Comments (2)
Ilan Christopher
Brillant article, enjoyed reading your post.
Paul Butcher
This is a must read, thanks for sharing this good explanation.

Machine Learning is supplanting both Big Data and Data Scientist as marketing buzzwords, and as is typical, as it gains in popularity it also loses whatever more precise meaning that it had before. People tend to talk about machine learning without necessarily knowing precisely is being described, and see it as its own whole, separate discipline rather than being simply one aspect of a complex graph of related technologies.
Machine Learning is usually focused on the act of classification. Machine learning algorithms work in one of two ways. In the first, a curator provides a data-set of examplers, such as pictures of cats, dogs, foxes, rabbits, wolves, raccoons and so forth, along with an indicator about what class each particular example falls into. A visual classifier will typically do a color and edge analysis, will measure geometry of specific features and its orientation in space, and will then, based upon that, attempt to ascertain what cluster of characteristics most clearly matches, mathematically, the given sample.
This is by itself a very impressive achievement - a pug and a greyhound are both dogs, for instance, but, from a human perspective a pug has far more resemblance to certain varieties of flat-faced cats than they do to the long, rangy form of a greyhound,
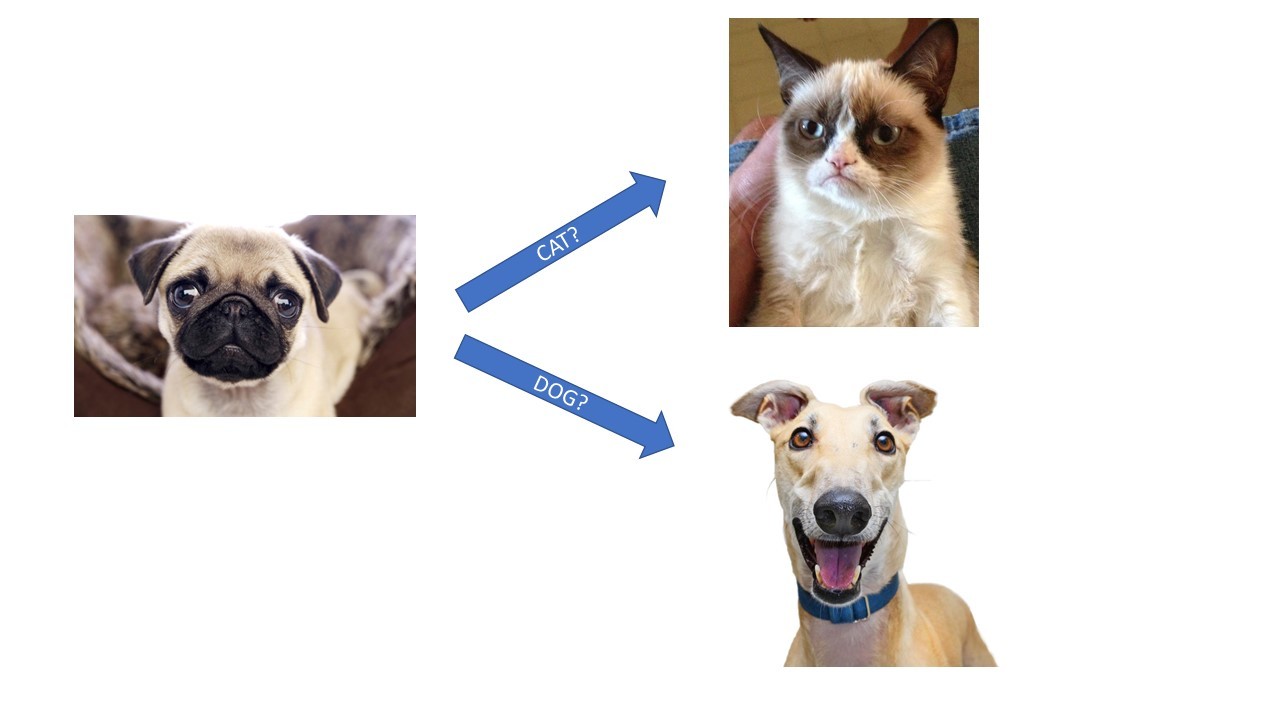
So what actually may happen is that such a classifier will create a class that identifies a pug as a member of the Pugs class, and then take from that the knowledge that when a pug is encountered, it "knows" that pugs are also classified as dogs.

This process of saying: "The animal in this picture is a pug. Pugs are a subclass of dogs. Therefore, this animal is a dog." is what's known as an inference. Inferences are important because they allow us to classify things based upon specific characteristics, then move from there to more general knowledge.
Semantics provides the formal logic to make such inferences by identifying the classifications and their relationships. I can readily identify a pug, or a Russian Blue cat, much more easily than I can create a generalized algorithm for identifying all dogs or all cats, so by identifying the semantics early (through the creation of vocabulary/grammar maps called ontologies), this can significantly shortcut the process of attempting to identify resources in general terms.
Now, not all machine learning requires "training" in the traditional sense. A data scientist can run an analysis on a set of data that identifies specific metrics (such as the ratio of two circles to a squiggly line) and can glean from this set common measurements. However, this sometimes also tends to surface things that have similar relationships that nonetheless normally have very little in common.

Even if there are no formal classifications, the definition of the metrics themselves constitute an ontology - a face algorithm, a body ratio algorithm, a color algorithm and so forth that can be seen as being a vocabulary, albeit one not expressed in a human language. Attributes within these "vocabularies" will fall into natural partitions based upon the tightness of the cluster indicator. For grumpy shape face, there will likely be a cluster of shapes that all have the same approximate dimensions that identifies the gf (grumpyFace) term. There may also be a happy face term (hf) and so forth, again that form clusters in a data space.
In such a generated classification scheme, semantics are still important, but at least some of the lower level semantics are machine generated. The role of the ontologist in those cases is to determine what the significance of the clustered partitions are, and to then relate this to human terms in another ontology. Here, the ontologist may identify the happy face, sad face, grumpy face, surprised face and similar terms and use these to then create an Emotional Face class with these as members. Note that these meanings are arbitrary based upon a human bias. A wolf baring its teeth, for example, may be excited, but it may also be about ready to attack.

The key point to remember in all of this is that regardless of whether a human being or a machine generates a specific vocabulary, semantics can in turn be used in conjunction with these machine-learning created classifications to help with inferences, to surface additional relationships that can be tied in with human known data. Machine learning can identify bones, but an ontologist still needs to identify the nomenclature of bones in a wolf or a cat first to tie this knowledge together, as one such example.
In other words, semantics and machine language should be seen as complementary disciplines, one providing the rubric for classification, the second taking the vectors that identify specific combinations of clusters and using those to fill in the most clearly defined categories so that they can then be related by the broader semantic system.


Brillant article, enjoyed reading your post.
This is a must read, thanks for sharing this good explanation.
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest