SPARQL is a powerful language for working with RDF triples.
However, SPARQL can also be difficult to work with, so much so that it often is not utilized anywhere near as often for its advanced capabilities, which include aggregating content, building URIs, and similar uses. This is the second piece in my exploration of OntoText's GraphDB database, but many of these techniques can be applied with other triple stores as well.
Tip 1. OPTIONAL and Coalesce()
These two keywords tend to be used together because they take both advantage of the Null value. In the simplest case, you can take advantage of coalesce to provide you with a default value. For instance, suppose that you have an article that may have an associated primary image, which is an image that is frequently used for generating thumbnails for social media. If the property exists, use it to retrieve the URL, but if it doesn't, use a default image URL instead.

With SPARQL, the OPTIONAL statement will evaluate a triple expression, but if no value is found to match that query then rather than eliminating the triple from the result set, SPARQL will set any unmatched variables to the value null. The coalesce statement can then query the variable, and if the value returned is null, will offer a replacement:
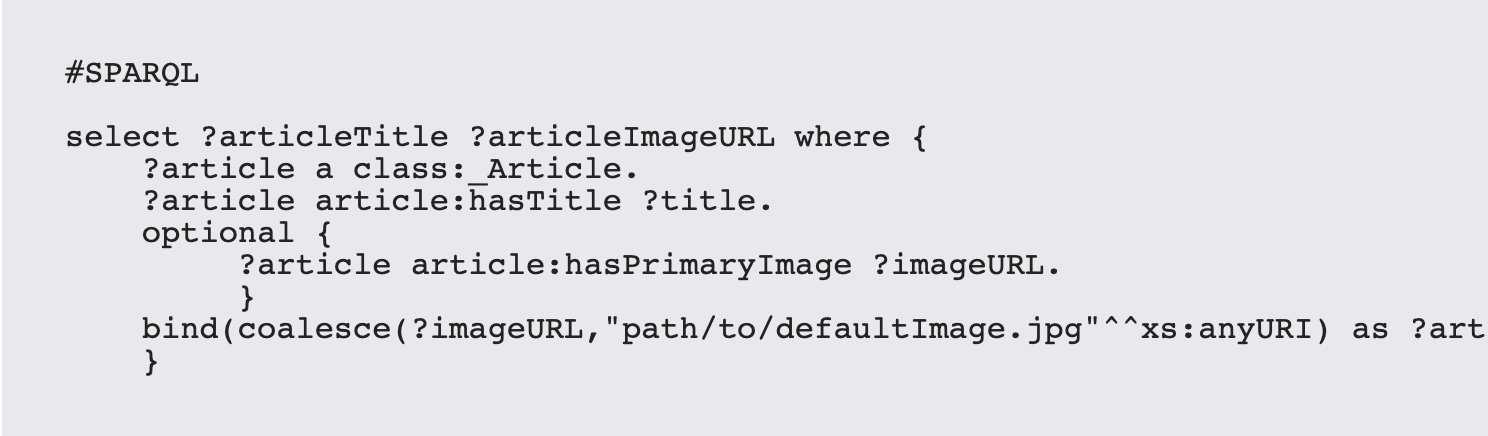
This in turn will generate a tuple that looks something like the following:
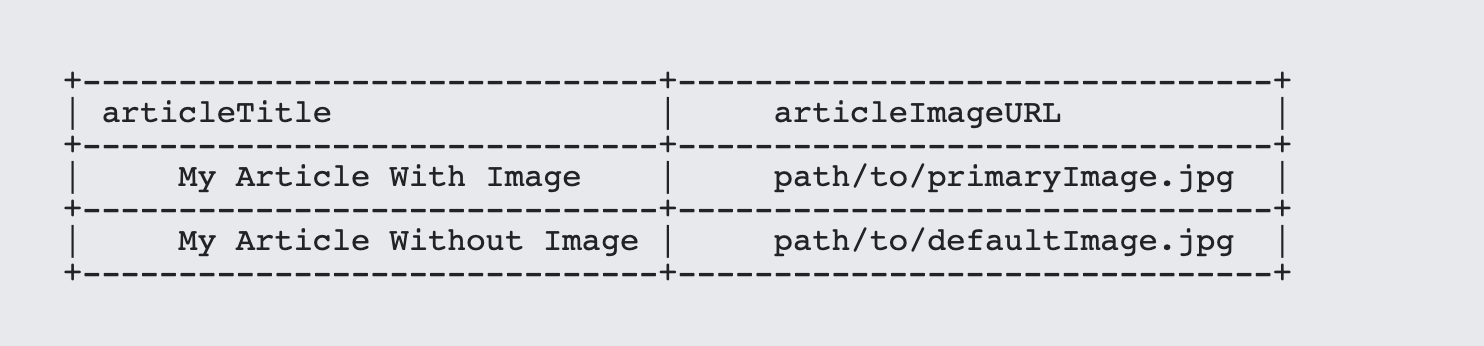
Coalesce takes an unlimited sequence of items and returns the first item that does not return a null value. As such you can use it to create a chain of precedence, with the most desired property appearing first, the second most desired after that and so forth, all the way to a (possible) default value at the end.
You can also use this to create a (somewhat kludgy) sweep of all items out a fixed number of steps:

The bound() function evaluates a variable and returns true() if the variable has been defined and false() otherwise, while the ! operator is the not operator - it flips the value of a Boolean from true to false and vice-versa. Note that if the filter expression evaluates to false(), this will terminate the particular scope. A bind() function will cause a variable to be bound, but so will a triple expression ... UNLESS that triple expression is within an OPTIONAL block and nothing is matched.
This approach is flexible but potentially slow and memory intensive, as it will reach out to everything with four hops of the initial node. The filter statements act to limit this: if you have a pattern node-null-null, then this should indicate that the object is also a leaf node, so no more needs to be processed. (This can be generalized, as will be shown below, if you're in a transitive closure situation).
Tip 2. EXISTS and NOT EXISTS
The EXISTS and NOT EXISTS keywords can be extraordinarily useful, but they can also bog down performance dramatically is used incorrectly. Unlike most operators in SPARQL, these two actually work upon sets of triples, returning true or false values respectively if the triples in question exist. For instance, if none of ?s, ?p or ?o have been established yet: the expression:

WILL cause your server to keel over and die. You are, in effect, telling your server to return all triples that don't currently exist in your system, and while this will usually be caught by your server engine's exception handler, this is not something you want to test.
However, if you do have at least one of the variables pinned down by the time this expression is called, these two expressions aren't quite so bad. For starters, you can use EXISTS and NOT EXISTS within bind expressions. For example, suppose that you wanted to identify any orphaned link, where an object in a statement does not have a corresponding link to a subject in another statement:

In this particular case, only those statements in which the final term is not a literal (meaning those for which the object is either an IRI or a blank node) will be evaluated, The bind statement then looks for the first statement in which the ?o node is a subject in some other statement, the EXISTS keyword then returns true if at least one statement is found, while the ! operator inverts the value. Note that EXISTS only needs to find one statement to be true, while NOT EXISTS has to check the whole database to make sure that nothing exists. This is equivalent to the any and all keywords in other languages. In general, it is FAR faster to use EXISTS this way than to use NOT EXISTS.
Tip 3. Nested IF statements as Switches (And Why You Don't Really Need Them)
The SPARQL if() statement is similar to the Javascript condition?trueExpression:falseExpression operator, in that it returns a different value based upon whether the condition is true or false. While the expressions are typically literals, there's nothing stopping you from using object IRIs, which can in turn link to different configurations. For instance, consider the following Turtle:

You can then make use of the if() statement to retrieve the configuration:

where the expression () returns a null value.
Of course, you can also use a simple bit of Sparql to infer this without the need for the if statement:

with the results:

As a general rule of thumb, the more that you can encode as rules within the graph, the less that you need to rely on if or switch statements and the more robust your logic will be. For instance, while a dogs and cats express themselves in different ways most of the time, both of them can growl:

Turtle

In this case, the switch statement would break, as Growl is not in the options, but the direct use of SPARQL works just fine.
Tip 4. Unspooling Sequences
Sequences, items that are in a specific order, are fairly easy to create with SPARQL but surprisingly there are few explanations for how to build them . . . or query them. Creating a sequence in Turtle involves putting a list of items in between parenthesis as part of an object. For instance, suppose that you have a book that consists of a preface, five numbered chapters, and an epilogue. This would be expressed in Turtle as:

Note that there are no commas between each chapter.
Now, there is a little magic that Turtle parsers do in the background when parsing such sequences. They actually convert the above structure into a string with blank nodes, using the three URIs rdf:first, rdf:rest and rdf:nil. Internally, the above statement looks considerably different:
While this looks daunting, programmers might recognize this as being a very basic linked list, whether rdf:first points to an item in the list, and rdf:rest points to the next position in the list. The first blank node, _:b1, is then a pointer to the linked list itself. The rdf:nil is actually a system defined URI that translates into a null value, just like the empty sequence (). In fact, the empty sequence in SPARQL is in fact the same thing as a linked list with no items and a terminating rdf:nil.
Since you don't know how long the list is likely to be (it may have one item, or thousands) building a query to retrieve the chapters in their original order would seem to be hopeless. Fortunately, this is where transitive closure and property paths come into play. Assume that each chapter has a property called chapter:hasTitle (a subproperty of rdfs:label). Then to retrieve the names of the chapters in order for a given book, you'd do the following:

SPARQL
That's it. The output, then, is what you'd expect for a sequence of chapters:

The property path rdf:rest*/rdf:first requires a bit of parsing to understand what is happening here. property* indicates that, from the subject, the rdf:rest path is traversed zero times, one time, two times, and so forth until it finally hits rdf:nil. Traversing zero times may seem a bit counterintuitive, but it means simply that you treat the subject as an item in the traversal path. At the end of each path, the rdf:first link is then traversed to get to the item in question (here, each chapter in turn. You can see this broken down in the following table:

If you don't want to include the initial subject in the sequence, then use rdf:rest+/rdf:first where the * and + have the same meaning as you may be familiar with in regular expressions, zero or more and one or more respectively.
This ability to traverse multiple repeating paths is one example of transitive closure. Transitive closures play a major role in inferential analysis and can easily take up a whole article in its own right, but for now, it's just worth remembering the ur example - unspooling sequences.
The ability to create sequences in TURTLE (and use them in SPARQL) makes a lot of things that would otherwise be difficult if not impossible to do surprisingly easy.
As a simple example, suppose that you wanted to find where a given chapter is in a library of books. The following SPARQL illustrates this idea:

This is important for a number of reasons. In publishing in particular there's a tendency to want to deconstruct larger works (such as books) into smaller ones (chapters), in such a way that the same chapter can be utilized by multiple books. The sequence of these chapters may vary considerably from one work to the next, but if the sequence is bound to the book and the chapters are then referenced there's no need for the chapters to have knowledge about its neighbors. This same design pattern occurs throughout data modeling, and this ability to maintain sequences of multiply utilized components makes distributed programming considerably easier.
Tip 5. Utilizing Aggregates
I work a lot with Microsoft Excel documents when developing semantic solutions, and since Excel will automatically open up CSV files, using SPARQL to generate spreadsheets SHOULD be a no brainer.
However, there are times where things can get a bit more complex. For instance, suppose that I have a list of books and chapters as above, and would like for each book to list it's chapters in a single cell. Ordinarily, if you just use the ?chapterTitle property as given above, you'll get one line for each chapter, which is not what's wanted here:

This is where aggregates come into play, and where you can tear your hair out if you don't know the Ninja Secrets. To make this happen, you need to use subqueries. A subquery is a query within another query that calculates output that can then be pushed up to the calling query, and it usually involves working with aggregates - query functions that combine several items together in some way.
One of the big aggregate workhorses (and one that is surprisingly poorly documented) is the concat_group() function. This function will take a set of URIs, literals or both and combine them into a single string. This is roughly analogous to the Javascript join() function or the XQuery string-join() function. So, to create a comma separated list of chapter names, you'd end up with a SPARQL script that looks something like this:

The magic happens in the inner select, but it requires that the SELECT statement includes any variable that is passed into it (here ?book) and that the same variable is echoed in the GROUP BY statement after the body of the subquery.
Once these variables are "locked down", then the aggregate functions should work as expected. The first argument of the group_concat function is the variable to be made into a list. After this, you can have multiple optional parameters that control the output of the list, with the separator being the one most commonly used. Other parameters can include ROW_LIMIT, PRE (for Prefix string), SUFFIX, MAX_LENGTH (for string output) and the Booleans VALUE_SERIALIZE and DELIMIT_BLANKS, each separated by a semi-colon. Implementations may vary depending upon vendor, so these should be tested.
Note that this combination can give a lot of latitude. For instance, the expression:

will generate an HTML list sequence, and similar structures can be used to generate tables and other constructs. Similarly, it should be possible to generate JSON content from SPARQL through the intelligent use of aggregates, though that's grist for another article.
The above script also illustrates how a count function has piggy-backed on the same subquery, in this case using the COUNT() function.
It's worth mentioning the spif:buildString() function (part of the SPIN Function library that is supported by a number of vendors) which accepts a string template and a comma-separated list of parameters. The function then replaces each instance of "{?1}","{?2}", etc. with the parameter at that position (the template string being the zeroeth value). So a very simple report from above may be written as

which will create the following ?report string:

This templating capability can be very useful, as templates can themselves be stored as resource strings, with the following Turtle:

This can then be referenced elsewhere:

With output looking something like the following:

This can be extended to HTML-generated content as well, illustrating how SPARQL can be used to drive a basic content management system.
Tip 6. SPARQL Analytics and Extensions
There is a tendency among programmers new to RDF to want to treat a triple store the same way that they would a SQL database - use it to retrieve content into a form like JSON and then do the processing elsewhere. However, SPARQL is versatile enough that it can be used to do basic (and not so basic) analytics all on its own.
For instance, consider the use case where you have items in a financial transaction, where the items may be subject to one of three different types of taxes, based upon specific item details. This can be modeled as follows:

This is a fairly common real world scenario, and the logic for handling this in a traditional language, while not complex, is still not trivial to determine a total price. In SPARQL, you can again make use of aggregate functions to do things like get the total cost:

While this is a simple example, weighted cost sum equations tend to make up the bulk of all analytics operations. Extending this to incorporate other factors such as discounts is also easy to do in situ, with the following additions to the model:
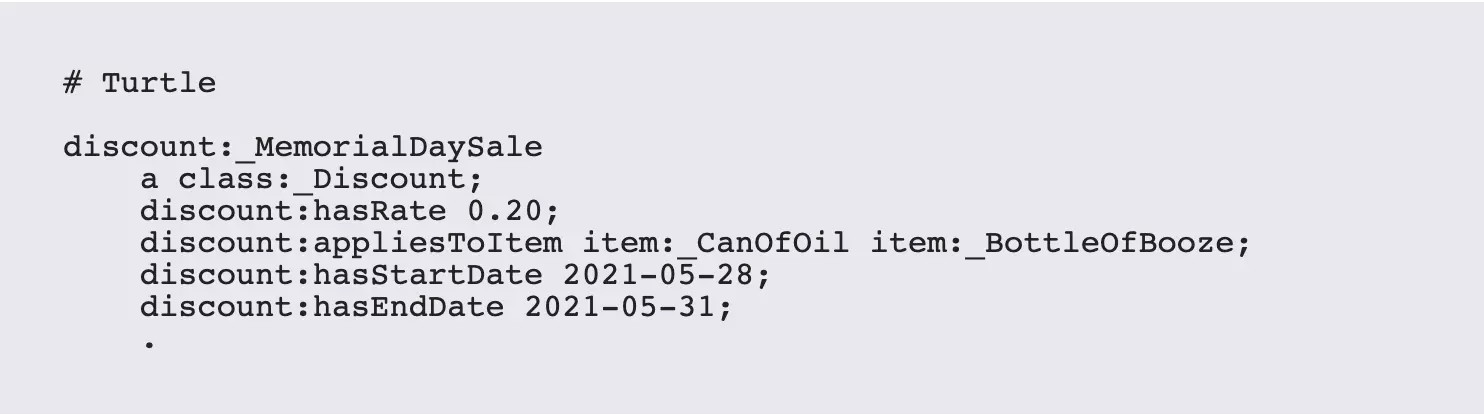
This extends the SPARQL query out a bit, but not dramatically:

In this particular case, taxes are required, but discounts are optional. Also note that the discount price is only applicable around Memorial Day weekend, with the filter set up in such a way that ?DiscountRate would be null at any other time. The conditional logic required to support this externally would be getting pretty hairy at this point, but the SPARQL rules extend it with aplomb.
There is a lesson worth extracting here: use the data model to store contextual information, rather than relying upon outside algorithms. It's straightforward to add another discount period (a sale, in essence) and with not much more work you can even have multiple overlapping sales apply on the same item.
Summary
The secret to all of this: these aren't really Ninja secrets. SPARQL, while not perfect, is nonetheless a powerful and expressive language that can work well when dealing with a number of different use cases. By introducing sequences, optional statements, coalesce, templates, aggregates and existential statements, a good SPARQL developer can dramatically reduce the amount of code that needs to be written outside of the database. Moreover, by taking advantage of the fact that in RDF everything can be a pointer, complex business rules can be applied within the database itself without a significant overhead (which is not true of SQL stored procedures).
So, get out the throwing stars and stealthy foot gloves: It's SPARQL time!
Kurt Cagle is the community editor for Data Science Central, and the editor of The Cagle Report.


Leave your comments
Post comment as a guest