Comments (1)
Hayley Sewell
Outstanding post

There’s a concept that’s been floating around from the realm of Big Data called a “data lake”. Now, personally, this is a remarkably misleading term, as it implies that data is like a liquid that flows, rather than the representations of people, businesses, contracts, books, widgets and anything else that can be represented as entities of some sort. You can’t dip a glass into a data lake and get some data. As metaphors go, it’s wrong in very nearly every way, and when dealing with virtual content, metaphor is astonishingly real.

So what I’m going to describe is not a data lake. It's a data hub. This is an important distinction.
An airport hub is a fascinating metaphor, and one that is actually far more useful to an enterprise. In theory, an airline connecting two cities would seem to be an optimal path - you aren't wasting jet fuel going to a third city that adds time to get from A to B. Yet most airlines instead create networks where there may be two or three primary hubs within a given country or set of countries. This becomes more reasonable when you realize that different cities have different demands - it makes more sense to go from Seattle to Sacramento by taking a larger jet for higher traffic to San Francisco (SFO), then a smaller commuter jet from SFO to Sacramento.

It also increases the potential paths that a given flight can take to get from point A to point B, meaning that if a plane breaks down or is running late, then there are some redundancies in getting people to their destination regardless via alternate routs, which can be enhanced by two airlines agreeing to share routes and handle partial routes in the case that they don't have the connections immediately available.
Finally, hubs tend to be places where airlines keep their reserve aircraft, repair centers, and frequently administrative functions. In this regard, hubs are considered privileged nodes within the network, and their existences and locations usually has a profound impact upon the efficiency of the overall network.
A data hub fulfills many of the same functions. The idea behind it is comparatively simple - you establish the data that is most commonly needed (and that represents the most holistic view of the company) into a generalized data model that can be most easily queried, then move intermediate data that feeds into that towards the edges of the network. This requires a certain degree of control over provenance and reliability, and also requires understanding that what you're doing is not simply aggregating your data in a single repository.
Almost every unsuccessful data lake project that I've seen works on the same principle - if you get all of the data from one database into a common repository (for instance, a Hadoop Hive instance) then your work is done. In reality all that you have done at that point is replaced one database with another (potentially slower one), then slaved your data access to that larger, slower database. This works great for certain requirements - archiving for regulatory requirements being the significant one - but it does not in fact significantly enhance your ability to do anything with that data that you couldn't do before.
In a true data hub, one of your primary goals is to move the information you have from a lexical access system to a conceptual one. As a relatively simple example of this. Let's say that you have one data system that talks about net quarterly revenue based upon a calendar year quarter, while a second system has revenue based upon a net fiscal year with a two month offset (this is deliberately simplified). In this system, the first field is REVQUARCAL while the second is REVFISQRTR. These are lexical fields - we are dependent upon knowing the underlying name of the field to access information.
In a conceptual hub, on the other hand, we define a concept called ReportedRevenue, which couples a currency with a specific interval of time, a source, and a definition that is tied to that source (in effect one aspect of its provenance). Both REVQUARCAL and REVFISQRTR are then identified as being of type ReportedRevenue (or, to put it another way, if I have table A.Revenue and B.Revnu from different databases and tables, I've created an identity that says that each value of A.Revenue.REQVUARCAL and B.Revnu.REVFISQRTR are of the same basic type (ReportedRevenue) but have different definitions for their reporting cycle.
What's the benefit here? First, it allows me to view the same data through different lenses (tableA vs tableB) to make sure that they are consistent even with different data. It makes it easier to derive revenues for smaller intervals (say monthly) once you ascertain the consistency of the source data. It also means that when you get a third data source, you can use the same ReportedRevenue concept, but with its own provenance trail. Additionally, because currency figures are often reported relative to an index year in order to better account for inflation, this conceptual breakdown makes it easier to identify what these index factors are.
A similar argument can be made for controlled vocabularies, where you identify a set of enumerations for a given field. By identifying the enumerated terms as categories in a vocabulary, you can both provide for a set of definitions (again based upon provenance) and establish a mapping between each databases enumerations and a consolidated common vocabulary. Once you've identified functional (1 to 1) mappings between enumerated terms to that common set, you can actually map from one enumeration set to another without having to build a new mapping (or you can build a one to many mapping that provides you a subset of enumerations for partially automated systems).
Initially this does require human mapping between fields, with the maps themselves being software components that can be stored and accessed based upon provenance, so the first stages of such a process tend to be human-specific. However, once the relevant canonical forms are established as concepts, then new databases are much easier to add. This can also be done (and should be, for that matter) in an incremental manner, with obvious mappings being done first, then less obvious ones being added in over time.
The iterative nature of such a smart data hub is in fact what makes it so powerful. It is rare for any one data system to actually have complete information about your system, and the information coming from different systems may very well have greater or lesser reliability based upon provenance and data quality.
By using an iterative system, it becomes possible to infer data and store it ... and also allows for measures that can give the reliability of such inferences. For instance, it may be possible given two different quarterly measures to infer a monthly amount, but that data will be subject to uncertainty (such as the use of an average). If in the future, that data is available directly, then the inferred data can be dialed back based upon what relable data does exist.
One key advantage a smart data hub approach has comes in the realm of identity management. When you have resources - anything from people to businesses to product to locations, most traditional relational databases identify them with an internal key based upon an arbitrary integer (or long) number. This means that two different databases will almost certainly end up having different keys for the same person - A.person.12533 is the same as B.employee.958141, who is also C.member.442683.
Resolving these different keys back to the same resource can get to be complicated. Names by themselves are usually not sufficient for a large enough group of people. In the US, there are more than 46,000 people with the name John Smith, as an example. Moreover, names change over time (through marriage, adoption of professional names, divorces, and so forth).
The same principles apply for other entities in a business. Business names change. Products are rebranded or have multiple names, and so forth. This means that any smart data hub needs to both handle the process of identity management and provide a way of correcting misidentified resources. This is something that semantic systems generally excel at.
Semantic hubs use inferences to both identify and build relationships where ones may not explicitly exist. This can be used with inbound data to establish "likely" matches, where a resource in one database is effectively the same as it is in another. Semantic systems are also conservative - if the same link is identified by multiple rules, the system will only maintain one such link, performing the same action as is typically handled in computer languages performing reference counting.
An example of these principles can be seen in the distinction between a weak hub and a canonical one. A "weak" hub is one where there is a single conceptual entity representing each resource. Here, that resource is a row pulled from three different database source tables describing a single specific value for revenue in the northwest sector in the third quarter of 2017.
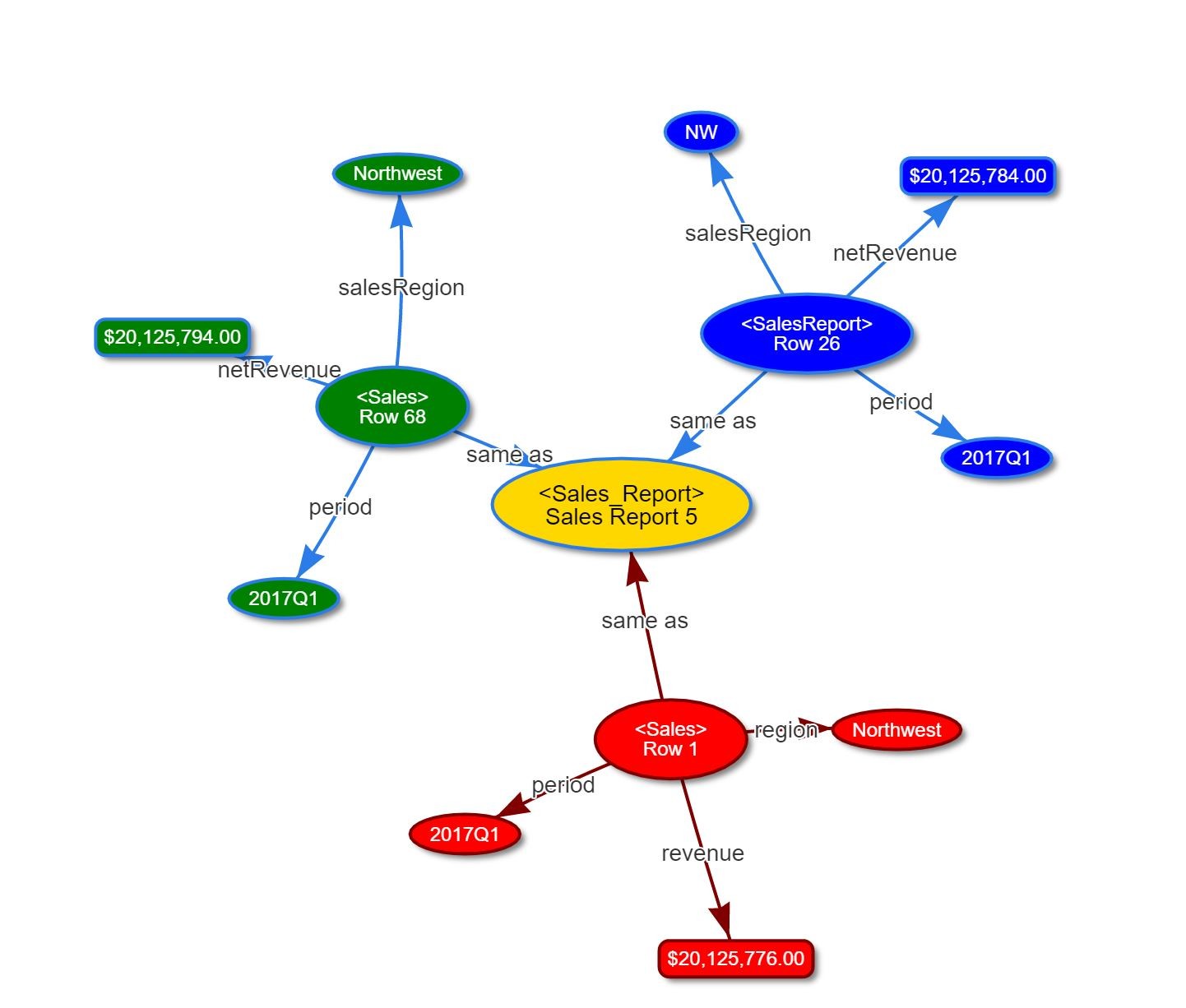
Each of the red, green and blue entries represent a different database and table that nonetheless have similar information about sales. The arrows are analogous to field names. This approach assumes that you have hoovered tables into a semantic system (I'll get into implementation details in a bit), then used an MDM-like inference to identify that each of them represent the same object. In this case, the rules for that inference comes down to identifying that if a row has the same period and region, then it is likely the same value, and this can be strengthened if numeric values are roughly equivalent.
Note that the revenues here are NOT totally equal - it is very likely that different systems may have roughly the same values, but different reporting tools and calculations may make the differences sizeable enough that using exact equivalences may disqualify legitimate entries (giving you false negatives).
Each database has its own name for a property (and may have more complex transformations may be involved). This can make writing queries difficult. This is where a strong smart hub comes into play.
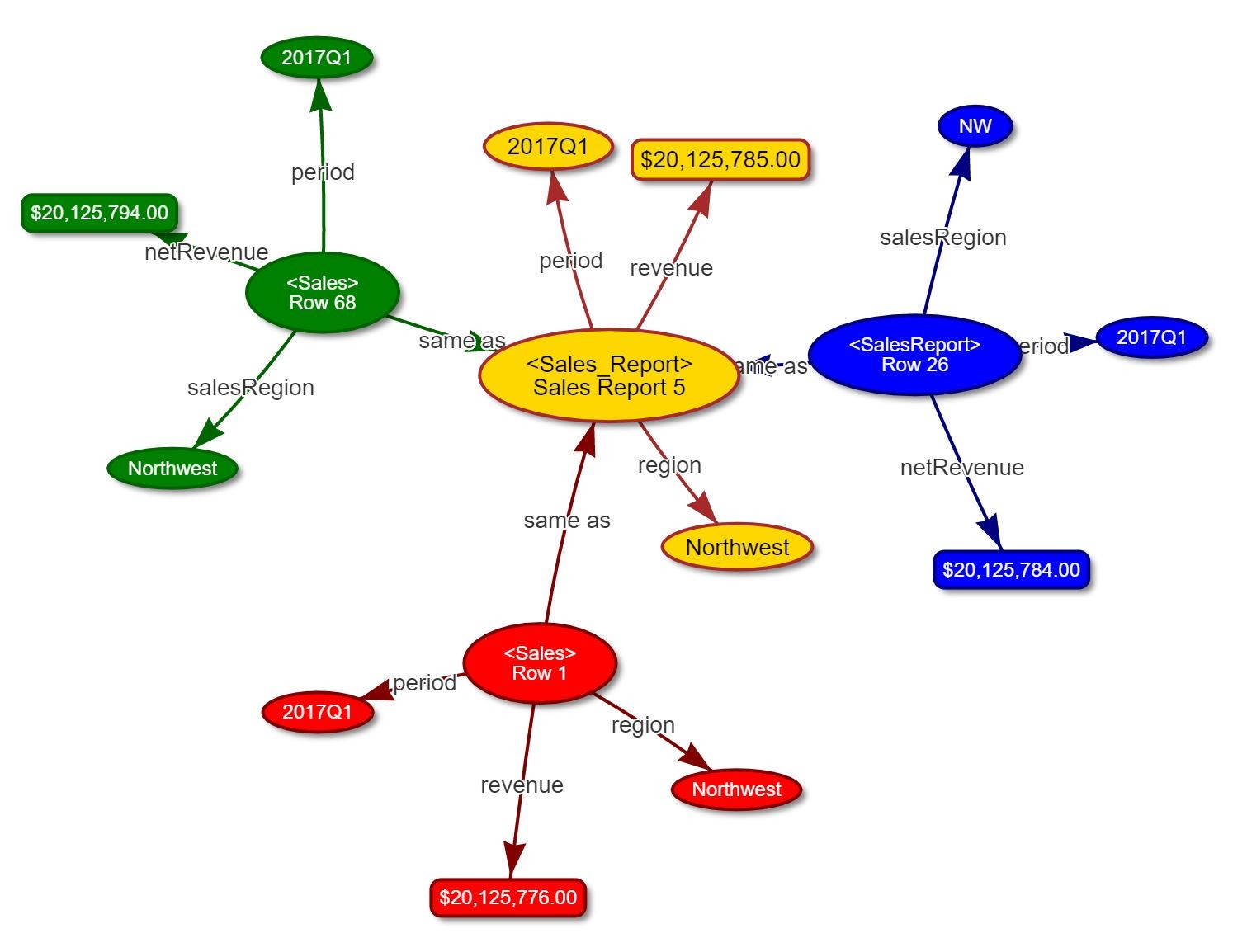
This model is almost identical, with one major exception - the canonical hub element for each entity also has properties, and these exist to a canonical model. In this case, the revenue is given as the average of all input revenues, while the period and region have been mapped to canonical equivalents.
Strong hubs are more complex to create, but they have considerable advantages. First, they are both computationally faster to run and easier to write to, because there is a consistent language model. They can be used to identify both preferred terminology and to manage non-preferred terms (NPTs) in a consistent fashion.
Additionally, this makes it possible to translate from one database entity to a different one, whether that's a term in a controlled vocabulary or a resource in a business model. Indeed, anything that isn't by itself an atomic value such as a date or follows the same kind of pattern of potentially mapping to a canonical equivalent.
This model also makes it possible to backtrack to data within existing databases, though it's important to understand governance models here. This is not a comprehensive read-write hub. If a database field is designated as a source, then any changes from that source must flow from the database to the hub, and not vice versa. This is primarily a state management issue - if both databases are capable of read/write activity on a given field, then you would end up with the potential for an event storm as field dependencies on both sides end up oscillating between states.
My experience with smart data hubs has centered around MarkLogic, which I'll describe here. I like MarkLogic primarily because it provides a solid set of APIs for working with both semantic and non-semantic data. However, in this case, I would also recommend including a node.js instance that acts as the connector into various relational databases.
The node instance ran as a web server on port 8800, which in turn was designed to invoke SQL responses from several different databases and convert them into JSON. In very general terms, the node script first used the SQL SHOW DATABASES and SHOW TABLES commands to retrieve the underlying model used, then used the DESCRIBE function on each table to get specific field model information as well as to identify primary and foreign keys as JSON. For instance, the following might be an example from a city entry (here, using mySQL).
[ {
Field: 'ID',
Type: 'int(11)',
Null: 'NO',
Key: 'PRI',
Default: null,
Extra: 'auto_increment' },
{
Field: 'Name',
Type: 'char(35)',
Null: 'NO',
Key: '',
Default: '',
Extra: '' },
{
Field: 'CountryCode',
Type: 'char(3)',
Null: 'NO',
Key: 'MUL',
Default: '',
Extra: '' },
{
Field: 'District',
Type: 'char(20)',
Null: 'NO',
Key: '',
Default: '',
Extra: '' },
{
Field: 'Population',
Type: 'int(11)',
Null: 'NO',
Key: '',
Default: '0',
Extra: '' } ]
This dataset, along with data from "SHOW INDEX" made it possible to set up rules for creating specific IRIs, such as: <urn:uuid://source1/world/city#125> or <urn:uuid://source1/world/country#USA>. Field names would then end up with encodings such as <urn:uuid://source1/world/city/property/Name> or <urn:uuid://source1/world/city/property/CountryCode>.
With these URIs and some basic rules that could be encoded in SHACL, this data can be converted into triple notation (here as SPARQL UPDATE). The checksum is used to make incremental updates possible, as this can provide a quick check to insure that the record in question hasn't changed.
PREFIX src1City: <urn:uuid://source1/world/city#>
PREFIX src1Country: <urn:uuid://source1/world/country#>
PREFIX src1District: <urn:uuid://source1/world/district#>
PREFIX src1Language: <urn:uuid://source1/world/language#>
USING graph:src1
DELETE {
src1City:125 hub:blank* ?o.
?s1 ?p src1City:125.
}
INSERT DATA {
src1City:125
a class:src1City;
src1City:ID "125"^^xsd:integer;
src1City:Name "Seattle"^^xsd:string;
src1City:CountryCode src1Country:USA;
src1City:District src1District:WA;
src1City:Population "2,312,775"^^xs:long;
hub:Checksum "AECD185319313359"^^xs:hex;
.
...
}
WHERE {
src1City:125 hub:blank* ?o.
?s1 ?p1 src1City:125.
}
The hub:blank predicate is a superproperty of any property that needs to be eliminated when the resource is eliminated (typically handled through blank nodes). The actual logic is somewhat more complex, but basically,
The data is queried via a scheduled call from Marklogic with SPARQL as the return content, which is then inserted into the triple store that MarkLogic itself runs. Typically, when this happens, a number of inferences are calculated - removing any entries that have changed and replacing them with the updated entries, adding new entries, and, as set up, updating the canonical model. These are also handled by SPARQL Updates (with minor variations).
Ingestion from XML or JSON is in some respects easier, in some more complex. In the case of XML, a transformation in XSLT or XQuery may end up being used to generate the associated triples (encoded as XML), while in the case of JSON, a Javascript script would generate either a JSON-LD or internal JSON RDF format. The central issue with both structures is that it is usually easier to normalize the structures ahead of time prior to converting it into RDF. There are also issues with sorting and sequencing that need to be resolved ahead of time.
The important thing to take away from this is that such Smart Data hubs put the onus of development largely at the beginning of the process, spending time to intelligently design conversion filters. In general, a smart RDF data hub should not be seen as a plug and play operation. Rather, the system becomes more intelligent over time, as it has more data on which to build rules and infer relationships.
Queries and services are mostly synonymous. Typically endpoints are established by identifying parameters of SPARQL scripts and using them with rewriteable URIs. In general, SPARQL query result sets are retrieved as arrays (with MarkLogic, iterator maps or objects, depending upon how they are invoked), which can in turn be transformed into other structures via XSLT or XQuery. Inbound structures are a bit more complex - these typically make use of ingestor REST pipelines to convert from JSON or XML into RDF, though raw RDF can also be set up. Typically, with inbound services (PUT or POST) there is also a validation step using SHACL to insure that the contents being uploaded are well-formed and valid.
Note that nothing here specifically addresses a user interface for managing this data. This is actually a pretty key part of any smart data hub, but that's fodder for a different article. Additionally, in the case of MarkLogic, the new Entity Services component coming out with MarkLogic 9 later this year can be used with one key area - providing a SQL-like interface that can treat the data entered in both the canonical and non-canonical models as if they were SQL tables. By working with Entity Services, it is now possible to use standard SQL analytics and visualization tools such as Tableau, Open Refine, KNIME, Cognos or related applications with the data hub transparently.
Smart Data Hubs are not universal databases. They are, rather, tools for identifying the relationship between data coming from multiple sources, for managing consistent enterprise data, and for consolidating (and ultimately canonicalizing) the data most commonly used within your organization. They make managing provenance and maintaining governance considerably easier, and they can go a long way towards creating a centralized data system that can, nonetheless, be used by applications all across your organization.

Outstanding post
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest