Comments
- No comments found

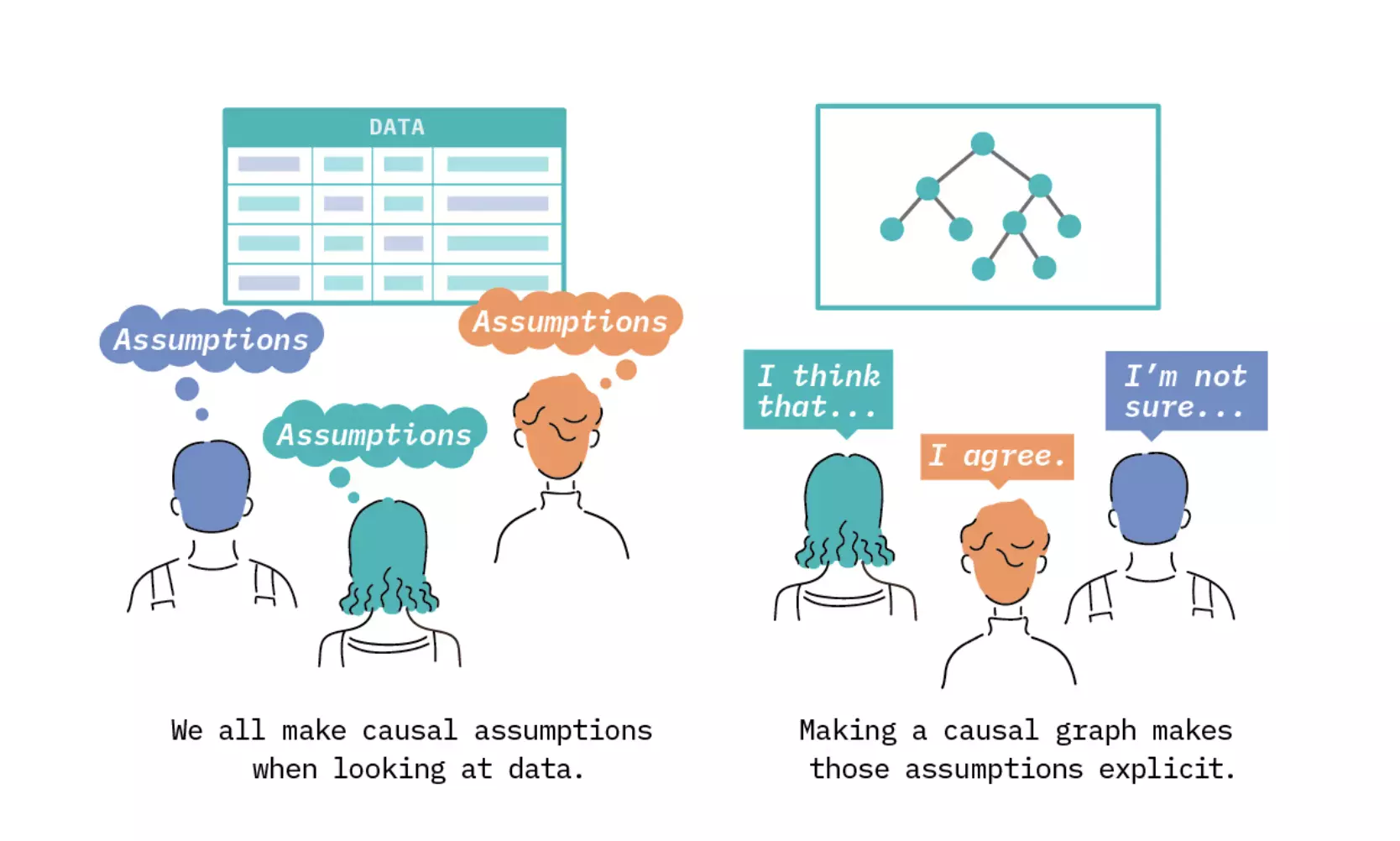
Artificial intelligence (AI) algorithms can spot patterns that humans can't.
The most advanced algorithms can't still explain what caused one object to collide with another.
Based on capabilities, artificial intelligence can be classified into three types:
Narrow AI
General AI
Super AI
The concept of AI involves other subsets such as machine learning and deep learning.
Many AI experts predict that machines may outperform humans at every task within 45 years.

Self driving cars hurtling along the highway and weaving through traffic have less understanding of what might cause an accident than children who have just learned to walk.
Driverless cars are entirely controlled by computer hardware and software. Malicious attackers could find and exploit security holes in any number of complex systems to take over a car or even cause it to crash purposefully.
Furthermore, driverless cars of the future will likely be networked in order to communicate with each other and send and receive data about other vehicles on the road. Attacks on such a network could grind all these robotic cars on the road to a halt.
The current narrow artificial intelligence systems fail to grasp rudimentary physics' cause and effect.
Artificial intelligence systems frequently ignore information that animals rely on heavily: interventions in the world, domain shifts, temporal structure – on the whole, let us consider these elements a nuisance and strive to design them away.
Deep-learning algorithms can often spot patterns in data beautifully, enabling impressive feats of image and voice recognition. But they lack other capabilities that are trivial for humans.
A lack of causal understanding can have real consequences, too. Industrial robots can increasingly sense nearby objects, in order to grasp or move them. But they don't know that hitting something will cause it to fall over or break unless they’ve been specifically programmed—and it’s impossible to predict every possible scenario.

Driving is set to change significantly in years to come © GETTY | The Telegraph
The reality of causality and the mechanism of causation are completely different than we all used to think.
If a robot could reason causally, however, it might be able to avoid problems it hasn’t been programmed to understand. The same is true for a self-driving car. It could instinctively know that if a truck were to swerve and hit a barrier, its load could spill onto the road.
Real causality is about reversibility and circularity, mutuality and reciprocity, interdependence and correlation.
Causal understanding would be useful for just about any AI system. Systems trained on medical information rather than 3-D scenes need to understand the cause of disease and the likely result of possible interventions. Causal reasoning is of growing interest to many prominent figures in AI.
True causality is an integrated relation and interactive relationship.
Bayesian and causal networks are completely identical. And the difference lies in their misinterpretations. Consider the simple example in the figures below.
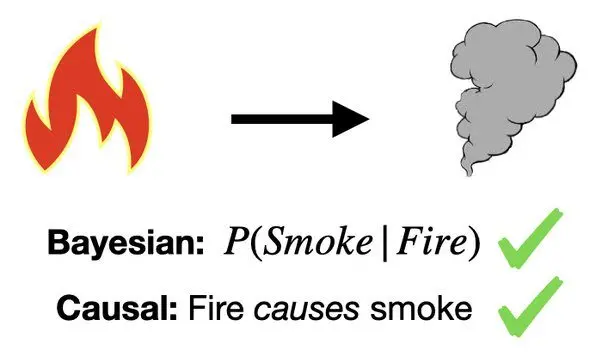
Example network that can be interpreted as both Bayesian and causal. Fire and smoke example adopted from Pearl [The Book of Why: The New Science of Cause and Effect]
Here we have a network with 2 nodes (fire icon and smoke icon) and 1 edge (arrow pointing from fire to smoke). This network can be both a Bayesian or causal network.
The key distinction, however, is when interpreting this network. For a Bayesian network, we view the nodes as variables and the arrow as a conditional probability, namely the probability of smoke given information about fire. When interpreting this as a causal network, we still view nodes as variables, however the arrow indicates a causal connection. In this case both interpretations are valid.
Now, if we were to revert the edge direction, the causal network interpretation would be still valid, regardless that smoke does not cause fire.
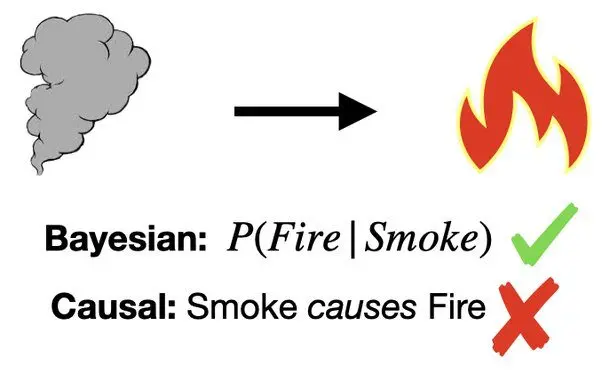
Fire is the rapid oxidation of a material (the fuel) in the exothermic chemical process of combustion, or burning, releasing heat, light, and various reaction products, including gaseous by-products, as smoke. It is commonly an unwanted by-product of fires (including stoves, candles, internal combustion engines, oil lamps, and fireplaces). Smoke is not included in the fire tetrahedron, oxygen, heat, fuel and chemical reaction. Take any of these four things away, and you will not have a fire or the fire will be extinguished.
Fire causes heat and light as much as light or heat could cause fire. Again, if the fire is a rapid oxidation of a material, there must be an inverse process of deoxidation/reduction which occurs when there is a gain of electrons or the oxidation state of an atom, molecule, or ion decreases. Or, as to the inverse causality law, if one chemical species is undergoing oxidation then another species undergoes reduction.
So, X causes Y if an intervention in X results in a change in Y, and an intervention in Y does necessarily result in a change in X.
Reverse causality enables all mathematical or physical processes, deterministic or stochastic, as time-reversible: if the dynamics of the process remain well-defined when the sequence of time-states is reversed.
Again, a statistical input-output dependence or asymmetric functional relationships of dependent and independent variables as used in mathematical modelling, statistical modelling and experimental sciences, computer science, AI and ML, should be completely reviewed or discarded.
Depending on the context, an independent or exogenous variable is called a "predictor variable", regressor, covariate, "control variable" (econometrics), "manipulated variable", "explanatory variable", exposure variable, "risk factor" (medical statistics), "feature" (in machine learning and pattern recognition) or "input variable".
A dependent endogenous variable is called a "response variable", "regressand", "criterion", "predicted variable", "measured variable", "explained variable", "experimental variable", "responding variable", "outcome variable", "output variable", "target" or "label".
Causal relationships between variables in real-world settings are much more complex and may consist of direct and indirect effects that go directly from one variable to another or when the relationship between two variables is mediated by one or more variables.
When it comes to raw computational power, machines are well on their way. And there’s no doubt that artificial intelligence will continue to make life more exciting for humans.
It's clear that the human brain is a magnificent thing that is capable of enjoying the simple pleasures of being alive. Ironically, it’s also capable of creating machines that, for better or worse, become smarter and more and more lifelike every day.
If technological progress continues its relentless advance, the world will look very different for our children and grandchildren thanks to artificial intelligence.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest