Comments
- No comments found

ChatGPT has quickly gained millions of people's attention, but many are wary because they don't get how it works.
This is understandable, and this month's edition is about trying to break it down, so it's easier to understand. However, at its core, ChatGPT is a massively complex system, so there's only so much simplification I can help with!
If you still need to play with ChatGPT or don't know what it is, the core interface is a chat window where you can ask questions or provide queries, to which the AI responds. An important detail to remember is that within a chat, context is retained, meaning that messages can refer to previous messages, and ChatGPT will be able to understand that contextually.
What happens when you hit enter on that query in the chat box?
Let's first start with a step back. There is a lot to uncover under ChatGPT's hood. Machine learning has been rapidly advancing in the past 10 years, and ChatGPT leverages a number of the state of the art techniques to achieve its results.
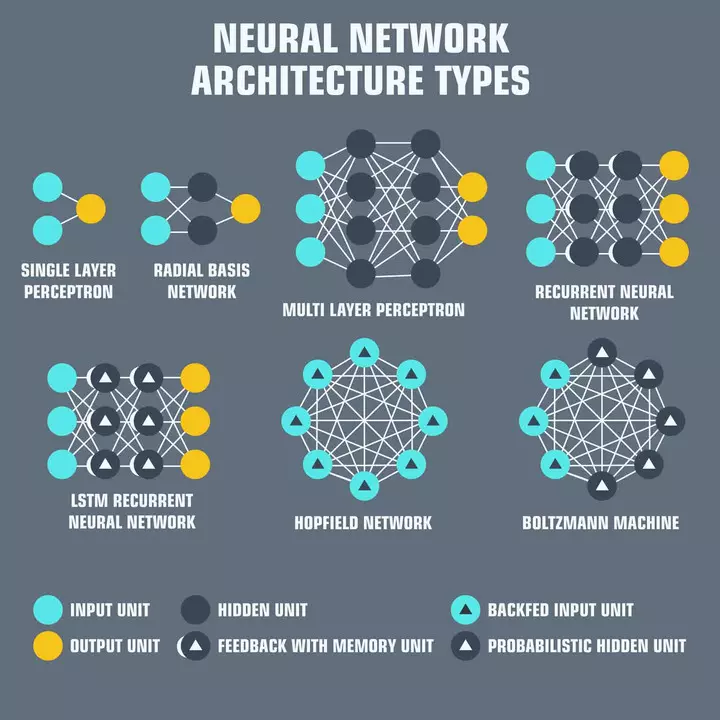
Neural networks are layers of interconnected "neurons," each responsible for receiving input, processing it, and passing it along to the next neuron in the network. Neural networks form the backbone of AI today. The input is typically a set of numerical values called "features," representing some aspect of the data being processed. For example, in the case of language processing, the features might be the word embeddings that represent the meaning of each word in a sentence.
Word embeddings are just a numerical representation of text that the neural network will use to understand the semantic meaning of the text, which can then be used for other purposes, like responding in a semantically logical way!
So upon hitting enter in ChatGPT, that text is first converted into word embeddings, which were trained on text from throughout the Internet. There is then a neural network that has been trained to, given the input word embeddings, output a set of word embeddings that are an appropriate response. These embeddings are then translated into human-readable words using the inverse operation to the one applied to the input query. That decoded output is what ChatGPT prints back out.
The conversions, and output generation, are pretty computationally costly. ChatGPT sits on top of GPT-3, a large language model with 175 billion parameters. This means there are 175 billion weights in an extensive neural network that OpenAI has tuned with their large datasets.
So each query requires 175 billion computations at least a couple of times, which adds up quickly. It's possible OpenAI has figured out a way to cache some of these computations to reduce compute costs, but I'm unaware of that information being published anywhere. Furthermore, GPT-4, which is supposed to be released early this year, supposedly has 1000x more parameters!
Computational complexity leads to real costs here! It will not surprise me if ChatGPT becomes a paid product soon, as OpenAI is currently spending millions of dollars to operate it for free.
To understand what's happening in the neural network I mentioned above, let's go back into the research.
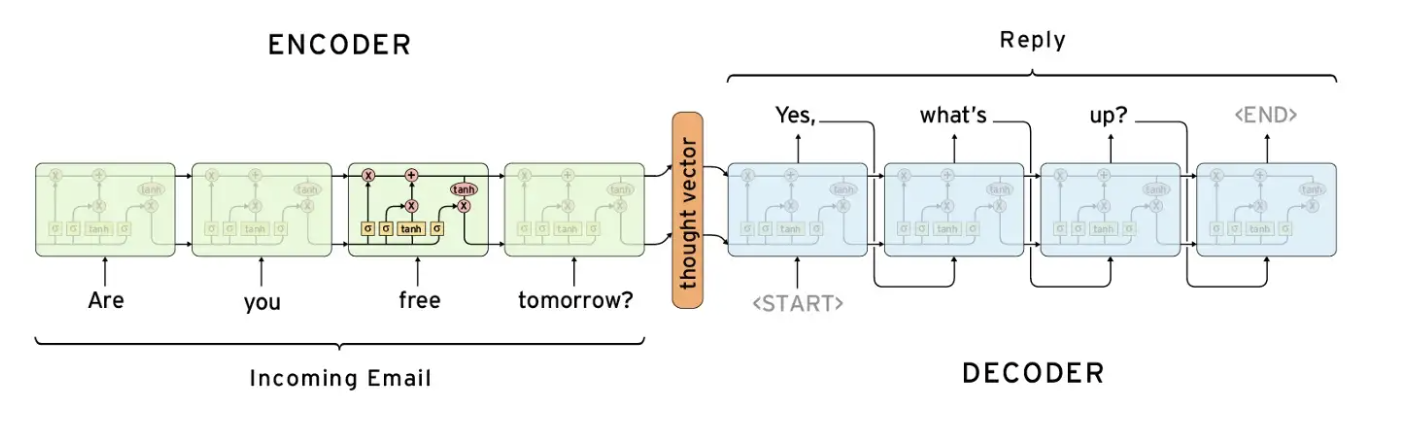
One neural network architecture commonly used in natural language processing is the encoder-decoder network. These networks are designed to "encode" an input sequence into a compact representation and then "decode" that representation into an output sequence.
Traditionally, encoder-decoder networks have been paired with recurrent neural networks (RNNs) designed to process sequential data. The encoder processes the input sequence and produces a fixed-length vector representation, which is then passed to the decoder. The decoder processes this vector and produces the output sequence.
Encoder-decoder networks have been widely used in tasks such as machine translation, where the input is a sentence in one language, and the output is the translation of that sentence into another. They have also been applied to summarization and image caption generation tasks.
Similar to the encoder-decoder architecture, the transformer includes both components; however, the transformer differs in that it uses a self-attention mechanism to allow each element of the input to attend to all other elements, allowing it to capture relationships between elements regardless of their distance from each other.
The transformer also uses multi-headed attention, allowing it to attend to multiple parts of the input simultaneously. This allows it to capture complex relationships in the input text and produce highly accurate results.
Transformers replaced the encoder-decoder architecture as the natural language processing state-of-the-art model when the "Attention is All You Need" paper was published in 2017 because it allowed for much better performance over longer pieces of text.
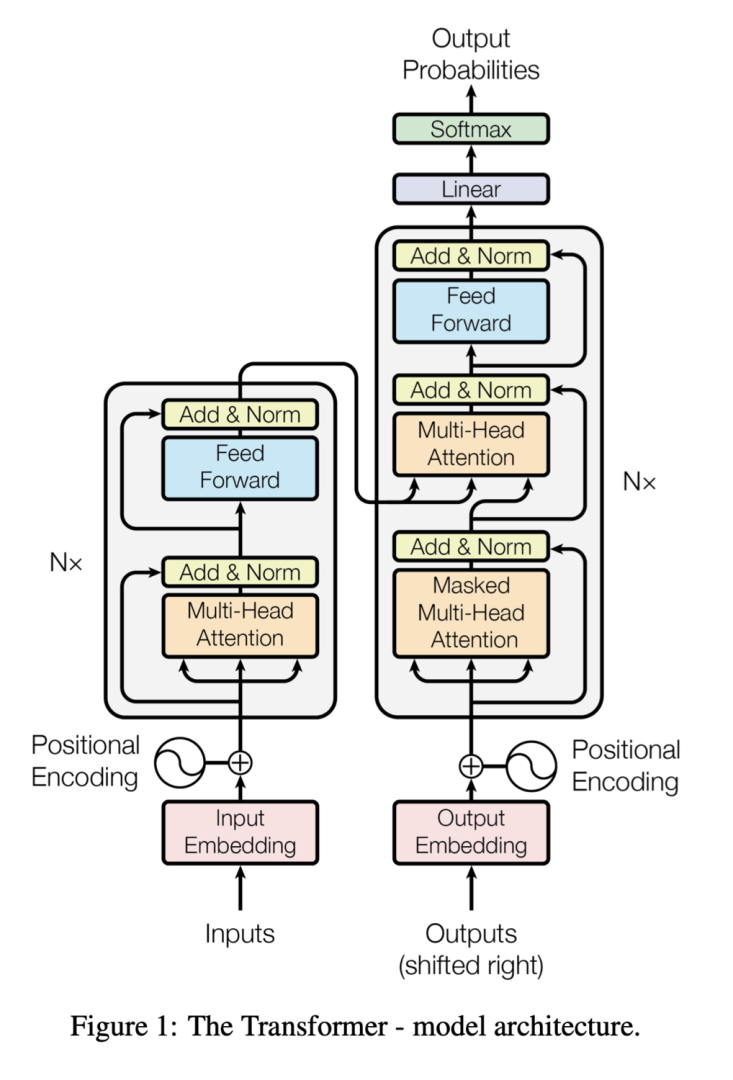
Transformer Architecture, from https://arxiv.org/pdf/1706.03762.pdf
Generative pre-training is a technique that has been particularly successful in the field of natural language processing. It involves training an extensive neural network on a massive dataset in an unsupervised manner to learn a general-purpose representation of the data. This pre-trained network can be fine-tuned on a specific task, such as language translation or question answering, leading to improved performance.
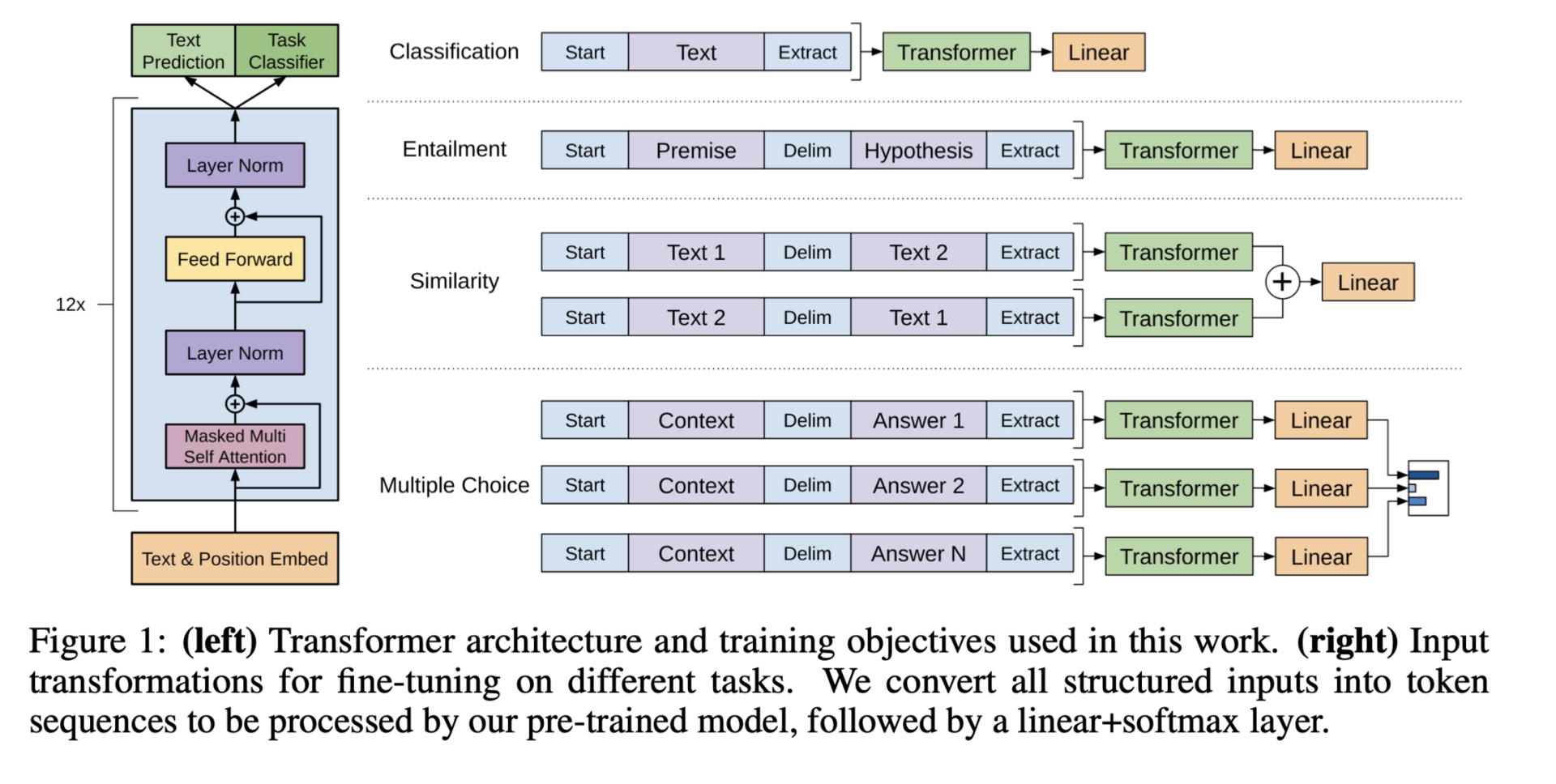
Generative Pre-Training Architecture, from "Improving Language Understanding by Generative Pre-Training"
In the case of ChatGPT, this means fine-tuning the last layer of the GPT-3 model towards the use case of answering questions in chat, which also leverages human labeling. A more detailed look at the fine tuning that ChatGPT leverages can be seen in the image below:
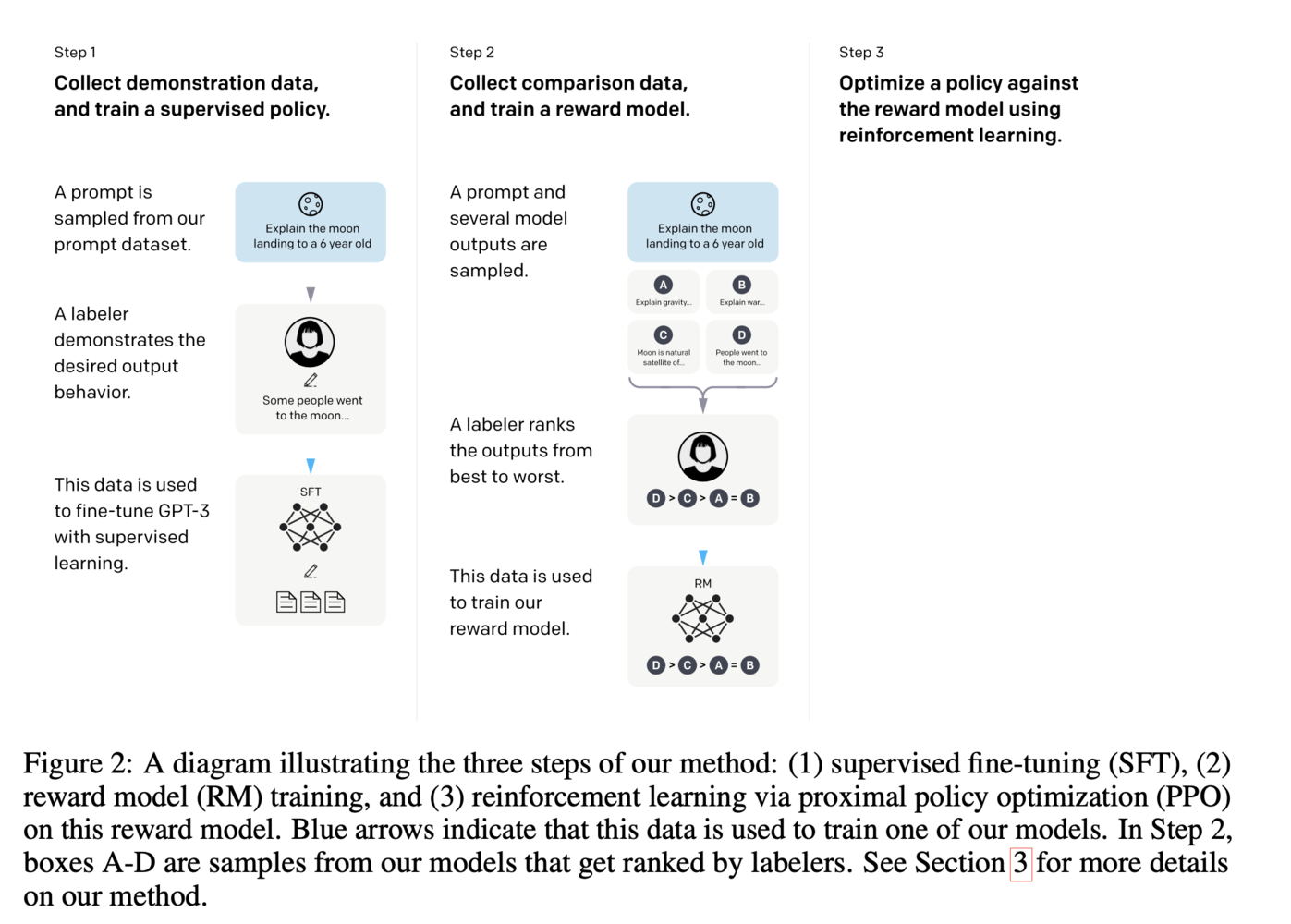
Fine Tuning Steps of ChatGPT, from https://arxiv.org/pdf/2203.02155.pdf
So there are many moving parts under the hood of ChatGPT, which will only grow. It will be very interesting to see how this continues to evolve, as advancements in many different areas will help GPT-like models gain further adoption.
Over the next year or two, we will likely see significant disruption from this new enabling technology, and I'm excited to get to watch! Get your popcorn ready...
Benjamin is a passionate software engineer with a strong technical background, with ambitions to deliver a delightful experience to as many users as possible. He previously interned at Google, Apple and LinkedIn. He built his first PC at 15, and has recently upgraded to iOS/crypto-currency experiments. Benjamin holds a bachelor's degree in computer science from UCLA and is completing a master’s degree in Software Engineering at Harvard University.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest