Comments (5)
Scott Andrews
Well explained Ahmed !!
Kumar Mohit
Excellent info
Dan Hudson
You've covered the essentials, cheers mate.
Jack Lewis
Insightful article
Mark Johnson
Although I am not a tech guy, I was able to understand

“Data Lake” is a massive, easily accessible data repository for storing "big data".
Unlike traditional data warehouses, which are optimized for data analysis by storing only some attributes and dropping data below the level aggregation, a data lake is designed to retain all attributes, especially when you do not yet know what the scope of data or its use.
Data warehouses are large storage locations for data that you accumulate from a wide range of sources. For decades, the foundation for business intelligence and data discovery/storage rested on data warehouses. Their specific, static structures dictate what data analysis you could perform. Data warehouses are popular with mid- and large-size businesses as a way of sharing data and content across the team- or department-siloed databases. Data warehouses help organizations become more efficient. Organizations that use data warehouses often do so to guide management decisions—all those “data-driven” decisions you always hear about.
A data lake holds a vast amount of raw data in its native format until it is needed. While a hierarchical data warehouse stores data in files or folders, a data lake uses a flat architecture to store data. Each data element in a lake is assigned a unique identifier and tagged with a set of extended metadata tags. When a business question arises, the data lake can be queried for relevant data, and that smaller set of data can then be analyzed to help answer the question.
Now that data storage and technology is cheap, information is vast and newer database technologies don’t require an agreed upon schema up front, discovery analytics is finally possible. With data lakes, companies employ data scientists who are capable of making sense of untamed data as they trek through it. They can find correlations and insights within the data as they get to know it.
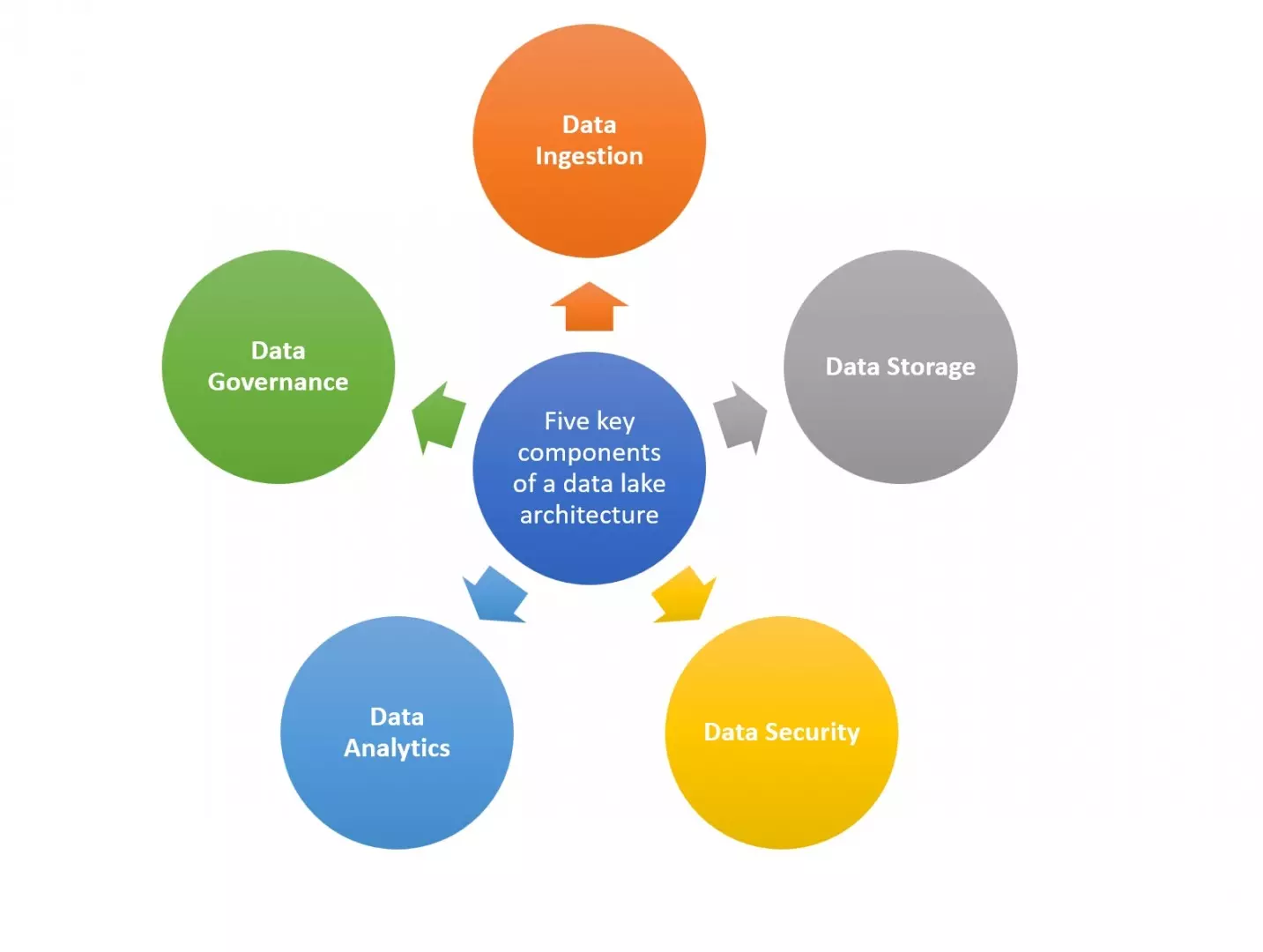
1.Data Ingestion: A highly scalable ingestion-layer system that extracts data from various sources, such as websites, mobile apps, social media, IoT devices, and existing Data Management systems, is required. It should be flexible to run in batch, one-time, or real-time modes, and it should support all types of data along with new data sources.
2.Data Storage: A highly scalable data storage system should be able to store and process raw data and support encryption and compression while remaining cost-effective.
3.Data Security: Regardless of the type of data processed, data lakes should be highly secure from the use of multi-factor authentication, authorization, role-based access, data protection, etc.
4.Data Analytics: After data is ingested, it should be quickly and efficiently analyzed using data analytics and machine learning tools to derive valuable insights and move vetted data into a data warehouse.
5. Data Governance: The entire process of data ingestion, preparation, cataloging, integration, and query acceleration should be streamlined to produce enterprise-level Data Quality. It is also important to track the changes to key data elements for a data audit.
Like big data, the term data lake is sometimes disparaged as being simply a marketing label for a product that supports it. However, the term is being accepted as a way to describe any large data pool in which the schema and data requirements are not defined until the data is queried.
The data lake promises to speed the delivery of information and insights to the business community without the hassles imposed by IT-centric data warehousing processes.
There are many organizations that are making this approach a reality, the internal infrastructures developed at Google, Amazon, and Facebook provide their developers with the advantages and agility of the data lake dream. For each of these companies, the data lake created a value chain through which new types of business value emerged:
Regardless of where you are now, take some time to look to the future. We’re on a journey towards connecting enterprise data together. As business is increasingly becoming pure digital, access to data will become a critical priority, as will speed of development and deployment. The data lake is a dream that can match those demands. The global data lake market was valued at $7.9 billion in 2019 and is expected to grow at a compound annual growth rate (CAGR) of 20.6 percent by 2024 to reach $20.1 billion.

Well explained Ahmed !!
Excellent info
You've covered the essentials, cheers mate.
Insightful article
Although I am not a tech guy, I was able to understand
Ahmed Banafa is an expert in new tech with appearances on ABC, NBC , CBS, FOX TV and radio stations. He served as a professor, academic advisor and coordinator at well-known American universities and colleges. His researches are featured on Forbes, MIT Technology Review, ComputerWorld and Techonomy. He published over 100 articles about the internet of things, blockchain, artificial intelligence, cloud computing and big data. His research papers are used in many patents, numerous thesis and conferences. He is also a guest speaker at international technology conferences. He is the recipient of several awards, including Distinguished Tenured Staff Award, Instructor of the year and Certificate of Honor from the City and County of San Francisco. Ahmed studied cyber security at Harvard University. He is the author of the book: Secure and Smart Internet of Things Using Blockchain and AI.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest