Comments
- No comments found

Artificial intelligence has quickened its progress across vaccines, autonomous vehicles, language processing, and quantum computing.
The Covid-19 crisis resulted in the acceleration of artificial intelligence and deep learning breakthroughs.
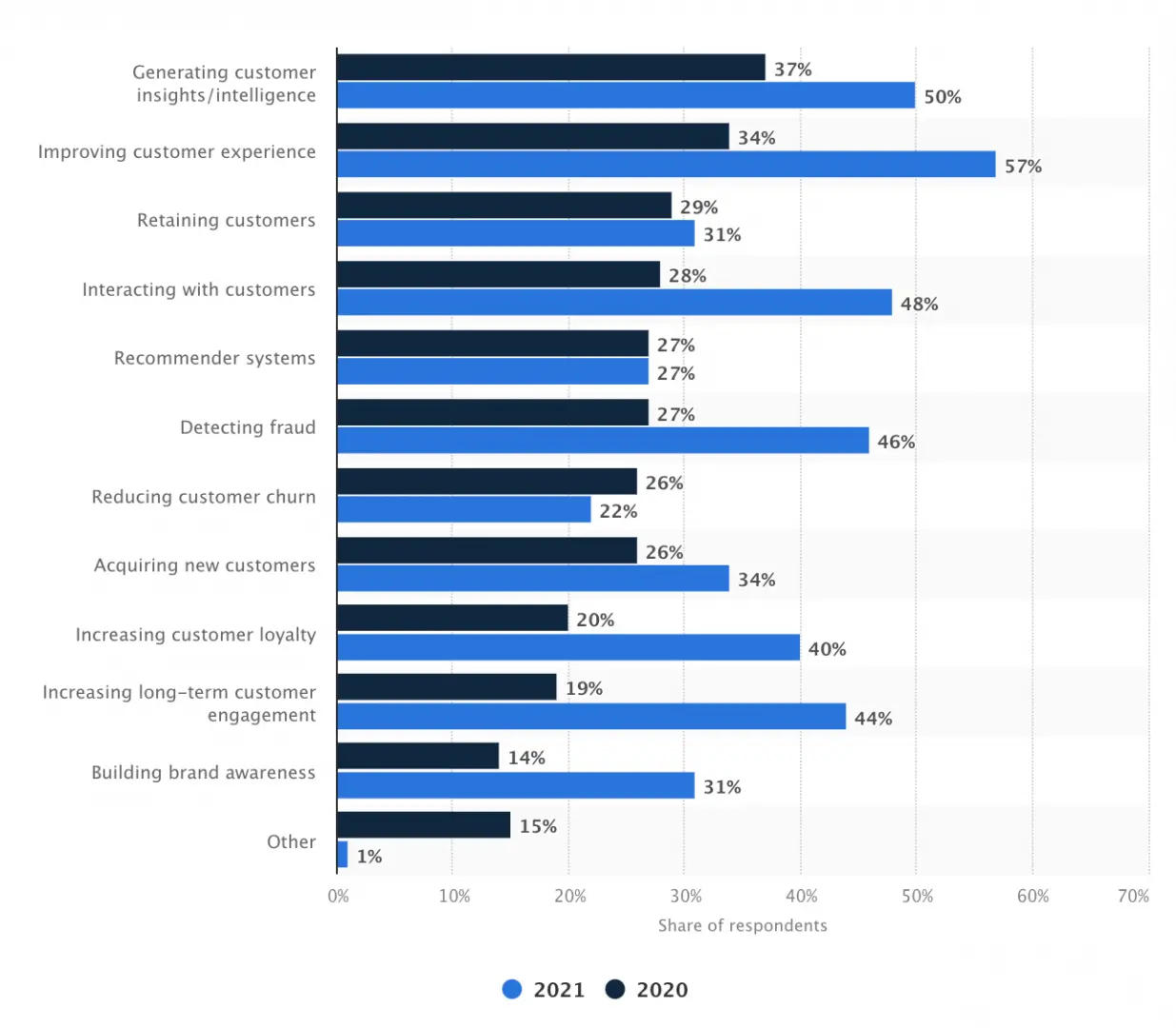
Source: Statista
Online activity has gained momentum during the pandemic and is set to continue as increasing numbers of the population become accustomed to online activity whether for work, retail, education, healthcare, banking, or entertainment.

Source for the image above Intel Ovum: Intel Study Finds 5G will Drive $1.3 Trillion in New Revenues in Media and Entertainment Industry by 2028
As noted above, the impact of Covid-19 crisis has been to accelerate the process of digital transformation.
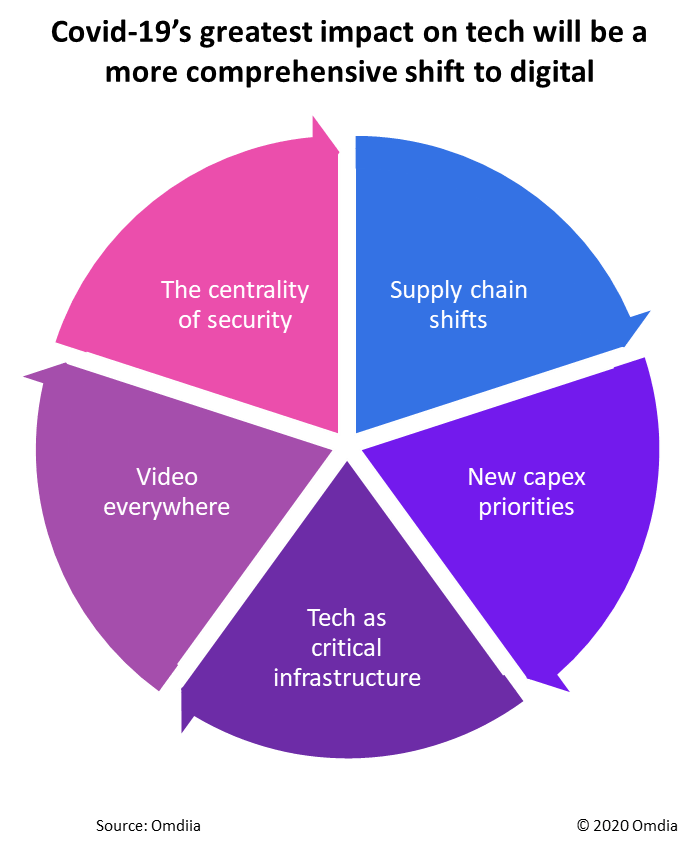
Source for image above: Omdia COVID-19 triggers accelerated shift to digital technologies and services
Furthermore, McKinsey in Digital strategy in a time of crisis note that "As the COVID-19 crisis forces your customers, employees, and supply chains into digital channels and new ways of working, now is the time to ask yourself: What are the bold digital actions we’ve hesitated to pursue in the past, even as we’ve known they would eventually be required? Strange as it may seem, right now, in a moment of crisis, is precisely the time to boldly advance your digital agenda."
"What does it mean to act boldly? We suggest four areas of focus, each of which goes beyond applying “digital lipstick” and toward innovating entirely new digital offerings, deploying design thinking and technologies like artificial intelligence (AI) at scale across your business, and doing all of this “at pace” through acquisitions (Exhibit 2 from McKinsey below)."
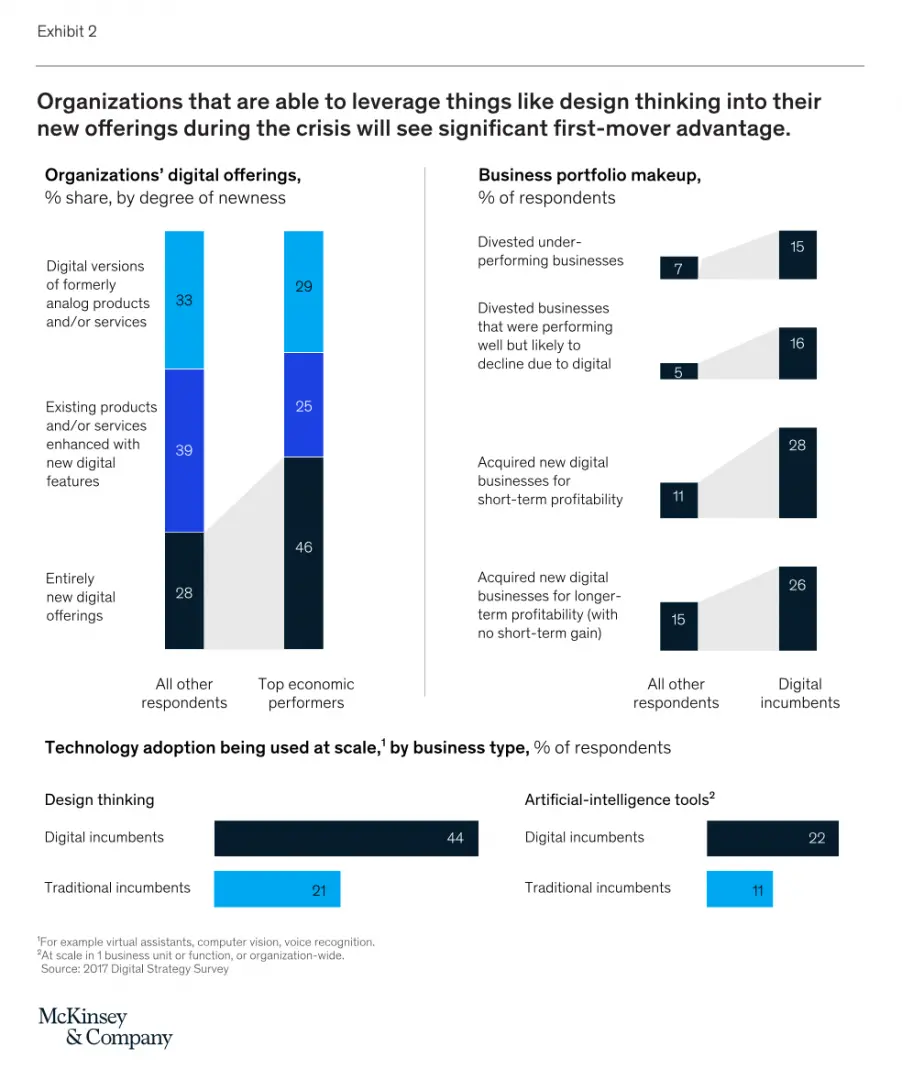
Source for image above: McKinsey & Company Digital strategy in a time of crisis
The era of 5G and Edge Computing will accelerate the momentum of Digital Transformation even further with the Fourth Industrial Revolution resulting in new products and services that we may not even imagine today.
The era of 5G and an intelligent IoT will also require more AI on the Edge (on Device) as we enable a work of genuine personalisation and real-time engagement and analytics with the end user (customer or you and me!).
In order for such engagement to be successful and also to scale AI across multiple sectors of the economy and across the AIIoT we'll need to engage in more R&D for more efficient types of AI (in particular Deep Learning) that will result in a more efficient training and learning processes. This article will provide examples of such types of AI and the Covid-19 crisis highlights the need for both more Digital Transformation to enable customers to have a truly fulfilling digital experience and also greater scaling of AI to enable that goal.
The AIIoT is defined as a merger between the Internet of Things (IoT) and AI technology so that we can make sense of the vast amount of data that will be generated and also generate meaningful customer experiences or actions in industry and healthcare that are effective and efficient.
For the customer, 5G enabled AR glasses combined with AI technology will result in transformative experiences with the physical and digital world merging into one that we have only just started to imagine. Next generation mobile phones and forthcoming AR smart glasses will require AI on the Edge.
The scaling of 5G networks and growth of Edge Computing across connected devices will also result in an increase in Cyber Security Threats. Tom Wheeler and David Simpson noted in Brookings "Why 5G requires new approaches to cybersecurity" observed that "As we pursue the connected future, however, we must place equivalent—if not greater—focus on the security of those connections, devices, and applications.”
The authors also note that the implementation of Machine Learning and AI protection will be one of the key means to secure the network 5G and Edge Computing era as "Cyberattacks on 5G will be software attacks; they must be countered with software protections. During a Brookings-convened discussion on 5G cybersecurity, one participant observed, “We’re fighting a software fight with people” whereas the attackers are machines."
The authors also state that "“None of this suggests that we suspend the march to the benefits of 5G. It does, however, suggest that our status quo approach to 5G should be challenged.”
The benefits that we will gain across the economy include new products and services that will enable true personalisation with growth and new employment opportunities across the economy as a new wave of business emerge whilst also allowing for a cleaner future.
According to TechHQ Apple thinks AR glasses will replace smartphones which is something that I believe will happen during the course of this decade. Facebook, Microsoft, Samsung and Google are also working on their own 5G enabled AR glasses too. It may well be that the era of 5G will be defined by smart glasses.
Source for image above: BringPortal Apple Glasses – Sleek as Hell Smart Glasses by Apple
The need for efficient training and ongoing learning for real-time on the fly interactions by autonomous systems or responses by devices to customers means that the types of research in AI that is dealt with in the article below will be of paramount importance over the next 2 to 5 years. A future article will consider updates in the research side within this area.
As observed above we need a mandate to be bold and to emerge from the Covid-19 crisis with a Digital Transformation pathway that leaves us stronger, smarter and growing our economies on a cleaner pathway. The time for change has come and it is time to be bold.
This article will mention a couple of research papers from Massachusetts Institute of Technology (MIT) relating to smarter training of Deep Neural Networks and novel approaches to Deep Neural Networks.
Artificial Neural Networks are biologically inspired networks that extract abstract features from the data in a hierarchical fashion. Deep Learning refers to the field of Neural Networks with several hidden layers. Such a neural network is often referred to as a Deep Neural Network.
Each neuron within the network receives inputs from other neurons and then calculates a weighted average of the inputs with the relative weighting of the various inputs guided by the previous experience.
The field of Deep Learning has been responsible for a number of significant advancements in the field of AI over the past decade.
For example in 2012, a team led by Dahl won the Merck Molecular Activity Challenge using multi-task deep neural networks to predict the biomolecular target of one drug. The research paper by Dahl et al. Multi-task Neural Networks for QSAR Predictions was published in 2014.
A study by NVIDIA reported that Deep Learning Drops Error Rate for Breast Cancer Diagnoses by 85%. The study observed that "human analysis combined with Deep Learning results achieved a 99.5 percent success rate. This shows pathologist performance can be improved when paired with AI systems, signalling an important advance in identifying and treating cancer."
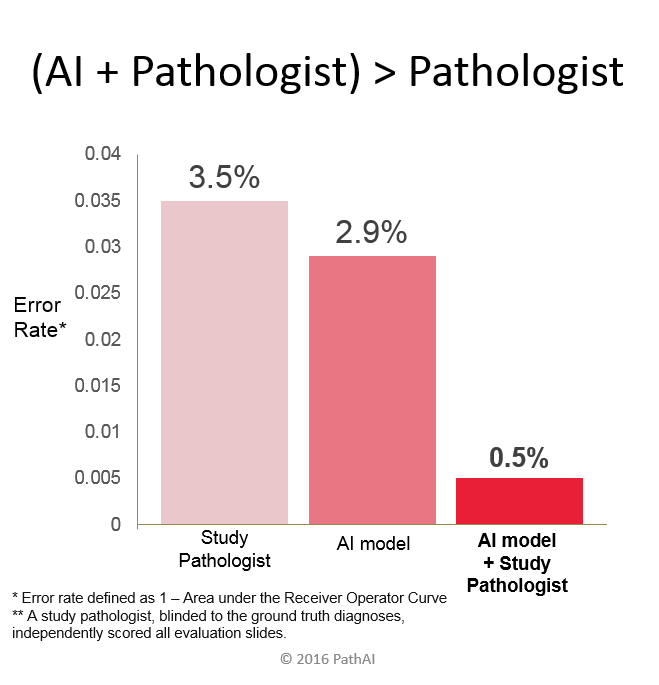
Research from Stanford University published in Nature in 2017 by Esteva et al. showed that a "Convolutional Neural Network (CNN) achieves performance on par with all tested experts...demonstrating an artificial intelligence capable of classifying skin cancer with a level of competence comparable to dermatologists."
JP Morgan observed that "Deep Learning systems will undertake tasks that are hard for people to define but easy to perform"
As Tomasz Czech noted in Deep learning: the next frontier for money laundering detection "The deeper money gets into the banking system, the more difficult it is to identify its origin. One of the technologies that have gained recognition in recent years is deep machine learning, being a subset of modern AI."
An excellent article by By Roger Parlof entitled Why Deep Learning is Suddenly Changing Your Life sets out the impact that Deep Learning has been having in different sectors of the economy including in the medical field.
A blog that I published, Using AI with Explainable Deep Learning To Help Save Lives, demonstrated the potential of using explainable the practical application of Deep Learning technology to medical imaging with the potential to alleviate the stress on the health care system whilst providing for better outcomes for the individual patient.
An article entitled Using AI to predict breast cancer and personalize care set out recent research from MIT Computer Science and Artificial Intelligence Laboratory (CSAIL), and Massachusetts General Hospital (MGH), entailed developing a Deep Learning model to predict the likelihood of a patient developing breast cancer from a mammogram. The model was trained on outcomes that were known and mammograms from in excess of 60,000 patients who had been treated at MGH with the model learning the particular patterns in the breast tissue that are precursors to malignancy. The paper published 7th May 2019 is entitled A Deep Learning Mammography-based Model for Improved Breast Cancer Risk Prediction.
However a challenge with scaling Deep Learning to wider use cases and applications has been to reduce the amount of labelled data needed for successfully training a Deep Neural Network. Reducing the amount of training data needed for Deep Neural Networks has potential to widen the application and adoption of Deep Learning across verticals such as finance and health care where at times access to large data sets can be a challenge.
Furthermore, there will be exciting potential for IoT based applications on the edge as 5G rolls out over the next few years. The initial roll out of 5G telecoms networks from 2019 onwards (depending upon where exactly one happens to be located) will be a key enabler for autonomous systems and edge computing with Ultra Reliable and Low Latency Communications (URLLC) allowing for a reduced latency of 1 millisecond.
Projection of interrelated 5G service tiers, Image Source :International Telecommunications Union.
The next generation of applied AI development will be increasingly about techniques that enable Deep Learning to be efficiently deployed in edge computing (on device) as the era of 5G emerges with autonomous systems and machine to machine communication requiring the AI to be deployed closer to where the data is created and processed.
An article in VentureBeat entitled Why AI and edge computing is capturing so much attention observed that "Sophisticated machine learning models on the edge will impact video frames, speech synthesis, and both time-series unstructured data that’s generated by sensors, cameras, and microphones. In other words, voice assistants get smarter, photography and video shooting get more sophisticated, cars get safer, data security gets better, and robotics — both consumer and industrial — take innovative leaps. Health care outcomes improve."
A good example is provided by Zak Doffman in an article published on Forbes, Network Effects: In 2019 IoT And 5G Will Push AI To The Very Edge, where in relation to an autonomous vehicle, Edge Analytics and AI, Doffman states “The largely, but not exclusively, video-based processing of the road and its surroundings, including traffic, pedestrians and fixed objects, has to be processed in the car itself... An autonomous vehicle has an absolute imperative to complete its defined journey safely and efficiently.”
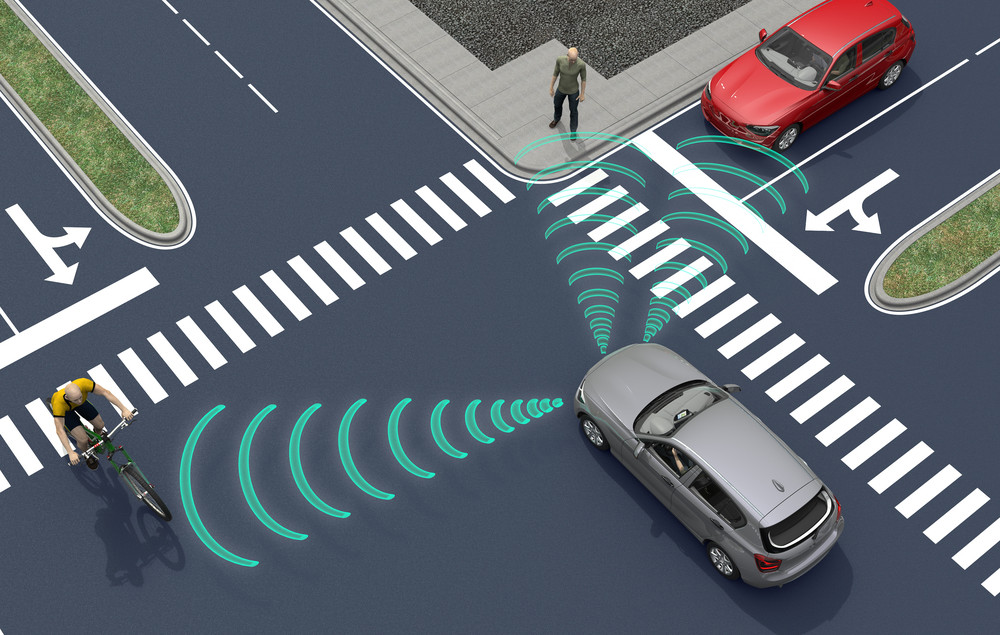
In simple terms an autonomous vehicle or drone waiting for a cloud server to respond to enable a decision on whether to turn left or right would have potentially fatal consequences.
AI on the edge is forecast to grow very rapidly with Tractica forecasting that AI edge device shipments will increase from 161.4 million units in 2018 to 2.6 billion units worldwide annually by 2025.
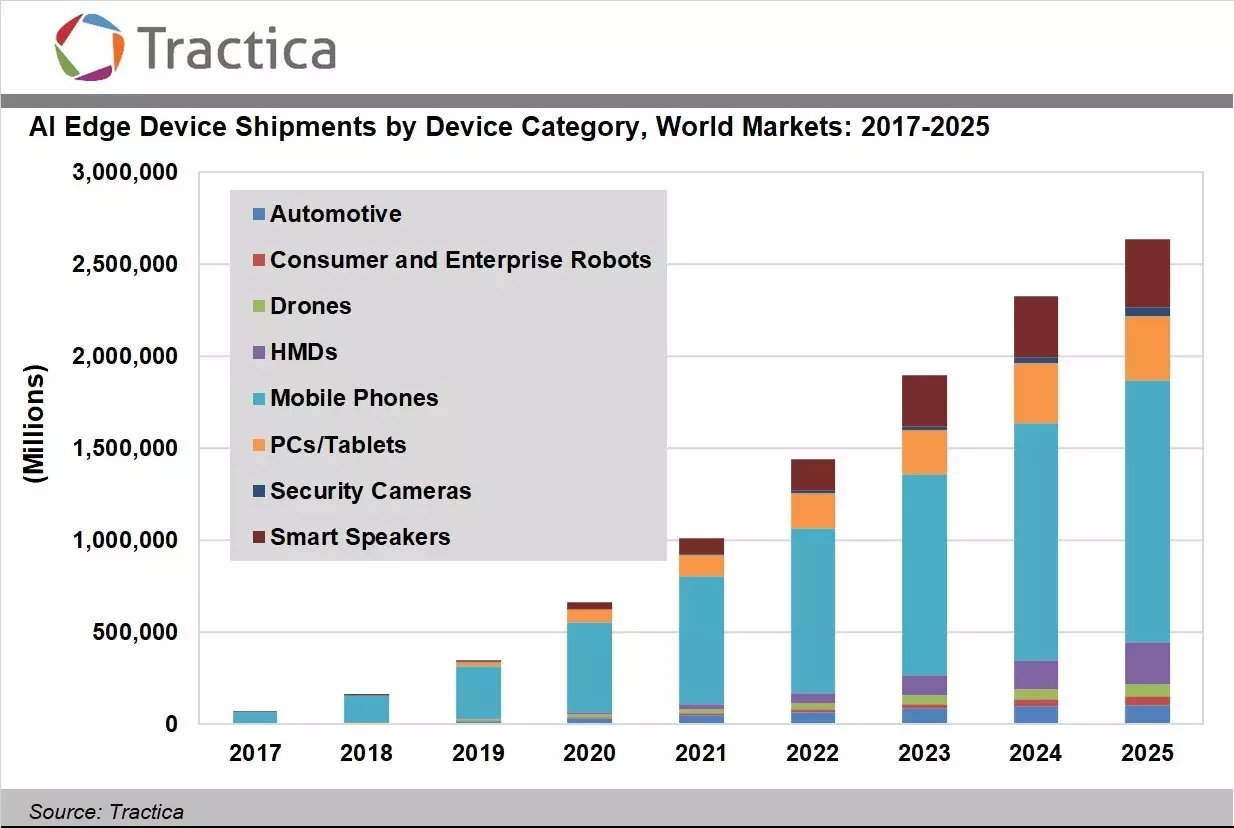
Source for Image above Tractica
Jonathan Frankle Michael Carbin of MIT CSAIL published The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
An excellent summary of the paper is provided by Adam Conner-Simons in Smarter training of neural networks (and is reproduced with permission): https://www.csail.mit.edu/news/smarter-training-neural-networks
MIT CSAIL project shows that neural nets contain "subnetworks" 10x smaller that can just learn just as well - and often faster
These days, nearly all AI-based products in our lives rely on “deep neural networks” that automatically learn to process labeled data.
For most organizations and individuals, though, deep learning is tough to break into. To learn well, neural networks normally have to be quite large and need massive datasets. This training process usually requires multiple days of training and expensive graphics processing units (GPUs) - and sometimes even custom-designed hardware.
But what if they don’t actually have to be all that big after all?
In a new paper, researchers from MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) have shown that neural networks contain subnetworks that are up to 10 times smaller, yet capable of being trained to make equally accurate predictions - and sometimes can learn to do so even faster than the originals.
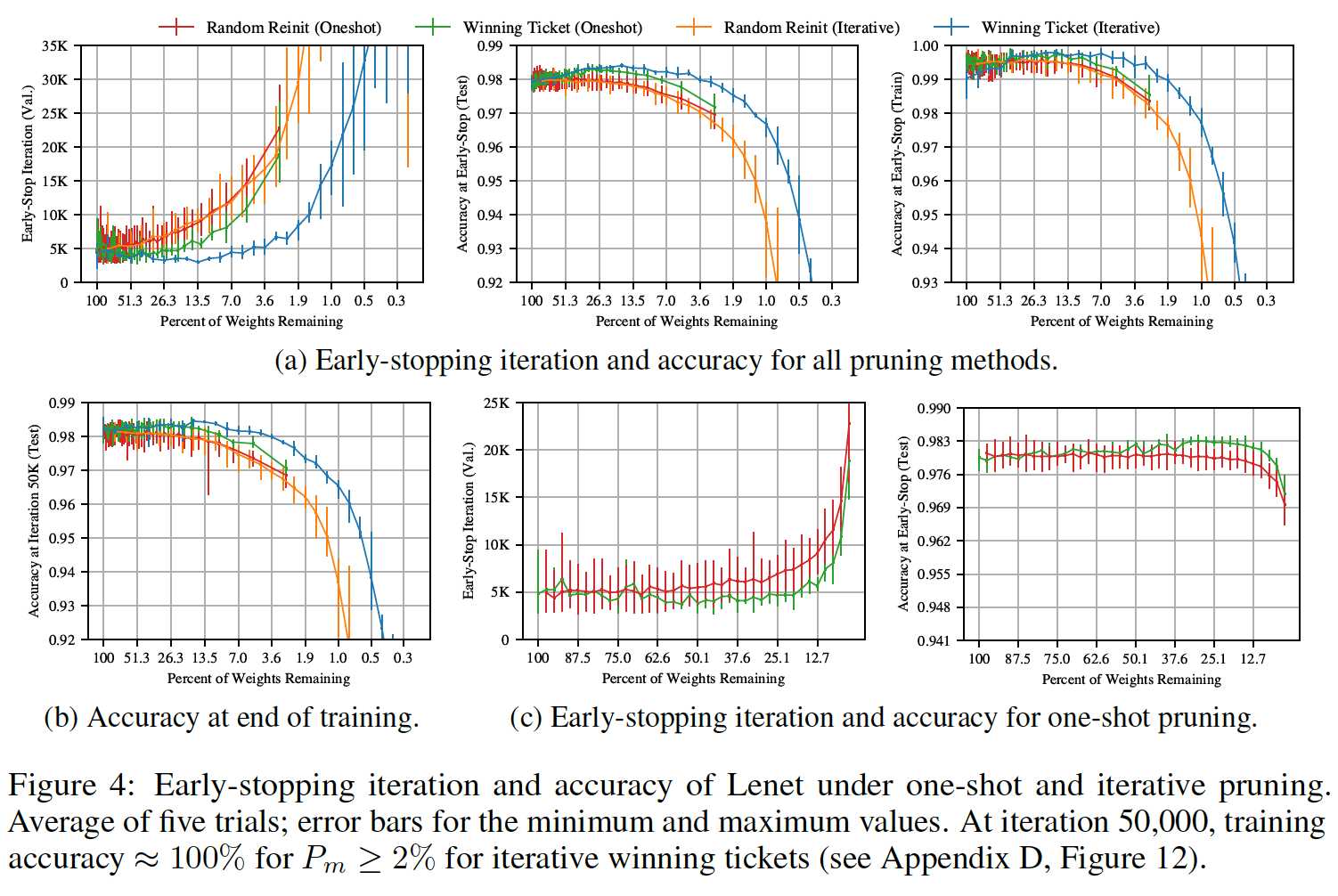
The team’s approach isn’t particularly efficient now - they must train and “prune” the full network several times before finding the successful subnetwork. However, MIT professor Michael Carbin says that his team’s findings suggest that, if we can determine precisely which part of the original network is relevant to the final prediction, scientists might one day be able to skip this expensive process altogether. Such a revelation has the potential to save hours of work and make it easier for meaningful models to be created by individual programmers and not just huge tech companies.
“If the initial network didn’t have to be that big in the first place, why can’t you just create one that’s the right size at the beginning?” says PhD student Jonathan Frankle, who presented his new paper co-authored with Carbin at the International Conference on Learning Representations (ICLR) in New Orleans today. The project was named one of ICLR’s two best papers, out of roughly 1600 submissions.
The team likens traditional deep learning methods to a lottery. Training large neural networks is kind of like trying to guarantee you will win the lottery by blindly buying every possible ticket. But what if we could select the winning numbers at the very start?
“With a neural network you randomly initialize this large structure, and after training it on a huge amount of data it magically works,” Carbin says. "This large structure is like buying a big bag of tickets, even though there’s only a small number of tickets that will actually make you rich. "But we still need a technique to find the winners without seeing the winning numbers first."
The team’s work may also have implications for so-called “transfer learning,” where networks trained for a task like image recognition are built upon to then help with a completely different task.
Traditional transfer learning involves training a network and then adding one more layer on top that’s trained for another task. In many cases, a network trained for one purpose is able to then extract some sort of general knowledge that can later be used for another purpose.
For as much hype as neural networks have received, not much is often made of how hard it is to train them. Because they can be prohibitively expensive to train, data scientists have to make many concessions, weighing a series of trade-offs with respect to the size of the model, the amount of time it takes to train, and its final performance.
To test their so-called "lottery ticket hypothesis" and demonstrate the existence of these smaller subnetworks, the team needed a way to find them. They began by using a common approach for eliminating unnecessary connections from trained networks to make them fit on low-power devices like smartphones: they "pruned" connections with the lowest "weights" (how much the network prioritizes that connection).
Their key innovation was the idea that connections that were pruned after the network was trained might never have been necessary at all. To test this hypothesis, they tried training the exact same network again, but without the pruned connections. Importantly, they "reset" each connection to the weight it was assigned at the beginning of training. These initial weights are vital for helping a lottery ticket win: without them, the pruned networks wouldn't learn. By pruning more and more connections, they determined how much could be removed without harming the network's ability to learn.
To validate this hypothesis, they repeated this process tens of thousands of times on many different networks in a wide range of conditions.
“It was surprising to see that re-setting a well-performing network would often result in something better,” says Carbin. “This suggests that whatever we were doing the first time around wasn’t exactly optimal, and that there’s room for improving how these models learn to improve themselves.”
As a next step, the team plans to explore why certain subnetworks are particularly adept at learning and ways to efficiently find these subnetworks.
“Understanding the ‘lottery-ticket hypothesis’ is likely to keep researchers busy for years to come,” says Daniel Roy, an assistant professor of statistics at the University of Toronto who was not involved in the paper. “The work may also have applications to network compression and optimization. Can we identify this subnetwork early in training, thus speeding up training? Whether these techniques can be used to build effective compression schemes deserves study.”
The section above is courtesy of Adam Connor-Simons MIT CSAIL
In 1959 two of the famous pioneers of AI, John McCarthy and Marvin Minksy created MIT CSAIL. In 1961 Minsky published Steps towards Artificial Intelligence where he observed that:
“ The problems of heuristic programming of making computers solve really difficult problems are divided into five main areas: Search, Pattern-Recognition, Learning, Planning, and Induction."
Patrik Henry Weston noted that Marvin Minsky observed the following in terms of the Symbolists vs Connectionist debate:
"Today, some researchers who seek a simple, compact explanation hope that systems modelled on neural nets or some other connectionist idea will quickly overtake more traditional systems based on symbol manipulation. Others believe that symbol manipulation, with a history that goes back millennia, remains the only viable approach."
"Minsky subscribes to neither of these extremist views. Instead, he argues that Artificial Intelligence must employ many approaches."
Symbolic AI can be defined as a collection of techniques in AI research that focus on high level symbolic representations relating to logic, problems and search. One popular method in Symbolic AI has been expert systems. Expert systems involve production rules connecting symbols in a relationship similar to an If-Then statement. Some have argued that such Expert systems were not really part of AI, for example Kaplan and Heinlein argued "it is important to highlight that expert systems—collections of rules programmed by humans in form of if-then statements—are not part of AI since they lack the ability to learn autonomously from external data."
John McCarthy developed Lisp in 1958 while he was at MIT. McCarthy published its design in a paper in Communications of the ACM in 1960, entitled Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I. The language has obtained the status from those in common usage as the second oldest high level programming language today.
Symbolic AI dominated AI research in the period of the mid 1950s until 1987. In 1984 Marvin Minksy and Roger Shank warned about the dangers of the AI market at the time. The multi billion dollar AI market commenced its collapse three years later three years later in what is known as the second AI Winter.
This was also around the time that Neural Networks started to make a resurgence with the rise of Back-propagation with a paper published by Hinton et al. in 1986 Learning representations by back-propagating errors.
An article in MIT Technology Review by Will Knight reported that "Two rival AI approaches combine to let machines learn about the world like a child".
The article noted that Deep Learning alongside symbolic reasoning enabled a program that learned in a very human-like manner. It also noted that during the past decades AI research had been divided into two main camps with symbolic AI research focussed upon logical rules and representations of the world, whilst connectionists AI research focussed on Artificial Neural Networks and that the two have not managed to get along.
Josh Tenenbaum of MIT led a team to create a program known as neuro-symbolic concept learner (NS-CL) that leaped about the world in a similar manner to how a child may learn through talking and looking (although in a more simplistic manner).
The paper entitled The Neuro-Symbolic Learner: Interpreting Scenes, Words, and Sentences form Natural Supervision is a joint paper between MIT CSAIL, MIT Brain Computer Science, MIT-IBM Watson AI Lab and Google DeepMind.
Will Knight in the Technology Review observed that:
"More practically, it could also unlock new applications of AI because the new technology requires far less training data. Robot systems, for example, could finally learn on the fly, rather than spend significant time training for each unique environment they’re in."
“This is really exciting because it’s going to get us past this dependency on huge amounts of labeled data,” says David Cox, the scientist who leads the MIT-IBM Watson AI lab.

Perhaps we can view the research related to the NS-CL as aligned to the vision of Marvin Minsky in bringing the fields of AI closer together.

It remains to be seen which methods will develop and scale successfully in the future but it is great to see the likes of MIT researchers working on novel approaches that entail reducing the amount of data required to train Deep Neural Networks and also to allow Machines to learn on the fly. The era of 5G will involve greater deployment of AI on the edge (on device) in the 2020s with real-time interactions from one machine to another machine and also between intelligent devices and humans on the fly.
Imtiaz Adam is a Hybrid Strategist and Data Scientist. He is focussed on the latest developments in artificial intelligence and machine learning techniques with a particular focus on deep learning. Imtiaz holds an MSc in Computer Science with research in AI (Distinction) University of London, MBA (Distinction), Sloan in Strategy Fellow London Business School, MSc Finance with Quantitative Econometric Modelling (Distinction) at Cass Business School. He is the Founder of Deep Learn Strategies Limited, and served as Director & Global Head of a business he founded at Morgan Stanley in Climate Finance & ESG Strategic Advisory. He has a strong expertise in enterprise sales & marketing, data science, and corporate & business strategist.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest