In the 21st Century, the Data Science community commonly cited the three main ingredients for developing a good machine learning model:
1. Good quality data, preferably labelled
2. High Power Computing
3. Efficient, Precise and Accurate Algorithms
The Importance of Data Labelling

High Power Computing and and Accurate Algorithms are fairly accessible in today's cloud based development environment. Indeed, it is possible for a Data Scientist to evaluate a number of methodologies quite rapidly (within hours, if not minutes) and compare various models by their training time, prediction time, precision, recall and AUC (e.g ROC). These metrics enable Data Scientists to communicate the efficacy of the methodologies to product managers, data engineers and so on quickly in order to allow them to make a decision around which model they'd like to use based on the business problem at hand, the size and shape of the data they would like to work with. A 3 second prediction time may be acceptable in a high latency environment but in a low latency, high risk environment a product manager will value the F1 score and low prediction times as positive trade-offs for high training times.
Know More About your Customers
What Facebook, Amazon, Netflix, LinkedIn, Google and the like are doing is gathering massive data sets but, one has to know what the labels are for these data sets. As an example, Amazon Reviews are a great source of data for sentiment analysis. A model can be trained using the text from the reviews as the inputs and the stars on the reviews as the labels
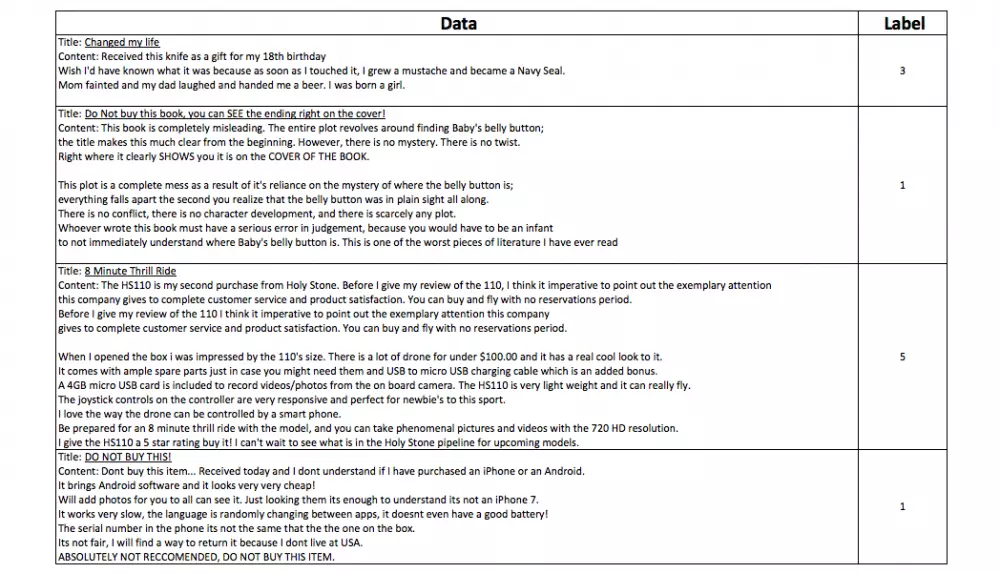
As you can see from the table above, Amazon has curated a huge amount of human input and have had the users themselves attach the labels (1 - 5 stars). Amazon determines whether the review came as a result of a verified purchase, how many other reviews were done by the reviewer, where the reviewer is from, what type of products the user typically bought and what type of products the user typically reviewed. To understand which of these features are most predictive of the label are what is known in data science as feature engineering. A data scientist may find that the reviews from non-verified purchases are actually not reliable at all and may remove these from the featuremart. They may find that the shorter reviews say 30 words or less, have a high degree of correlation to the positive (5 stars) or negative (1 star) sentiment that the review will be labelled with.
The model provided assumptions are maintained using this data which in turn may be extrapolated to different data sets. Say, the mood of a person's WhatsApp conversations with their friends are found to be predictive of suggested pick-me-ups. A user who typically has low energy sentiment in their conversation with their friends likes to go for a Starbucks that day. The app could then suggest to other users that they also perhaps try a coffee as a pick me up, provided there are no health or age restrictions on the recommendation.
Master Their Behaviour

Stall Catcher is another great idea looking at the problem of labelling imaging data to help find the cure for Alzheimers. Many of you are familiar with those CAPTCHA! checks when you log in to websites. Click on the boxes that contain a bird, transcribe these letters and numbers in to keystrokes on your keyboard and so on. These companies have in effect, out sourced the crowd labelling exercise.
When Facebook asked you to tag your friends in photos 15 years ago, it wasn't because Facebook wanted you to be able to see which photos your friends were in, well maybe it was to an extent, but more importantly Facebook wanted you to support them building their models for facial recognition and hey presto! before you know it, Facebook begins suggesting to you what photos your friends are in! This is how predictive analytics use statistical confidence levels to make predictions based on data that it has not seen before but is similar to labelled data that has been seen before.
Likewise, Mastercard and Visa have a mass of customer data and the labels might be whether a customer goes bankrupt or not. Another label may be to predict which customers pay off just the interest each month but never the principal. In this way, they can segment their customer base, give this information to a financial services firm to package up and sell the debt on to other firms that will buy based on the level of risk that they are happy to take.
Improved Decision Making

Also, we look at the recent cycle schemes such as MoBike, Ofo and O-Bike which, while free, allow the operators to collaborate with the Land Transport Authority and the Singapore Mass Rapid Transit Corporation (SMRT) to understand user behavior. It allows the transport planners to capture in which cases users prefer cycles to buses, taxis to trains and buses to trains given many alternate options. In this case the labels are the start and the end points and the data are the time of day, weather conditions, distances, user demographic and so on. Allowing the SMRT to potentially make better scheduling and mid term planning decisions around what services they would like to introduce, maintain and retire.
Household and Commercial Energy usage is another, the label is essentially what the usage is at any given point in time and the data may be about the residents of the household, profession, age, income band, size of household. These are what we call the features that might predict what the household's energy usage might be at a given point in time. There may be a linear or non-linear relationship between these features and the labels. More advanced algorithms such as those discovered via deep learning will be required to solve the non-linear problems. This information today, is only really visible to the energy provider, but with the advent of smart meters, consumers will be able to peek in to the energy usage in their neighborhoods. How energy usage patterns affects their bills and perhaps empowering them to purchase smart devices (e.g water heater that heats up only during off peak periods) which make the best use of the prices available.
So in summary, while this article has touched upon some of the aspects of using crowd labelled data in Finance (Visa and Mastercard), Social (O-Bike and Facebook), Households (Energy, WhatsApp and Stall Catcher) the main point to understand is that every day, whether we know it or not, we are contributing to a massive set of labelled data. Think of that the next time you unlock your phone.





Leave your comments
Post comment as a guest