Comments
- No comments found
We live in an Age of Actualisation for Natural Language Programming (NLP) and especially transformer-based Large Language Models (LLMs).
Firstly, NLP models are on the rise, advancing a fascinating field of AI with applications to shape the very future of human lives, tackling an array of tasks including conversation, text completion, and even coding. This has been fuelled by advances in accuracy, scalability and production readiness. Indeed, research conducted by John Snow Labs last year revealed that 60% of tech leaders indicated their NLP budgets grew by at least 10% compared to 2020, with a rel="nofollow" third (33%) reflecting a rise of at least 30%.
Special attention has been afforded to LLMs for their key role in re-imagining two key branches of AI: language and vision, with NVIDIA's NeMo Megatron a superb example, providing an end-to-end framework from data curation, through to training, inference and evaluation. LLMs are trained on huge amounts of data and enable learning from text with applications across text summarization, real-time content generation, customer service chatbots and question-answering for conversational AI interfaces as summarised below:
1) Summarization and Paraphrasing (or a better way to say)
- Real World Examples: Newsletters, Web Search Engines, Media Monitoring
2) Classification (request or question)
- Real World Examples: Supply Chain Order Queries
- Banking Queries directed to Agents
3) Semantic Similarity (answered before?)
- Real World Examples: Credit Scoring, Clinical Trial Matching,
- Modular FAQs Scoring Helplines
The size and complexity of LLM-'s continues to accelerate. Traditionally training a large language model could be compared to the sport of bodybuilding - you need to eat an awful lot (big data) plus work out a lot (large model)! Indeed Deep Learning is more dependent on computing power than many other areas because models have more parameters than data points. Other pain points in developing LLM’s include time, expense, level of deep technical expertise, distributed infrastructure and the need for a full-stack approach. But these challenges are being addressed head on with NVIDIA's NeMo Megatron upgraded to help train LLMs more efficiently, making them more powerful and more applicable in a range of different scenarios. Let’s explore all the key developments!
Reflecting back on the pioneering research paper "Attention is all you need’, the scale, speed and trajectory of innovation is clear with NVIDIA now established as a leading and indeed pioneering contributor in the AI field. As someone who has worked in research development myself, most recently as a Principal Investigator on the Digital Transformation ‘Breakthrough’ Study, I have experienced first-hand the challenge of training LLMs on vast datasets on supercomputers, which can take weeks, and sometimes even months. So what if we could speed up training by up to 30% - or by around ten days development time?
Updates to NeMo Megatron by NVIDIA are allowing exactly that! – with the ability to distribute training on as many GPUs as you want, reducing both the amount of memory and compute that is required for training, and making deploying the model much more accessible and significantly faster too. This translates into a 175B-parameter model being trained in 24 days instead of 34 using 1,024 NVIDIA A-100 Tensor Core GPUs.
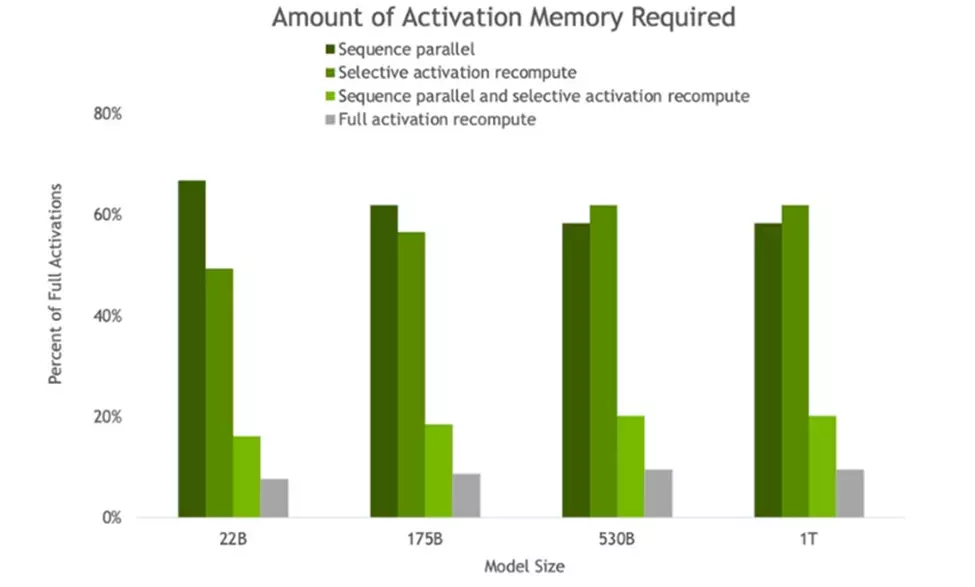
This development also offers exciting opportunities for companies to offer customised GPT-3 models ‘as a service’, for example a bespoke and sector specific LLM. I also believe this can help advance the capacity for LLM’s to interact together, the ‘cascade perspective’ described here and to better plan and reason about change through pattern recognition – an issue highlighted in further breaking research. So how has this innovation been actualised? The advance is underpinned by two technologies and the hyperparameter tool:
Reduces activation memory requirements beyond usual tensor and pipeline parallelism methods by noticing the previously non-parallelized layers of transformers and recomputing only the parts of each transformer layer that use significant memory but are easy to compute.
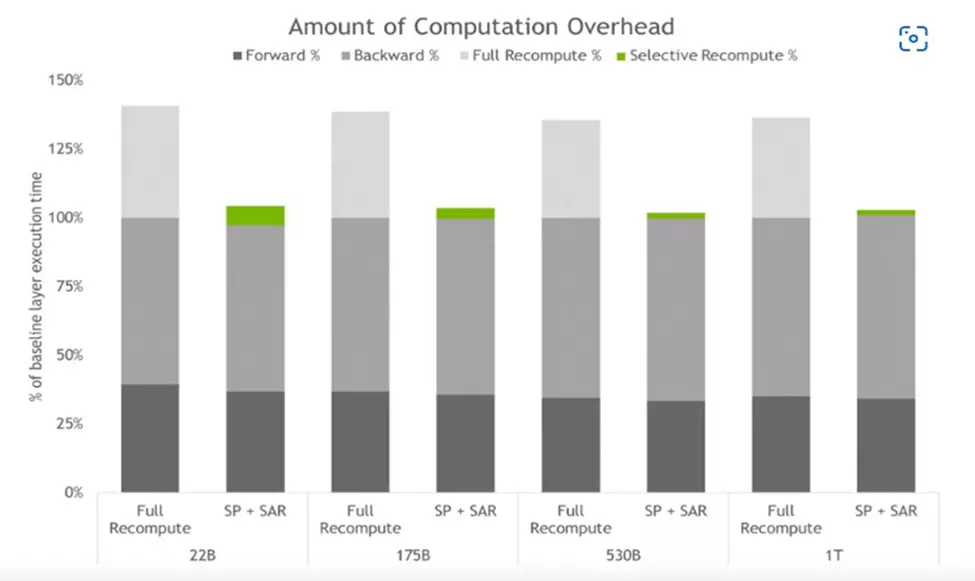
Selects activations with high-memory low-compute requirements to recompute when memory constraints are too tight, and so avoiding the inefficiency of full activation recomputation. The hyperparameter tool introduced in NeMo Megatron automatically identifies optimal training and inference configurations, allowing configurations with the highest model throughput or the lowest latency during inference, and eliminating the time taken to search for an optimal design – and all with no code changes required.
And with my personal passion for democratising access to AI, it is meaningful to note that BLOOM – which stands for BigScience Large Open-science Open-access Multilingual Language Model and is the “world’s largest open-science, open-access multilingual language model" - has been trained using Megatron-DeepSpeed. This has been supported by the work of 1,000+ volunteer researchers as part of the BigScience Project, coordinated by Hugging Face and with French government funding – and it is already enabling text generation in 46 languages and 13 programming languages! With the performance updates to Megatron now available, alongside business benefits, I hope this will also help further advance change in the culture of AI development and support democratising access to cutting-edge AI technology for researchers around the world. Exciting times indeed!
The advances to NeMo Megatron will significantly increase future calculations and results, making LLM training and inference both easier and reproducible on a wide range of GPU cluster configurations – I am excited to see all the new applications this will bring, and meanwhile the latest technical blog on all the changes can be viewed here. You can also explore early access options and freely test-drive the enterprise hands-on lab through NVIDIA too!
And as a final thought, don’t miss the chance to connect with AI developers and innovators at #GTC22 this Sept 19-22 and help to shape the future of Artificial Intelligence, Large Language Models, Computer Graphics, Accelerated Computing and more. You can register free with my unique code for a chance to win a RTX3080 Ti – just click here!
Thank you for reading – all feedback most welcomed, Sally
Prof. Sally Eaves is a highly experienced chief technology officer, professor in advanced technologies, and a Global Strategic Advisor on digital transformation specializing in the application of emergent technologies, notably AI, 5G, cloud, security, and IoT disciplines, for business and IT transformation, alongside social impact at scale.
An international keynote speaker and author, Sally was an inaugural recipient of the Frontier Technology and Social Impact award, presented at the United Nations, and has been described as the "torchbearer for ethical tech", founding Aspirational Futures to enhance inclusion, diversity, and belonging in the technology space and beyond. Sally is also the chair for the Global Cyber Trust at GFCYBER.
Dr. Sally Eaves is a highly experienced Chief Technology Officer, Professor in Advanced Technologies and a Global Strategic Advisor on Digital Transformation specialising in the application of emergent technologies, notably AI, FinTech, Blockchain & 5G disciplines, for business transformation and social impact at scale. An international Keynote Speaker and Author, Sally was an inaugural recipient of the Frontier Technology and Social Impact award, presented at the United Nations in 2018 and has been described as the ‘torchbearer for ethical tech’ founding Aspirational Futures to enhance inclusion, diversity and belonging in the technology space and beyond.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest