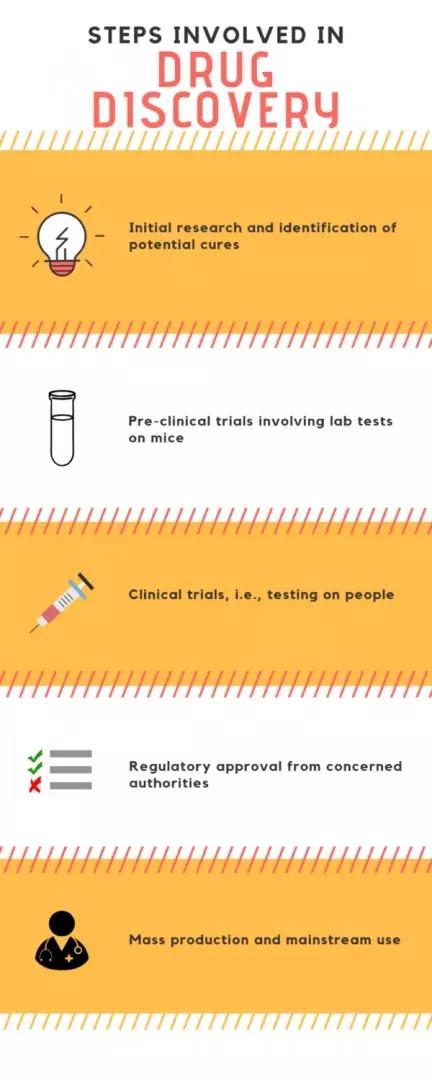
The process of discovering a cure begins with exploring a number of potential medicinal ‘candidates’ for curing the condition. This is usually the most time-consuming part of the drug discovery process as it involves a lot of hit and miss. It involves studying the anatomy and nature of the disease and its causative agent (i.e., bacteria, virus, fungus, etc). Then it involves checking for existing records of the results of previously conducted tests, to find any compounds that can have the desirable remedial effect on the target pathogens. Potential cures are hypothesized followed by extensive cause-effect testing. This is done using a process called high-throughput screening (testing the effect of a large number of chemicals on the target). This phase also involves evaluating various criteria such as affinity towards the target agent, the selectivity (the non-reactivity with other compounds), the effectiveness in dealing with the target a pathogen, and the half-life of the medicine. These criteria are tested to know if the given chemical will have a therapeutic effect on the target, whether it will cause any side-effects by reacting with other compounds, and if it is suitable for oral consumption.
This is a highly expensive and time-consuming stage, and the probability of getting the right cure is considerably low.
Since medicines cannot be directly tested with humans, they are subjected to a round of stringent preclinical trials. This includes various rounds of in vitro (on cell cultures) and in vivo (on mice) testing to determine the efficacy and side effects of the potential therapeutic.
Drugs that pass the preclinical trials are considered for clinical trials, i.e., testing on human subjects. This stage of the drug development process involves multiple phases. The first phase involves testing in healthy human subjects to test for safety of the chemical. The next one involves testing on a slightly larger group of patients. This test mainly focuses on evaluating the efficacy of potency of the chemical on interfering with the pathogens, which often includes testing for the placebo effect, by comparing the effects of the chemical with a placebo drug. Then the chemical is tested on a large number of patients, and multiple other factors are considered and examined to fully understand the effects of different factors such as patient habits on the chemical and its effect on the target.
The findings of the clinical trials on large enough sample sizes of patients upon presentation to and verification by regulatory bodies, such as the Food and Drug Association (FDA) in America, that verify the success in clinical trials and approve drugs.
Once the drugs are approved by regulators, the corporation who funded the research can get a patent for the drug to manufacture it on a commercial scale and make it available to the general public.

Artificial intelligence can be used to cut down on the time spent on drug discovery using its ability to analyze large volumes of medical data to identify patterns and connections with greater efficacy than humans. Since a major part of the initial drug discovery tests is based on trial and error, deep learning algorithms can be used to simulate and accurately study the effects of various chemicals on the target be pathogen, through virtual high-throughput screening (HTS on a computer system). Training algorithms with extensive libraries of chemicals can help in forming hypotheses that are more likely to lead to effective therapeutic solutions than those formed by humans. Deep learning and AI, in addition to analyzing larger amounts of data, can also help in recording the results of studies in an early verifiable manner, thereby saving a lot of time and cutting down on considerable effort and room for error in the process.
Machine and deep learning also help in lead optimization, where the successfully identified chemicals from the initial screening are further explored using regression (mathematical models used to study and establish the relationship between variables, in this case, the potential cure and the target) models known as Quantitative structure-activity regression (QSAR) models. In this step, the chemical structure of identified molecules is altered to improve the efficacy and safety of the drug while minimizing the potential side-effects. Since this process, again, involves a lot of repetitions and trial and error, using a machine learning algorithm can be incredibly useful in performing the reiterative tests and finding hits quickly.
However, although the use of deep learning can be highly beneficial in the initial stages of drug discovery, it cannot be used beyond the hypothesizing phase since there can be no substitute for clinical trials. Regardless, the contribution of machine and deep learning in healthcare, not just drug discovery by helping in saving not just time and money, but also human lives.
Naveen is the Founder and CEO of Allerin, a software solutions provider that delivers innovative and agile solutions that enable to automate, inspire and impress. He is a seasoned professional with more than 20 years of experience, with extensive experience in customizing open source products for cost optimizations of large scale IT deployment. He is currently working on Internet of Things solutions with Big Data Analytics. Naveen completed his programming qualifications in various Indian institutes.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest