There are a huge number of uses for artificial intelligence and machine learning that are, frankly, a waste of computer cycles.
Every so often, however, I come across efforts, almost invariably born from a passion and desire to make a difference rather than the imperative of making a profit, that helps to showcase the best of humanity and how this technology can improve lives.
When Computers Talk
One of the most recognizable symbols of Covid-19 is the intubation tube - a tube that goes down the mouth or through a tracheotomy incision in order to supply air to the lungs from a ventilator. When this happens, the ability to speak ends. Around the world, there are 500 million people who, for one reason or another, cannot speak, or cannot speak well. Stroke victims make up a significant portion of this, but throat cancer survivors, people who are severely autistic, those with amyotrophic lateral sclerosis (ALS), accident victims, and those with congenital muteness are also unable to speak. Sometimes this is due to the vocal tract itself, sometimes it is due to cognitive dysfunction, but it's always frustrating, especially because, without the ability to speak, many, many people become unable to function in our language-oriented society.
Synthetic voice generation (also called text-to-speech, or TTS) has advanced dramatically since the technology first emerged in the 1980s. Initially, the voices generated were very robotic sounding, with neither inflection nor tonal variation. Over the years, advances in linguistic understanding, greater processing power and the advent of machine learning have made voices sound human enough that they can be nearly indistinguishable from live speakers in many different languages, though the robotic voice is still a favorite.
The late Stephen Hawking, who suffered from and ultimately succumbed to ALS) made use of a robotic voice TTL to communicate, developed by Intel. When Gordon Moore, then CEO of Intel and who helped Dr. Hawking with the original system, offered to upgrade it, Hawking turned him down - it was HIS voice.
Today, TTS is ubiquitous. Google Text To Speech, Amazon's Polly, and Microsoft Azure Text To Speech (among others) all provide APIs for converting straight text to speech, but also provide support for the Speech Synthesis Markup Language (SSML), a W3C based standard for adding "hints" into your content to set preferred voices, speeds and even color and style. Additionally most smartphones (and all digital assistance) today incorporate specific language packs that control how your phone "speaks" to you, such as when using car GPS navigator applications.
Most automated phone systems make extensive use of both SSML and speech to text. If you've ever been in voicemail hell, it's likely because you've encountered an SSML-based system that was poorly designed.
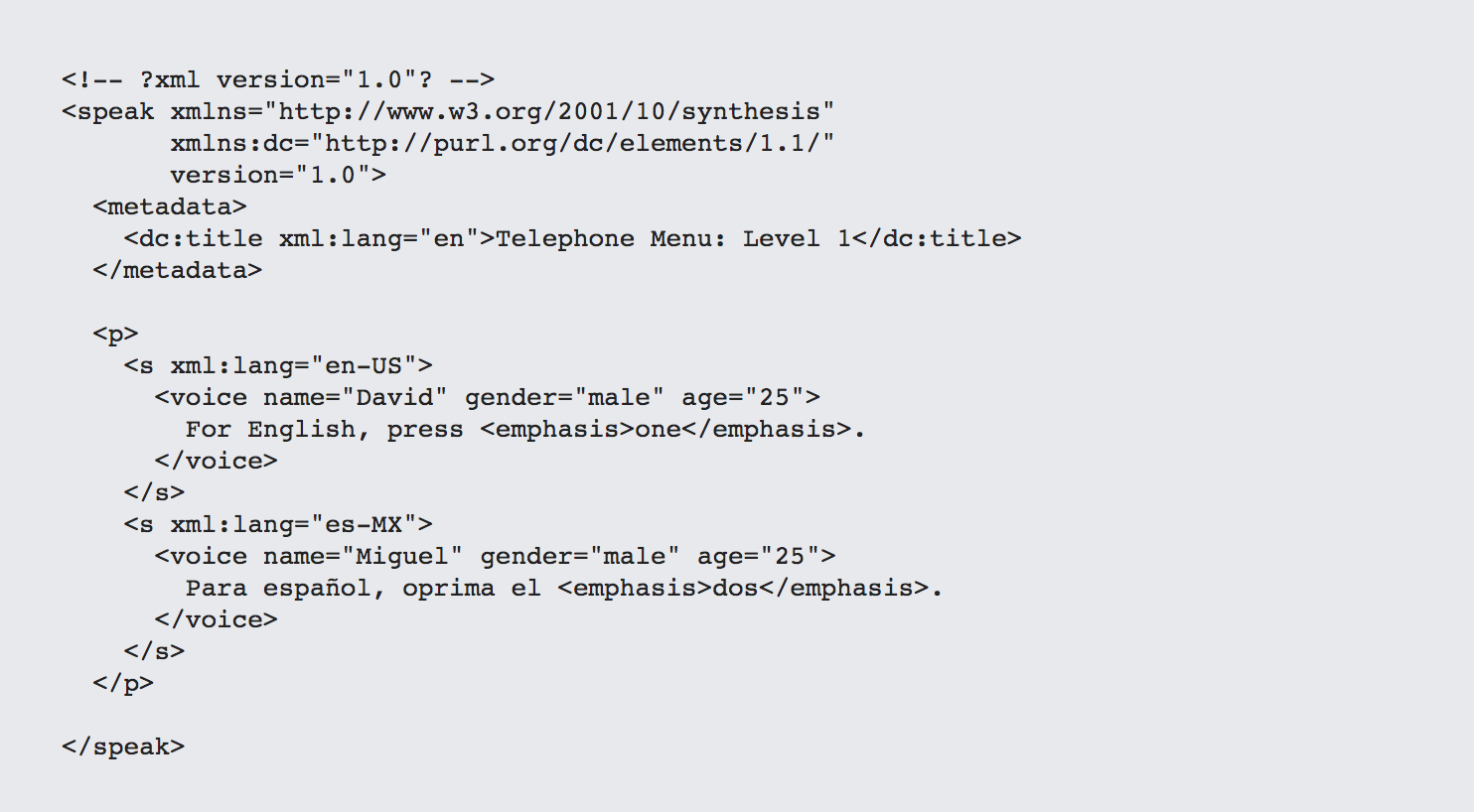
Additionally, the Speech Recognition Grammar Specification (SSRG) and the Semantic Interpretation for Speech Recognition (SISR) provide a foundation for creating declarative XML scripts that support both speech recognition in automated systems and the generation of automated responses based upon conditional rules. Such rule-based systems are also increasingly being complemented with machine learning systems that determine, based upon word usage patterns, the intent necessary to execute such rules.
Intentional Design
However, Hawking's plight explains why text-to-speech by itself is not enough. ALS is a progressive disease, a wasting away of the nerves that often makes it much harder to type, or eventually to control any motion within the body. Stroke victims may be unable to perform the neurological tasks involved in speech, and also may face daunting challenges with paralysis. Even people with severe autism or Down's syndrome struggle with the complexity of dealing with keyboard interfaces
Cognixion is a Canadian-Amerian company based out of both Santa Barbara, CA and Toronta, Canada, set up in part due to the recognition that, as good as TTS and similar technologies are, they have to move beyond the keyboard if these technologies are going to help those who can no longer speak.
For those who do have keyboard mobility, Cognixion offers a smartphone app called SpeakProse that can act as a vocoder - providing speech, but also incorporating machine learning algorithms to do speech predictive analysis - determining, based upon your own word usage via reinforcement learning, what you're likely to want to say. It provides a significant "talk ahead" capability that can dramatically reduce the overall need for typing by a factor of ten.
These kinds of capabilities were jump-started by the publishing of BERT in a set of Google research papers in 2018. BERT is a natural language processing (NLP) algorithm that applies a combination of statistical modeling and neural network models applied to a corpus of text. A good explanation for how BERT works is here. Most significant NLP algorithms since then have built on BERT as a foundation.
Similar systems are making their way into general editing applications as well - a design factor process becoming more common known as intentional design. In this case, intentional design focuses on reducing the friction of interface interaction by predictively modeling the most likely actions that a person will make and then providing the means to act on them as easily as possible. For most people, such intentional design is a "nice to have" - it can make writing faster and easier. For many of Cognixion's beneficiaries, it can spell the difference between communicating with the outside world and not.
Towards Augmented Reality
Augmented Reality (AR, and yes, there are a lot of acronyms here) is becoming another critical vector for communication. Increasingly, AR interfaces (such as goggles and haptic connectors that sense electric current due to specific muscle activation) coupled with intentional design are used to retrieve contextual feedback - where a person is, visualizations of what's around them, what their orientation is in space, how fast they are moving and so forth. Based upon this information most augmented reality then retrieve specific metadata that is relevant to what is perceived.
Currently, many such AR systems are closed - they handle metadata in different ways, and they usually tend not to share information with other providers in part because there are no established protocols that allow for the transparent sharing of such data. This is an area where I believe a second organization may come into play,and illustrates how so much of what is going on now involves coordination between many different players - the Spatial Web Foundation.
The idea behind the Spatial Web is that it is (surprise!) a web for interacting with things in space and time. More to the point, the Spatial Web foundation is attempting to do what the W3C has done for the World Wide Web - establish a set of standards and protocols that developers can use to describe where things are in a consistent fashion. It is vaguely possible now to get a very rough sense of location-based upon device communication (sensor logs from cell phones, routers and Internet-enabled vehicles) but there's no consistent way to be able to attach metadata to geometries. The goal of the spatial web is to enable that layer.
I'll be covering the Spatial Web in more detail in a subsequent post, but I wanted here to point out how this connects with organizations like Cognixion. Three dimensions are considerably more complex to deal with than two, and four dimensions (3 + time) are even more difficult to deal with. In augmented space, you are typically dealing with both triggers that initiate actions when a person enters into a particular spatial perimeter, and level of detail (LOD) such that when you do get within a trigger, the amount of information relative to the object associated with that trigger increases, sometimes dramatically.
Game developers understand this implicitly - it's a way of both cutting down on the amount of bandwidth needed and of keeping the player from going crazy due to too much information. In many respects virtual reality is actually much simpler because it's usually a closed system. AR, augmented reality, is more complex, as you're sharing the information space with everyone else on the planet, or at least everyone with the proper access keys, and to do that you have to have an agreement on language and description about how you describe the world and the things in it in a consistent fashion.
Once you have this ability to generate triggers, you can get state and from that compute context. Once you have context, this gives textual analytics significant tools for knowing what the environment is like around the person in question, making it possible to put things into graph templates, which can be thought of as patterns for certain triggers based upon the general conceptual shape of the entities within your contextual space, e.g., "Could you please get me that red jacket over there?" In a closed environment, this is (comparatively) easy to do. In an open, shared environment, this simple request is far harder to formulate.
Beyond the smartphone app, Cognixion has one other application - AR glasses/goggles that allow you to navigate as above (and provide context) by tracking eye movements in parallax coupled with a brain-controlled-interface (BCI): a neural mesh or cap with sensors capable of reading brain waves and use them to trigger communications. This isn't quite telepathy, more a very specialized application of deep learning in which intent is determined by particular signals that can be mapped (if a person can otherwise communicate) to the relevant triggers. Such meshes have been around for a while, even in modern media (think the Neural Transmitter in Disney's Big Hero Six movie and series), but using them as a means to facilitate human to human communication is intriguing, to say the least.
Summary
The upshot of this is that we're now seeing the emergence of a stack of technologies that have immediate ramifications as cognitive prosthetics, but that are also increasingly finding use in other technologies. AR + Semantic Context => intelligent environments. TTS + Avatars => intelligent agents. IoT + the Spatial Web => true telepresence. The list goes on and on. What's more, it also means that people who formerly were left to regress as they became more and more separated from society can increasingly become contributing members again.




Leave your comments
Post comment as a guest