Comments (3)
Kevin Burton
Excellent article
Suraj Sharma
Sounds about right
Joanne Whelan
Thanks for the tips

The late Terry Pratchett (often known as pTerry) was an English writer noted for his droll wit and sometimes biting social satire.
He wrote more than forty novels in his Discworld series, plus multiple additional series including one that looked at the evolution of science in our Roundworld as seen through the eyes of the Discworld magicians, five movie adaptations, and collaborations with writers such as Neil Gaiman (Good Omens, hilariously brought to the screen by Dr. Who's David Tenant and actor Michael Sheen). He was also easily one of my personal favorite writers.
Some of Pratchett's best characters were his Trolls, which were magically enhanced living rocks that tended to take on the characteristics of the rocks that they were made of. Initially portrayed as rather stupid, over time his Trolls became far more nuanced. For instance, when Trolls counted, they did so as follows: "One, Two, (Three), Many, Lots". These seems simplistic, until you realize that it is in effect a base four system: 1, 2, 3, 4, 16 (or, if you use a zero placeholder, (0), 1, 2, 3, 10, 11, 12, 13, 20, 21, 22, 23, 30, 31, 32, 33, 100. In computer parlance, "many" is one above a nibble, or half a byte, and "lots" is one above a word. As Trolls are silicon-based life forms, this makes a great deal of sense.
One of the most memorable passages about Trolls talks about Detritus, eventually Chief Sargeant of the Night Watch, who ended up being trapped in a pork futures warehouse (a place where pork slabs slowly materialized from nothingness until they became fully real). While there in the supercooled environment (the future is always cold) Detritus went from being canny but not terribly bright to becoming brilliant, carving out mathematical calculations about the nature of space-time on the walls of the warehouse even as he was succumbing to hypothermia.
I've found, when doing data modeling, that keeping in mind pTerry's Trollish counting scheme can actually be very useful when designing semantic models. It should be noted that in semantics, a given resource or entity can be thought of as having both inbound and outbound links (this is also true of non-semantic models, but this tends to get lost in UML). I like to think of an outbound link as being something that describes a characteristic - whether an atomic value or a relationship to another resource - that is intrinsic to that resource. All atomic value literals (such as labels or dates) are outbound links.
Where things become more problematic is what to do with resource-to-resource relationships, which I can links. A person, for instance, may have multiple children. The question is, for that person, whether the child should be considered something that is intrinsic to that parent (an outbound link on the parent) or whether the parent should be considered something that is intrinsic to the child.
In this case, the answer is the latter, for two reasons. The first has to do with the fact that the existence of the child is very much dependent upon the parent, but the existence of the parent is far less dependent upon the child. This existential dependency creates a hierarchy. This also provides a bit of a modeling exercise, in that a child will have (currently) have no more than two birth parents. Things may get a bit more complex when you talk about cloning or genetic manipulation, but for now, let's go with the most common use case. There's also a lesson here that modeling often requires making certain assumptions not because they are always true, but because where they are false is so rare that the users of a given system will never encounter it.
The second reason can be thought of as the principle of edge polarity minimization. Think of an outbound link into a resource as having a positive value, while an inbound link has a negative value. In a closed system (where all resources are connected to other resources), you may often have a number of outbound links, but those are due to the variety of such links - you have multiple properties tied to that same entity. Inbound links, on the other hand, usually tend to cluster around a limited number of properties, but each property may apply to a large number of entities.
Perhaps the most well known such relationship is the rdf:type relationship between an instance and it's class. You may have a great number of people in a Person class, but for any given person, there will typically only be one type (and you can make an argument that there should be only one type). A set relationship, by the above scheme, tends to be strongly negative, as classes typically have few properties (in OWL, they actually have zero properties, though this changes when you get into SHACL shapes).
Now, this point about negatives and positives is all relative to contexts. From the standpoint of the class, all those inbound link relationships make the class "node" very negative. From each instance node, of course, this relationship to the class makes it a little bit positive. If you were to add up the overall "charges" of this graph, however, the net charge will, of course, be zero.
This is where troll counting comes into play. One of the primary differences between a relational and a semantic model is the fact that, for a given row in a table in a relational model that has a foreign key reference, the row can only have one such reference to the same primary key table. In a semantic model, however, a given entity (which is not quite the same as a row, but close) you can have multiple foreign key references over the same relationship without have to repeat that row. You can have "lots" of such links, but in practice you probably don't want to. Instead, you might have one, two or even "many" (say a handful) but once you have a situation where you have multiple items along the same relationship axis, you face two problems.
First, you lose backwards compatibility with relational systems. If you have two foreign key references from the same resource, that means that you need two rows that specify the same object with different foreign keys, and that can add complexity to how you process your data, as this can cause problems with SELECT statements (which are tabular output) as well. The second is related - it means you spend a lot of time testing whether you are dealing with a single item or an array of items in downstream code, which adds some complexity.
If on the other hand, you limit yourself so that you can have only one such outbound link across any given predicate, then you always know that you're dealing with a singleton entry, while you can also work on the assumption that you have "lots" of inbound links, so they will always be arrays. As an example, consider the scenario where you have a person who owns two houses. In a naive modeling effort in RDF, you might describe this as follows:

The use of blank nodes here tends to obscure the fact that you're dealing with entities that have explicit types and should be referenceable but are not. This same expression can be written to make this more obvious:
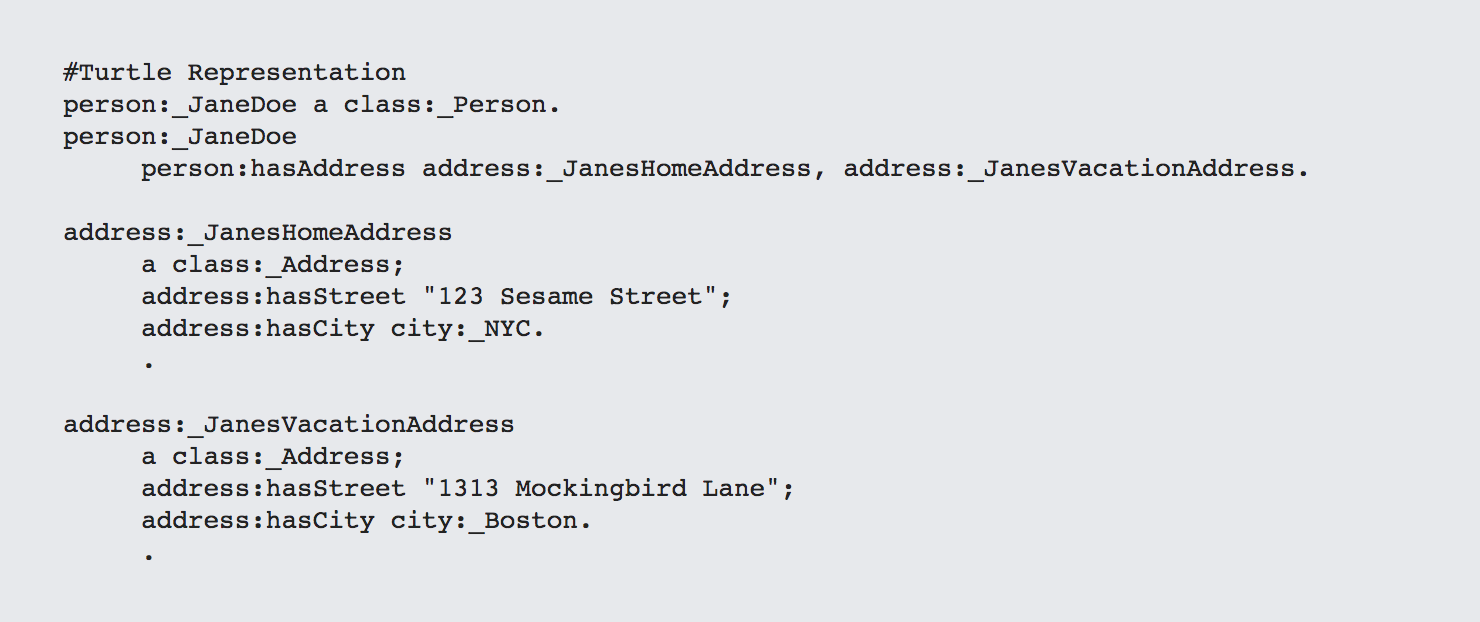
On the other hand, if you restrict yourself so that any outbound predicate has only one address, this changes in subtle but important ways.
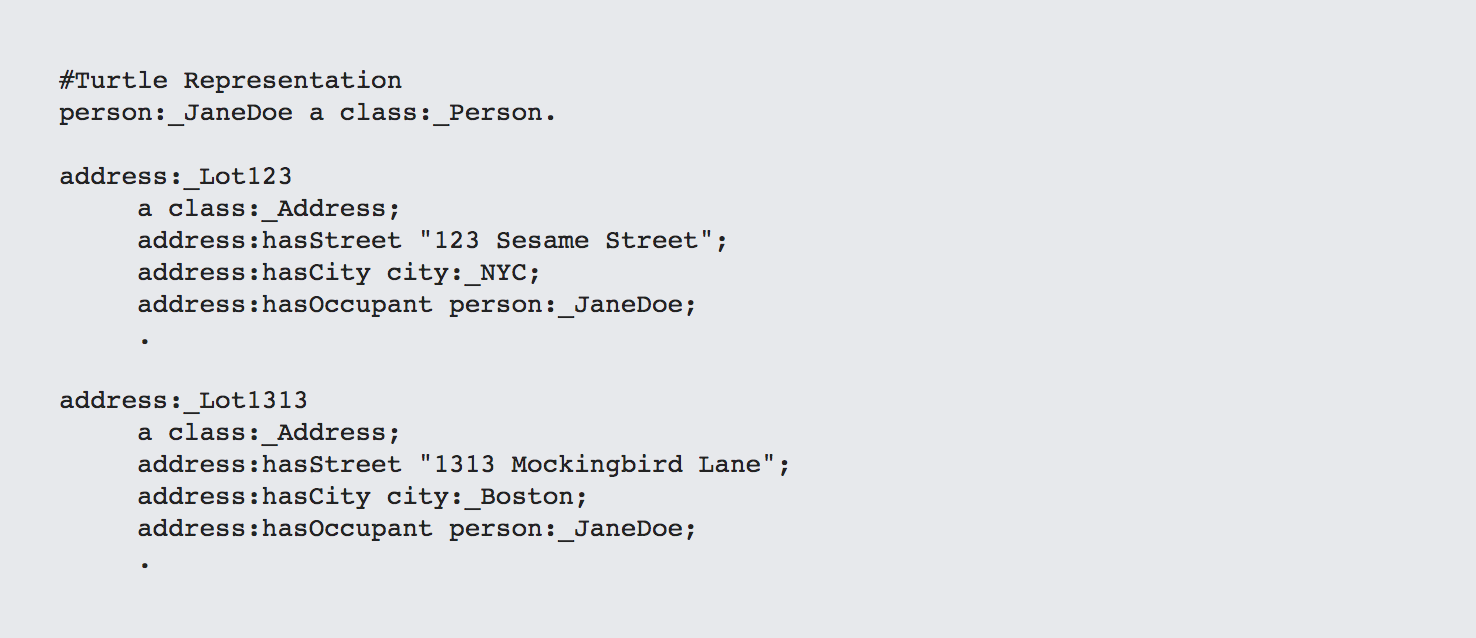
For starters, your LOTS (in this case address lots) will always be treated as an array, which means that you cut down on the complexity of your code in determining the cardinality of your resources (which can also simplify your interfaces). However, this doesn't make the problem completely go away. For instance, suppose that you added Jane's daughter Wendy into the mix:

Now you're into that same MANY business you faced before. This is when you realize that you have to normalize yet again:
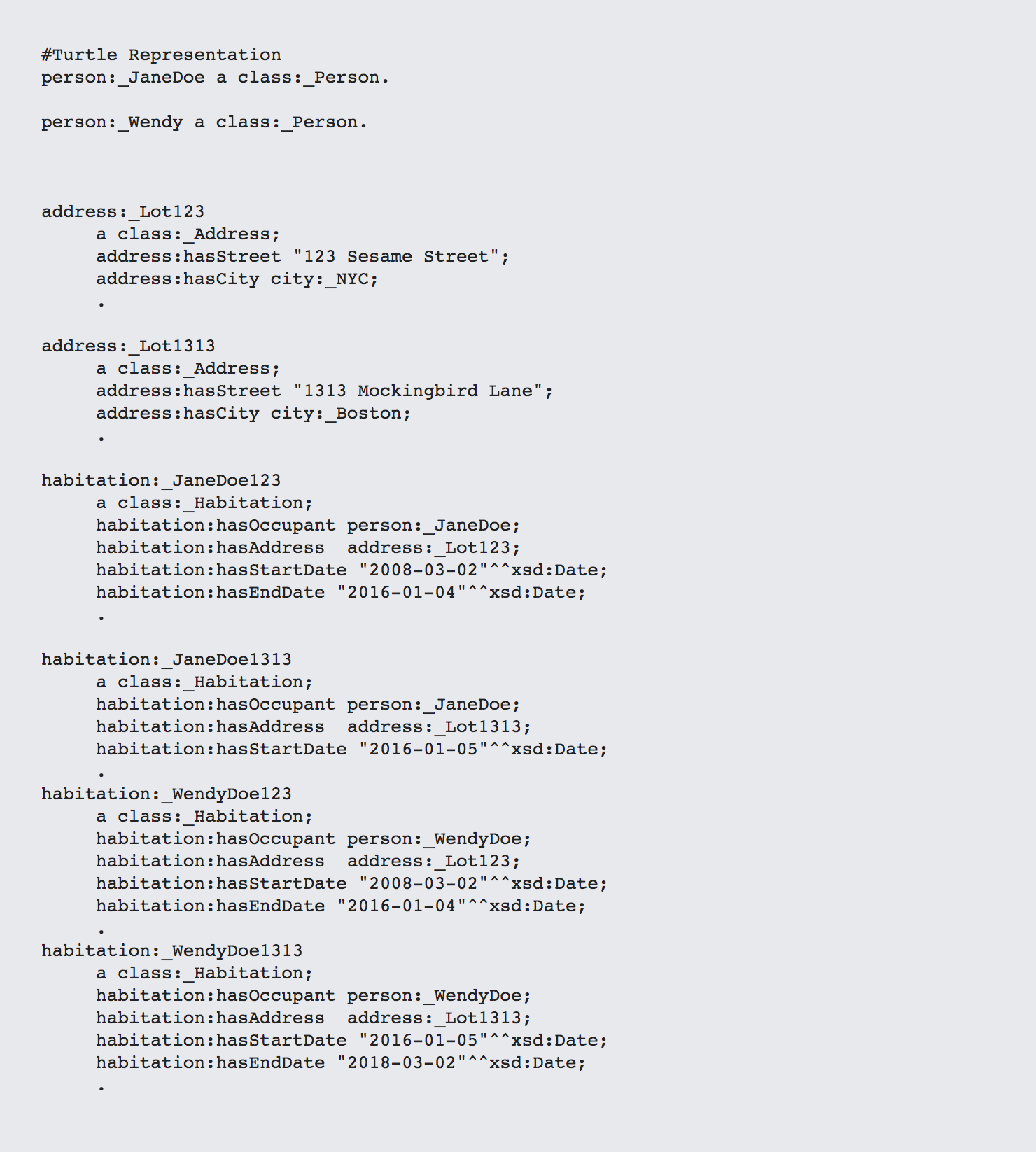
This is an example of what I call the contract pattern (aka 4th Normal Form), It occurs all the time in modeling, especially when dealing with temporal modeling (which is my justification for adding dates here). A habitation is a "contract" that links a person to an address over a period of time.
From the standpoint of both a person and an address, habitations are always going to be arrays that link into them. This makes it easy to pivot across different properties. For instance, the following shows all of the houses that Wendy Doe has lived in between 2010 and the present:
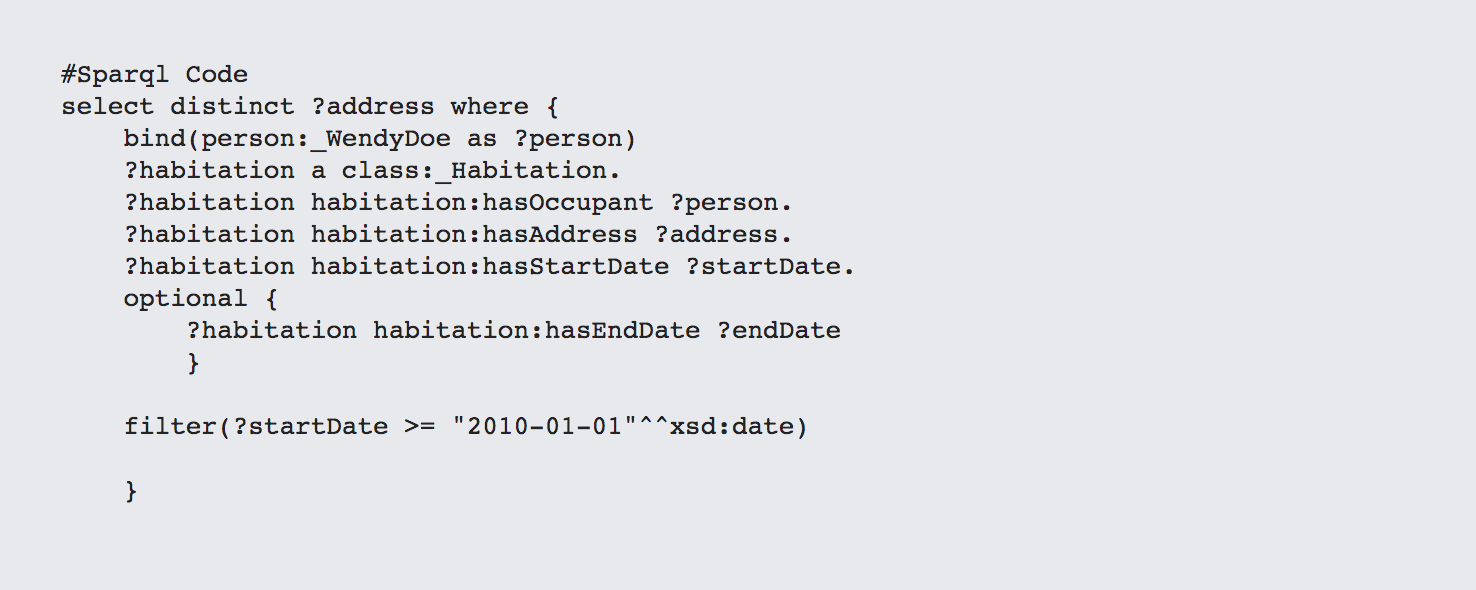
Here's the same code for determining who lived at a given address.
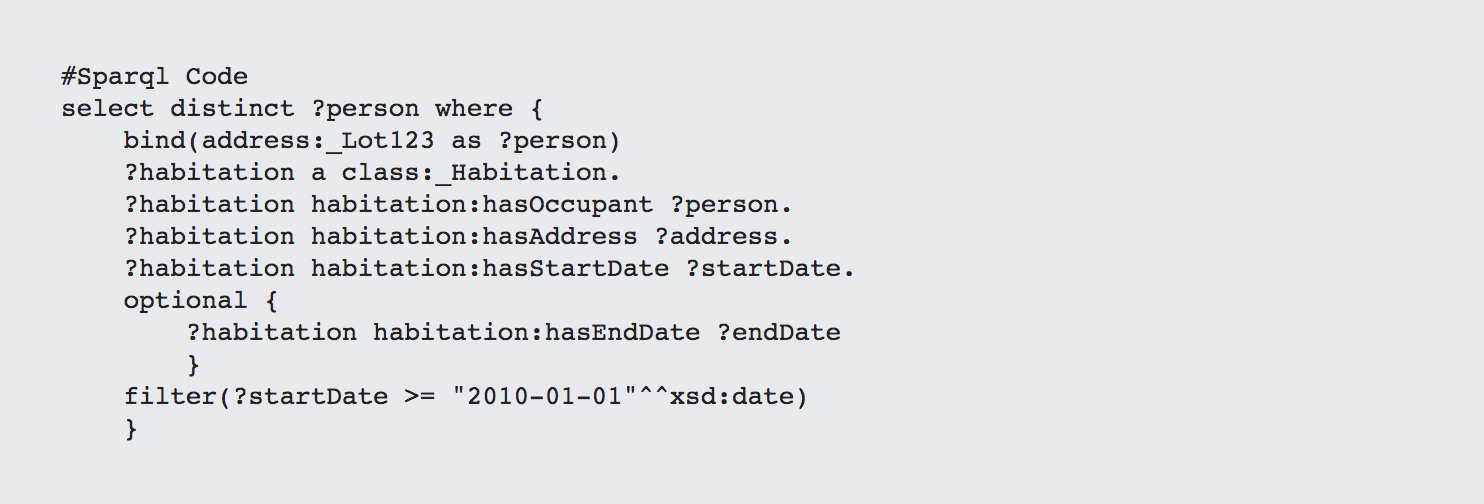
Notice that, with the exception of the initial bind and the select parameters, these are the same queries.
Contract patterns are ideal for working with faceting. For instance, if you wanted to find those addresses in which both Jane and Wendy were occupants at the same time, you'd use the query:
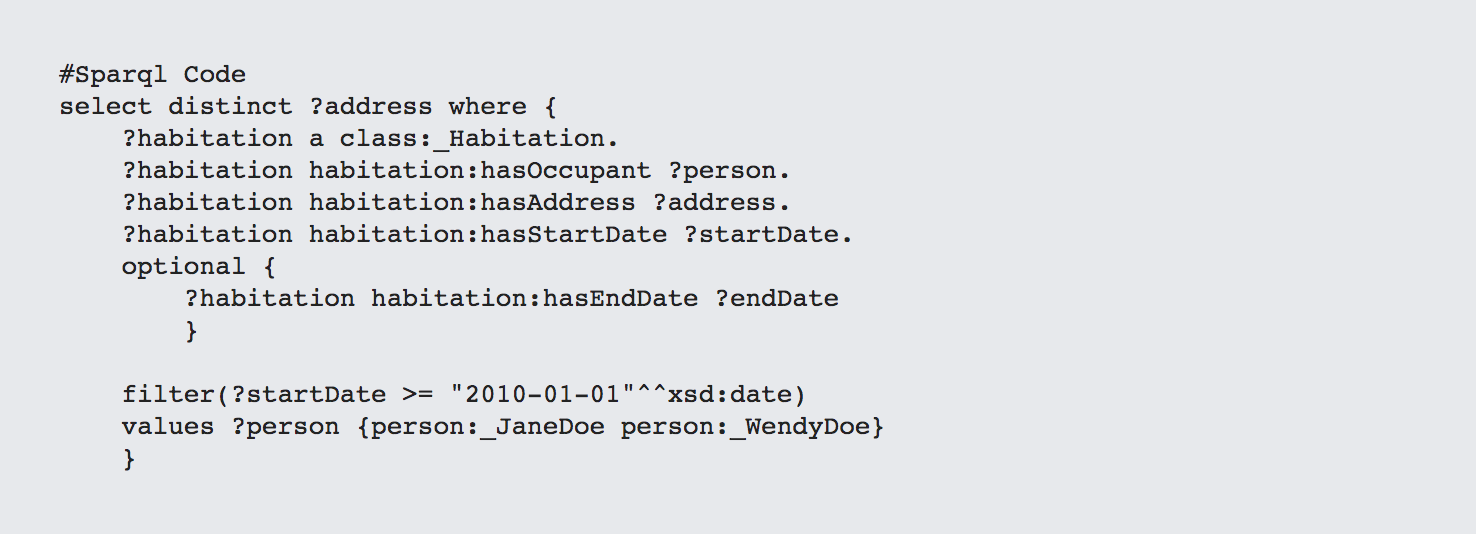
This is the equivalent of an OR statement that will show Jane's addresses, Wendy's addresses or both.
This does raise the question of whether there are actually situations where you need more than one outbound target for a given predicate. In the previous description talking about a child's biological parents, this might seem to be one of those cases:

but even here, you're better off with a singleton and splitting this into two distinct predicates:

This way, if you want to know Wendy's parents, you'd use the following SPARQL:
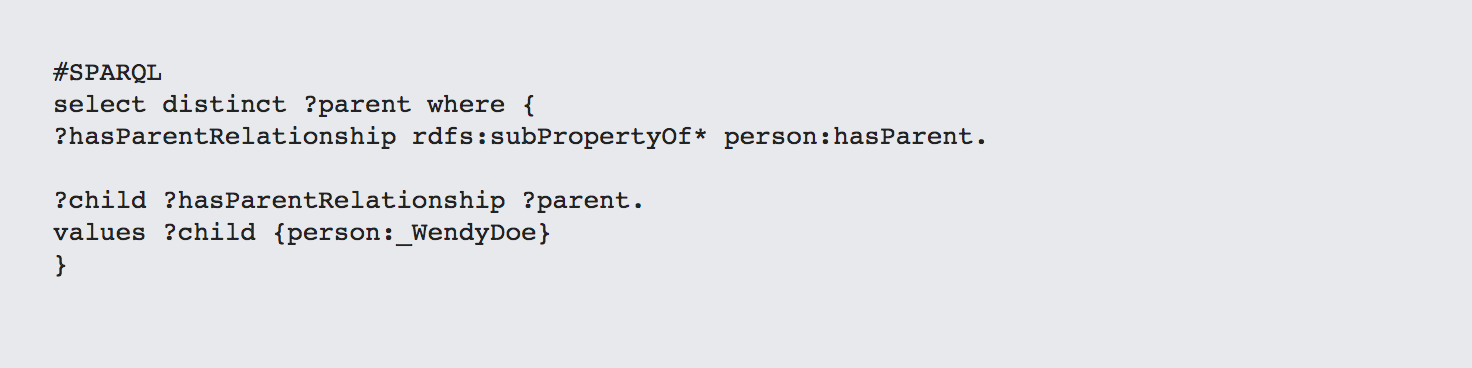
So long as the child shares some kind of relationship that descends from the person:hasParent relationship, this will work, but it can also be enhanced with a contract relationship:

This again turns a hierarchy into a faceted situation, in effect, replacing a property closure across refs:subPropertyOf with a class structure with multiple categorizations. Wendy Doe then, in this scenario, may have multiple parents of differing types (biological parents, step-parents, in loco parentis, adoptive parents, even informal parents). The SPARQL is also simpler.
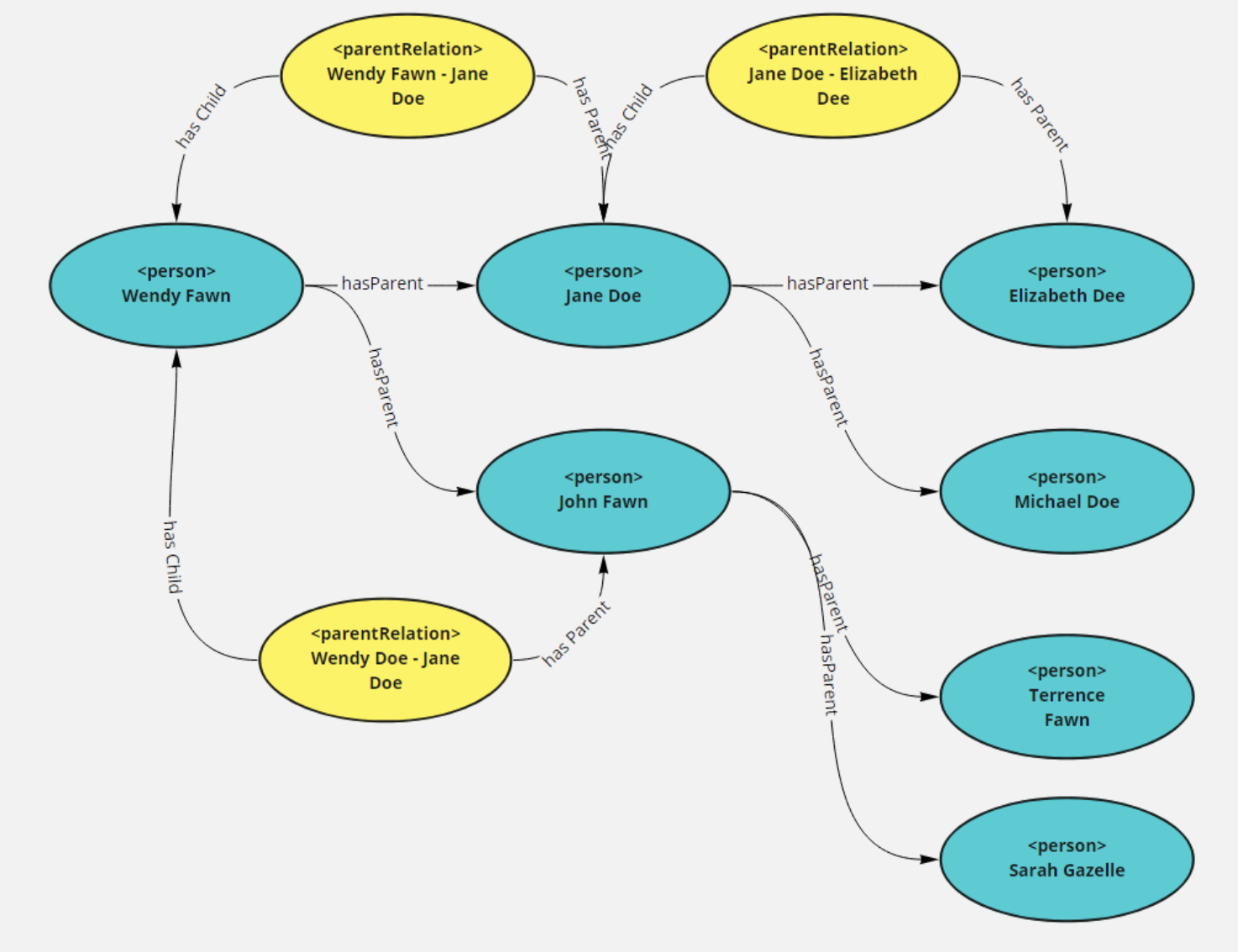

If you are looking for transitive closure, however, then you must also have a direct relationship (here person:hasParent).

The predicate person:hasParent+ will retrieve, through transitive closure, all parents from the starting child outward. It should be pointed out that this is one of the situations where you would end up with more than one potential outbound link, which means that if you are looking for hierarchies, you generally end up having to abandon backward compatibility with relational systems. This is definitely a case of MANY but not LOTS - a person may have multiple parents, but there will never be a very large number of them, and most of the time there will be only two.
One last note about linkages. If you have categorizations (such as parentalRelationship:hasType) then again, use outbound links if the categorization is exclusive (the resource has only one such type), but if you have many to one relationships, use contracts.
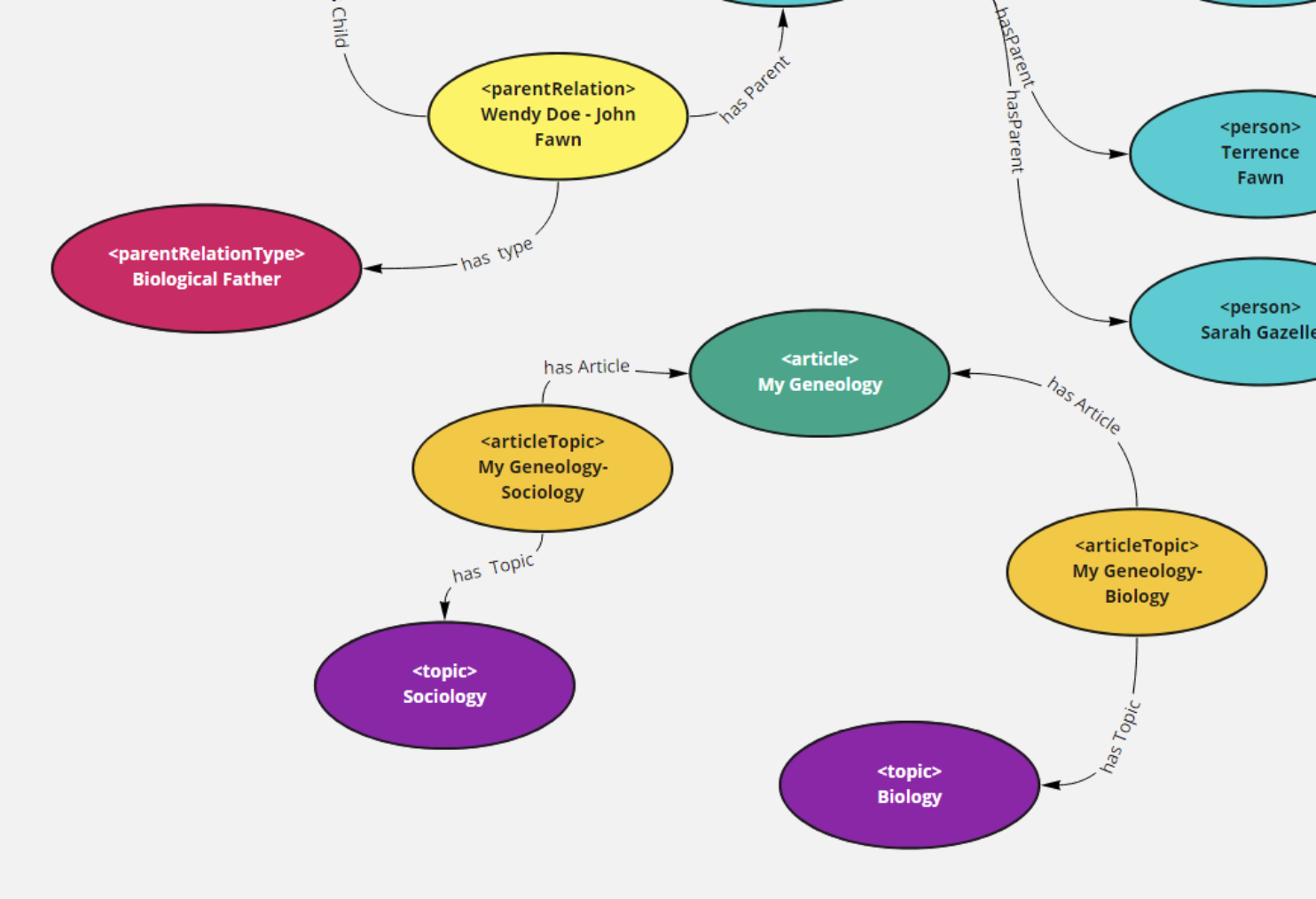
The advantages of using contracts for this kind of one to many relationships are the same as was given previously - you can attach additional metadata to such contracts such as the strength or relevance of a relationship, the author who made this association, additional annotation as to why such a topic is relevant, and, as significantly, it provides a way to keep from having potentially large numbers of outbound links on either articles or topics (in the example given in the illustration). It does come at a cost - contracts are transactions, and as such you will often have far more such transactions than you will base elements.
Again, the code for querying for a given article based on its faceted tags can be expressed using the contract:

This code would return those articles that touch on either sociology or biology (faceting), while replacing the values statement with the (commented out) filter statement would give you the intersection of those articles that incorporated both.
Perhaps the biggest lesson to come out of this is to always check your assumptions when dealing with cardinality, especially when dealing with either temporal issues or apparent hierarchies. As a general rule of thumb:
Contracts can help maintain normalization when you have many-to-many relationships that are rich on both sides, and can serve to keep your code backwaters compatible (in most cases) with relational databases.

Excellent article
Sounds about right
Thanks for the tips
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest