Generative AI is a transformative force with the potential to revolutionize the synthetic data sector.
It also holds the key to unlocking a widespread scaling of AI applications throughout the economy while concurrently safeguarding data privacy. It is crucial to recognize that the efficacy of any AI model, including those leveraging synthetic data, is intricately linked to the quality of the underlying data. The success and ethical soundness of any AI advances are contingent upon the careful curation and refinement of both real and synthetic data sources. Due diligence is needed in ensuring the integrity, accuracy, and privacy compliance of the data driving the next wave of AI innovation.
Using Generative AI for Positive Use Cases
It’s all about the data! Firms around the world face a barrier and challenge with developing and deploying Machine Learning models that are customised to their own (and their customer) needs. This barrier is caused by access to sufficient quantity and quality of data required to train and test a model of production level quality.
AI has exciting potential to revolutionise the world and bring vast benefits to sectors such as healthcare including diagnosis of diseases and new (de novo) drug development with greater efficiencies. However, there are also challenges with data privacy as AI models rely upon large sets of data to train and develop models for commercial usage, and issues such as imbalance in datasets resulting in bias that may in turn result in unfair and unreasonable outcomes.
This has led to a challenge over data ethics, privacy, and often limited the potential for AI to scale in particular in sectors where data privacy is sensitive (for example the healthcare, financial services / FinTech / InsurTech sectors).
The focus of the article is an interview with Ali Golshan, CEO and co-founder of Gretel.ai, an exciting San Francisco Bay area based startup that is applying Generative AI towards generating synthetic data for business applications.
Gretel has raised a total of $67.7M across 3 rounds, with the most recent one in October 2021
The article will initially set out what Generative AI and Synthetic data are why they matter followed by an interview with Ali Golshan the CEO of Gretel.ai.
What is Generative AI?
Generative AI has been described by McKinsey as a type of AI that may be applied towards creation of new content (for example Chat GPT) ranging from text, audio, videos, still images, and simulations.
The types of AI algorithm utilised in Generative AI may include Variational Autoencoder (VAE), Generative Adversarial Network (GAN), or Transformers with Self-Attention Mechanism. Irrespective of the model used, ultimately data underpins all models and the quality and availability of the data determines the effectiveness of the model.
However, many companies but find that despite the references to the era of ‘big data’, they cannot use or access the data due to the following issues:
The data is unusable due to privacy regulations (GDPR, HIPAA, etc);
The data is siloed or has other imbalance issues (that may result in ethical issues with bias);
Or in other cases the data simply does not exist yet or the firm does not possess the data (see the interview below for the cold start problem).
Applying Generative AI to create synthetic data has been viewed as a potential solution to these problems and hence to enable AI to scale across the economy whilst also solving for the privacy issue or lack of data and other data issues.
What Is Synthetic Data & the Market Outlook for its Adoption?
Synthetic data is generated in a digital world via computer-based algorithms and is artificial, however, when generated and applied in the correct manner it may reflect the real-world data in terms of statistical and mathematical properties.
Research exists showing that synthetic data may be as effective or in some instances even superior for the purposes of training an AI model relative to data based upon actual people, events and objects, for example see Catherine Graham's article published in John Hopkins ‘synthetic data for AI outperform real data in robotic surgery’.
Furthermore, Gerard Andrews of NVIDIA quotes a forecast from Gartner that by 2030 synthetic data will completely overshadow real data used for training AI models.
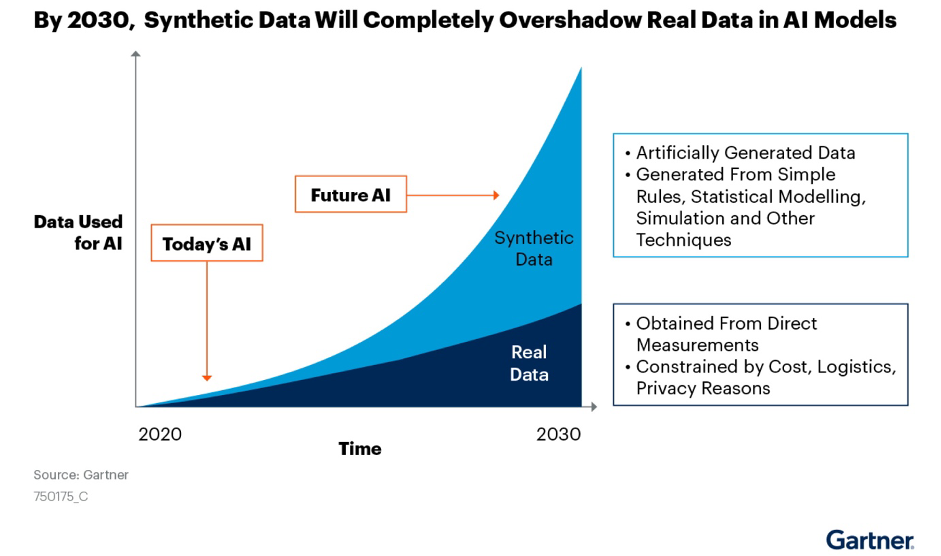
Gartner further report that whilst only 1% of AI models used synthetic data in 2021, it may be that as much as 60% of AI models may use synthetic data by the end of 2024.
Whether we hit 60% adoption of synthetic data for AI model development by the end of 2024 or later, the synthetic data sector is set to grow rapidly as concerns about data privacy and also bias that may result from incomplete or imbalanced datasets grows.
It is clear that synthetic data is set to play an increasingly significant and important role in the future of AI model development.
Interview Ali Golshan CEO Gretel.ai

Imtiaz Adam: What inspired the name Gretel.ai?
Ali Golshan: The story of Hansel & Gretel. Leaving breadcrumbs allows someone to be found. In the digital era a digital crumb, in effect a footprint, that you leave online may result in privacy issues for the user. Our inspiration in founding Gretel.ai is to solve the trade-off between providing useful machine learning capabilities for a good customer and user experience alongside privacy preservation.
Imtiaz Adam: Who were the original founding team?
Ali Golshan: Alexander Watson Chief Product Officer, John Myers CTO and myself.
We all came from computer science and maths backgrounds and we all worked in the intelligence and cyber security space. Since then, we’ve each founded and successfully exited from multiple startups.
In terms of my own experience, this is my 5th startup. I have previously made exits to Juniper and also to IBM.
Imtiaz Adam: What is the company’s mission and objective?
Ali Golshan: Our focus is towards an application of Generative AI towards synthetic data generation.
We believe that data will be the key differentiator in the era of AI, even more so that the models.
Given that the value is in the data, we asked ourselves how we can enable companies to go the last mile and extract the value from their data in a way that is safe and deals with all the complexities of data imbalances, usability and ease of use. To solve this, we took inspiration from how GitHub solved for ease of access and safe storage for code, and aim to do something similar for data so that companies can find an easier pathway to generating value from their data whilst also managing the privacy and safety aspects.
We started looking at solutions such as homomorphic encryption and then realised that the opportunity was in applying Generative AI towards data generation.
In time firms will increasingly realise that the last mile for value generation will be the ability to leverage their private data. At the same time, they need to balance data generation with not giving away information to others and also balancing their privacy obligations.
We can help them apply synthetic data to find the optimal model solution.
Example use cases include applications for fraud detection (where the positive examples of fraud are a small fraction of the overall sample / population set).
Further examples are the conditional generation that help with ‘what if’ evaluations in healthcare and pharma where synthetic data may save firms time and money assisting pharma companies find the most promising candidates for drug development, helping healthcare firms evaluate the potential candidates for product development without breaching patient privacy.
For the Consumer Packaged Goods (CPG) ecommerce we’ve developed solutions with a. pre trained model that applies ½ trillion tokens that may work with tabular data with approximately 1 million rows and hundreds of columns. We also then provide a time series function.
For example, our service can save a firm up to 40% on time and related development resources within the machine learning lifecycle. Assuming that the average project takes between 75-90 days to develop and a further assumption that a firm may develop 3 projects a year, then we’re looking at least 225-270 days of developer time. If our synthetic data services save 40% of that then we’re looking at a range of 90-108 days project development time saved. That’s at least 3 months of costly developer time and a faster go to market.
The other aspect that must be tackled is the cold start problem. A good example of the cold start problem is the situation of a firm seeking to enter a new market. However, they often don’t have the historical data to apply machine learning for analytical purposes. We have a platform that solves for this particular challenge with pre trained foundational models without random weights. There is also a tabular model that gives a schema and helps the firm resolve the cold start problem. We can also help solve for missing data points applying correlations when we generate synthetic data.
Synthetic data can also help companies to focus their efforts by providing a playground for the cold start problem and if they can find for example a candidate product or service with a 90% probability of success then they can then focus investment into further developing that candidate including going on to gather real-world data.
Currently the market is early and firms are starting to understand how synthetic data may help them.
This is my fifth startup and my approach along with that of the team is to focus on market solutions that take the pain away from the customer in terms of managing complex infrastructure with an offering that has cloud services and modalities and focusing on repeatable use cases that may scale. It is important for the customer that they don’t need to rebuild all the infrastructure every time they operate our solutions.
Imtiaz Adam: What’s next for synthetic data? I personally see vast potential in IoT devices arriving into our cities and homes and the need to balance personal data privacy whilst providing customised user services.
Ali Golshan: Yes, IoT and scaling across the edge of the network is a huge area of growth over the next few years. As is AI growing across sectors such as finance and healthcare. We need industry collaborations whilst also allowing firms to fine tune their models on their private data without breaching privacy needs. Take the right to forget under GDPR in the EU and UK. If someone asks to be forgotten then not only do you need to remove the data, you also need to retrain the models that trained on the datasets that included them and that is extremely costly from a time and resources perspective. But if you use synthetic data then suddenly that problem is not there. There is no need to retrain all the models and the associated costs.
In terms of the edge, we’re likely to see smaller models emerge that work with federated learning and we’ll probably move to a model of collective monetization from data.
A summary of our approach is to develop a user-friendly solution that seeks to generate high quality synthetic data to help companies solve for the cold-start problem and issues such as data privacy and the risks of bias caused by imbalanced data.
End of the Interview

Generative AI algorithms may be applied towards learning the underlying relationships and patterns within a dataset. The knowledge gained may then be applied towards creating a new dataset that is consistent with the original dataset.
Use cases and typical examples of Synthetic Data are set out by Gary Stafford (Unlocking the Potential of Generative AI for Synthetic Data) and based upon AltexSoft, in ‘Synthetic Data for Machine Learning: its Nature, Types, and Ways of Generation’.
Tabular data: retaining consistency with the statistical and structural property of the data.
Time series data: may be useful in scenarios where real-world data is costly or simply not available.
Image and video data: For example, in training machine learning models or simulations with realistic videos or images.
Text data: Generating training data for machine learning models by generation of realistic natural language processing including realistic text.
Sound data: Training machine learning models with sound that is realistic and effective for model training.
Synthetic Data & Privacy
A research paper by Patki et al. (2016) entitled the ‘Synthetic Vault Data’ demonstrated that there was no significant difference in the work produced by the data scientists who used synthetic data as opposed to real data.
Moreover, Brian Eastwood writing in MIT Sloan noted “Synthetic data — which resembles real data sets but doesn’t compromise privacy — allows companies to share data and create algorithms more easily.”
Brian Eastwood also notes that synthetic data may also address the bias issue that may be inherent in certain data sets due to the fact that synthetic data sets are not limited to the original sample size and hence one may generate a new data set in advance of model development.
However, Robert Reiman writing in the European Data Protection Supervisor, whilst acknowledging that synthetic data may result in enhancing privacy in technologies and improved fairness in machine learning models notes that there are challenges, notably:
Output control could be complex
Difficulty to map outliers
Quality of the model depends on the data source
Therefore, the quality of solution and its usability really matters to an organisation that is seeking to develop its own AI models.
Summary
Generative AI has vast potential to revolutionise the synthetic data sector and in turn enable a vast scaling of AI applications across the economy whilst preserving data privacy provided that an appropriate solution is used (the model is only as good as the data and the same applies to the quality of the synthetic data).
Gretel.ai provides an example of an exciting startup that is positioned in a market set for rapid growth. At a time where the media has focussed so much on the threat of Generative AI towards humanity (for the avoidance of doubt the author remains sceptical about Skynet or similar suddenly appearing in the near to medium term future) it is great to see Generative AI being used in a positive manner that may help advance humanity with solutions in healthcare, FinTech, Insurtech and also materially enhance data privacy. Generative AI when used appropriately may in fact help alleviate the actual problems that we face with AI in the real world (data availability, quality, privacy and imbalances that may result in ethical issues).
Quality synthetic data leads to the question as to why someone needs the real-data when the synthetic data is good enough? If adopted appropriately and widely then perhaps synthetic data may lead to the end of the era of data harvesting. It may also help alleviate the bias issues that may result from imbalanced datasets and hence assist companies alleviate the ethics issue that results from such imbalances. Furthermore, it can help reduce the failure rate of AI projects where they are caused by data quality issues.
Perhaps our policy makers and business leaders may consider a future whereby a collaboration of firms across a sector with synthetic data enables a scaling of AI that benefits society as a whole via key sectors such as healthcare, financial services, and as 5G enables IoT to scale and merge with AI the rise of the AIoT across smart cities and smart homes where data privacy needs to be balanced alongside enabling mass hyper-personalization at scale.


Leave your comments
Post comment as a guest