Comments (3)
Jessica Price
I usually don't find an amazing article like this one.
Eric Adams
Fabulous article. A must read for every one.
Tyler McGuigan
Excelent article, very useful.

Programmers love a fight. Ask a roomful of programmers the question "EMACS or VI", leave the room for coffee, come back half an hour later and there will be blood on the floor. For data storage buffs, the same question, at least lately, comes down to SQL vs. NoSQL. Each has its defenders, its book of holy writ, its benchmarks and success stories ... and each has its dark secrets and stunning failures as well.
Yet the question of whether data content is SQL vs. NoSQL misses the bigger picture issue, which can be summarized most readily as "How structured is your data?". Put another way, to what extent is your data normalizeable.
Not that long ago, the distinction between data was pretty clear cut - you had "data" - rows and columns and linked references - then you had documents where the information was contained in a single streaming narrative. You knew where you stood in those days (about thirty years ago). You simply couldn't put document content into a database. It made no sense to.
In the late 1960s, as computers began to be used in more and more interesting ways, a document made use of markup to provide signals to the typesetter (either human or electronic) about how a given sequence of text was to be rendered. A number of different systems emerged, most proprietary, but one or two that were agreed upon as open and standardized. The most heavily utilized of these was a language originally called the Generalized Markup Language (GML), but would eventually becoming the Standardized General Markup Language (SGML) as different proposals made their way through both US and later ISO standards processes.
Tim Berners-Lee's great genius lay in creating a dialect of SGML called the Hypertext Markup Language (HTML) and tying it into a linking protocol (HTTP). SGML was a set of rules for creating languages, and HTML was one such language. It was not especially rich when it was first laid out, as its primary purpose was in the construction of citational abstracts, but over time it became obvious that you could extend this language in any number of different ways.
A parallel track was occurring as the SQL database took form. Ted Codd of IBM had been looking at different data systems through the early 1970s, and realized that you could take complex objects and decompose them into linked tables, using these to navigate across complex structures by joining these tables at the link points. He introduced the idea of normal forms that in essence handled the various kinds of cardinality relationships that data can have.
Cardinality has always been a problem with data - indeed, it is perhaps the CENTRAL problem. Most data ultimately comes down to four types of relationships:
Ordering also plays a huge part. The moment that you shift from maxOccurs = 1 to maxOccurs = infinity you introduce a bias towards a particular ordered sequence of items that is largely machine dependent. Additionally, you have to deal with the problem inherent with functional tables - you cannot put more than one value into a given field for a row in a table without some kind of encoding process, such as converting all entries to strings and then using a delimiter such as a comma, tab or pipe to indicate separation.
Instead, you have to normalize the relationship, by creating a primary key identifier for each row in the "subject" table, and then creating a foreign key reference to that primary key. This way you preserve a functional (1 to 1) relationship between rows of each table. You can think of this as a directed reference from the subordinate row to its parent, where the subordinate row "owns" that reference (bookmark this concept of ownership - it's VERY important). Who owns references is fundamental to modeling.
The moment that you create a link to a separate table, you are in effect creating an object. Indeed, even atomic values are instead links to objects that have scalar values and dimensional attributes, event markers and attribution, but in SQL relational model, most of these are subsumed in schema in order to keep computation manageable.
Most relational DBAs tend to focus on normal forms, though in general, these effectively describe which objects own which vectors. First normal form indicates that a generic object also maintains its own data, while in a second normal form, each row of a join table points to a different row in different tables. Second normal forms typically describe many to many relationships, such as the relationship between a book and an author (an author may have more than one book that they have contributed to, a book may have more than one author contributing to it). Third normal forms and so forth then describe more specific structures.
One of the major realizations made in the early 1990s was that you could in fact describe a data structure using markup. To do this, it was deemed necessary to simplify the SGML structures into a more limited dialect which was eventually named XML. This had two major effects. First, it meant that you could in fact begin to decompose a document into a tree structure (or a forest of tree structures) using a document object model (DOM). The second was that you could incorporate metadata into this model that made it possible to schematically describe this structure.
XML originally was designed upon the assumption that order was not a part of the the structure (that there was no guarantee that nodes should return in document order), but in point of fact sequential order was implicitly assumed shortly after the language was adopted. The XML language also assumed the existence of invisible key/key reference pairs that held the structure together. This meant that a DOM collapsed certain information that were explicit in a SQL model, making it possible to create complex structured resources.
Indeed, in many respects, an XML or JSON is not so much "semi-structured" but "super-structured", in that it had more structure (less entropy) than SQL tables - an XML structure can always be reduced to to a set of table rows, but in doing so, more information needed to be generated (such as ordering priorities and key/ref pairs) to do so.
This actually brings up one of the bigger conundrums of translation between XML and JSON. XML has a concept called a sequence, which can hold element nodes, text or related nodes such as comments or processing instructions, and atomic values such as strings, dates or numbers of various sorts. If you insert a sequence into a sequence the inserted sequence is "dissolved" and the items are added at the point of insertion directly. JSON has no such structure, but it does have an array. When you insert an array, the inserted array itself becomes a distinct object.
In general, these subtle differences can be worked around, but they make it clear why working with document content in particular is still such a challenge. Most documents do have clear structures at the macro-level, but the issue of dealing with tagged content content at the micro level (such as a mixed bag of paragraphs, headers and images) make for encoding this information at the micro-level difficult.
This is another area where semantics (and RDF in general) can serve as an important bridge. For instance, sequences and lists can be surprisingly complex structures. RDF can describe arrays as well as linked lists. A linked list is known in RDF as a collection, and consists of a "backbone" of blank nodes:
book:StormCrow book:chapters _:list. _:list rdf:first chapter:StormCrow_Intro. _:list rdf:rest _:b1. _:b1 rdf:first chapter:StormCrow_Ch1. _:b1 rdf:rest _:b2. _:b2 rdf:first chapter:StormCrow_Ch2. _:b2 rdf:rest _:b3. _:b3 rdf:first chapter:StormCrow_Ch2. _:b3 rdf:rest _:b4. ... _:b21 rdf:first chapter:StormCrow_Ch20. _:b21 rdf:rest _:b22. _:b22 rdf:first chapter:StormCrow_Epilog. _:b22 rdf:rest rdf:nil
In this form of list, if you have the starting address, then you have a link to each chapter in order as well as a pointer to the next "vertebrae" in the spine. The downside to this approach is that you can get all of the items from such a list easily enough in SPARQL, but you have no guarantee of order:
select ?chapter ?baseNode ?nextNode where {
?book book:chapters ?chapterList.
?chapterList rdf:rest*/rdf:first ?chapter.
?baseNode rdf:first ?chapter.
?baseNode rdf:rest ?nextNode.
}, {book:iri(book:StormCrow)}
=>
chapter baseNode nextNode
chapter:StormCrow_Ch2 _:b2 _:b3
chapter:StormCrow_Ch7 _:b7 _:b8
chapter:StormCrow_Ch13 _:b13 _:b14
chapter:StormCrow_Ch10 _:b10 _:b11
This doesn't mean that you can't get the list ordered outside of SPARQL (it's a pretty easy script to do so in Java or Javascript), but it does mean that linked lists are not obviously equivalent to arrays.
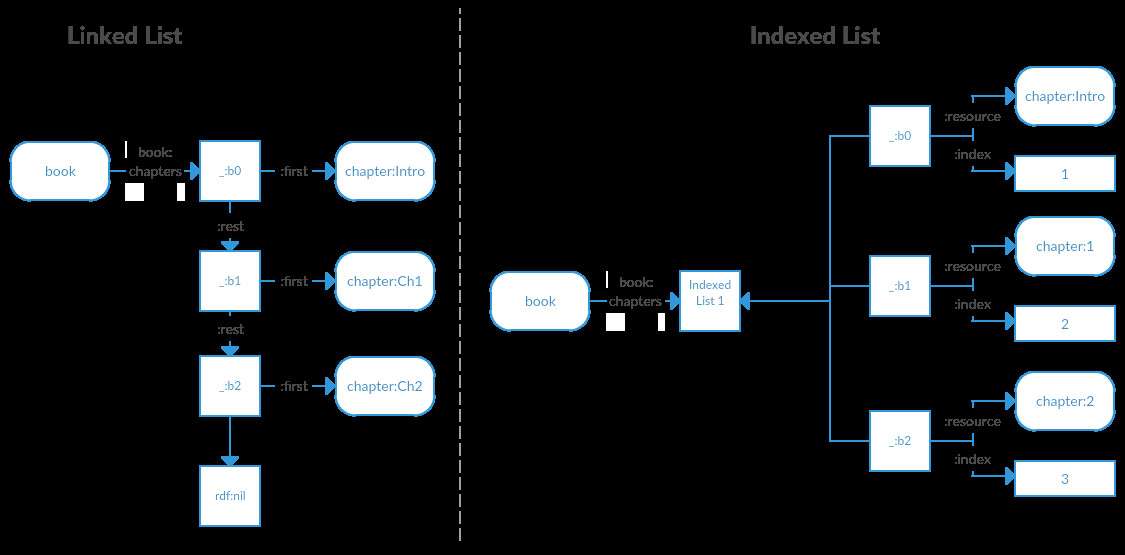
An alternative approach is to use indexes that specify the order as a weight:
book:StormCrow book:chapters _:list.
_:list :hasMembers
[:resource chapter:StormCrow_Intro;
:index "1"^^xsd:long],
[:resource chapter:StormCrow_Ch1;
:index "2"^^xsd:long],
[:resource chapter:StormCrow_Ch2;
:index "3"^^xsd:long],
...,
[:resource chapter:StormCrow_Ch20;
:index "21"^^xsd:long],
[:resource chapter:StormCrow_Epilog;
:index "22"^^xsd:long]
.
There are several advantages to this approach. First, it corresponds far more closely to the concept of an array. Getting a listing in order (in SPARQL) becomes a matter of specifying the index as a sort key:
select ?chapter where {
?book book:chapters ?chapterList.
?chapterList :hasMember ?member.
?member :resource ?chapter.
?member :index ?index.
} order by ?index,
{book:iri(book:StormCrow)}
Additionally, retrieving a given indexed entry becomes trivial - it uses the same query, but fixes the index to a specific value (here, the fifth chapter in the book).
select ?chapter where {
?${book} book:chapters ?chapterList.
?chapterList :hasMember ?member.
?member :resource ?chapter.
?member :index ?index.
} order by ?index,
{book:iri(book:StormCrow),index:5}
(Here, I'm using ?${book} to indicate passing the identifier key for the book, something akin to how template literals work in Javascript.)
If a chapter is contained in more than one book, you can determine all the books that contain the chapter without having to walk a chain:
select ?book where {
?book book:chapters ?chapterList.
?chapterList :hasMember ?member.
?member :resource ?${chapter}.
?member :index ?index.
} order by ?index,
{chapter:iri(chapter:StormCrow_Intro)}
=>
?book
book:StormCrow # As the first 'chapter' in the book
book:Magi # As a teaser chapter at the end of the book for the sequel
Indeed, what's most notable here is that the body of the query in all three cases is the same - it's only the item selected and the constraints that change. If we extend this with a title and a publication date then it is possible to create one query that can respond to a large number of potential services:
select ?${selections} where {
?book book:chapters ?list.
?list list:hasMember ?member.
?member list:resource ?chapter.
?member list:index ?index.
?book book:publicationDate ?pubDate.
?book book:title ?title.
?chapter chapter:title ?chapterTitle.
} order by ?${sort},
{selections:"?book ?pubDate",sort:"asc(?pubDate)"}
=>
book pubDate
book:Mage 2017
book:StormCrow 2019
It's also worth noting here that ordering is extrinsic in certain types of lists (such as where a chapter occurs in a given book list), but not in others (you can sort by date or alphanumeric code, or even some combination thereof).
RDF consequently can be seen from a data standpoint as something that straddles the distinction between document and data of the various other formats. You could create an ordering structure for decorator elements in a paragraph (such as <b>, <u>, <a> and so forth), in much the same way, although admittedly this gets cumbersome:
[] a html:P;
il:hasIndexedList _:list.
_:list :hasMembers
[il:resource [html:literal "This"; a html:B];
il:index "1"^^xsd:long],
[il:resource [html:literal "is"; a html:U];
il:index "2"^^xsd:long],
[il:resource [html:literal "a"; a html:I];
il:index "3"^^xsd:long],
[il:resource [html:literal "test";
html:href "http://www,mytest.com";
a html:A];
il:index "4"^^xsd:long],
[il:resource [html:literal:"."; a html:text];
il:index "5"^^xsd:long]
.
I've put this particular indexed list into the "il" namespace (for now, the namespace itself doesn't matter) primarily to indicate what is in which domain. The indices here are part of the generic member entities, not the specific resources. In this respect the blank node is an indexed list member, as shown by the commented statement above.
[] il:resource owl:Thing; il:index "1"^^xsd:long; # a class:indexedListMember .
This use of intermediate "helper object" such as an indexed list or a linked list is important because they shift the management of structures away from the semantics of the primary ontology (html here) and towards a separate data structure space that can be used in a large number of contexts.
Given the advantages of an indexed list, it's odd that the RDF specification doesn't have an explicit structure for indexed lists (it sort of does, if you look at the definition of rdf:Seq, but the solution is weak). The reasons are largely historical:
Indeed, this highlights the distinction between the two in a way that gets lost in languages like Javascript (and is completely obscured in XML). An indexed list is a different structure than a stack, which is a linked list. If all of my operations involve pushing and popping things onto a stack, a linked list is a great thing: new items are pushed onto the head of the stack, and the pointer to the head then gets changed accordingly to the new item, a classic Turing action. Popping does the inverse action, setting the head to the next item in the stack and removing the previous head. These are easy actions to do in SPARQL.
With an indexed list, on the other hand, iteration over the stack is a bit slower (you have to calculate the next index in the stack first, then search for the member which has the corresponding index), but random access is generally faster, and you can get a guaranteed ordered list from SPARQL queries, which you can't do with transitive closure. What also happens here (which I believe is an important distinction) is that each member is directly linked to the list object, rather than indirectly linked as is the case with an unindexed list. This is the ownership principal at work - in a linked list, any given node in the backbone is owned by a previous node, rather than a specific list object. Transitive closure is a useful property - walking the chain - is a useful property, but it makes modeling difficult.
The broader takeaway from this is that modeling frequently relies upon identifying (and utilizing) those helper structures that are semantically neutral but that hold semantically sensitive data constructs in place. Narrative structures imply explicit ordering and indexed lists. Saving state usually involves a stack, or linked list. One to many relationships should always be inbound connections. If a resource "points" to more than one object of the same type using the same property, then you're probably doing something wrong. These rules may seem simple, but they can usually help to disentangle complex data models in the most efficient manner possible.
By understanding the importance of cardinality and ordering in data modeling (and that these are usually not as arbitrary as they may seem on the surface) you can make your data models work better regardless of how they are stored. This in turn improves serialization, and, with intelligent query design, can also simplify creating data services. They are all related.

I usually don't find an amazing article like this one.
Fabulous article. A must read for every one.
Excelent article, very useful.
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest