Comments (2)
Tom Lawrence
I was eagerly looking for this one.
David Harrison
Excellent explanation

I recently purchased a new laptop one with enough speed and space to let me do any number of projects that my nearly four-year-old workhorse was just not equipped to handle.
One of those projects was to start going through the dominant triple stores and explore them in greater depth as part of a general evaluation I hope to complete later in the year. The latest Ontotext GraphDB (9.7.0) had been on my list for a while, and I was generally surprised and pleased by what I found there, especially as I'd worked with older versions of GraphDB and found it useful but not quite there.
There were four features in particular that I was overjoyed to see:
These four items have become what I consider essential technologies for a W3C stack triple store to fully implement. I'd additionally like to see some consensus around a property path-based equivalent to Gremlin (RDF* and SPARQL* is a starting point), but right now the industry is still divided with respect to that.
There are a couple of other features that I find quite useful in GraphDB. One of the first is something I've been advocating for a long time - if you load in triples in Turtle, you are also providing the prefix to namespace associations to the system, but all too often these get thrown out or mapped to some other, less useful term (typically, p1: to pN). Namespaces do have some intrinsic meaning, and prefixes can, within controlled circumstances, do a lot of the heavy lifting of that meaning. When I make a SPARQL query, I don't want to have to re-declare these prefixes. OntoText automatically does that for you, transparently.
The other aspect of OntoText that I've always liked is that they realized early on that visualizations were important - they communicate information about seemingly complex spaces that tables simply can't, they make it easier to visually spot anomalies, and when you're talking to a client you don't want to spend a lot of time building up yet another visualization layer. OntoText has worked closely with Linkurious to develop Ogma.js, a visualization library that is used extensively within their own product but is also available as an open-source javascript library. I still rely fairly heavily on vizjs.org and d3.js) as well as working with the DOT and related libraries out of GraphViz, but having something that's available "out of the box" is a big advantage when trying to explain complex graph math to non-ontologists.
I'll be doing a series exploring these points as part of this newsletter, with Ontotext being my testbed for putting together examples. In this particular issue, I'd like to talk about RDF* and SPARQL*, and why these will help bridge the gap between knowledge graphs and property graphs.
This seemingly simple question is what differentiates a property graph from an RDF graph. In RDF, an edge is considered to be an abstract connection between two concepts. For instance, consider the marriage between two people: person:_Jane and person:_Mark. In a (very) simple ontology, this distinction can be summarized in one statement:

If you are describing the state of the world as it currently exists, this is perfectly sufficient. The edge `person:isMarriedTo` is abstract, and can be thought of as a function. Indeed, Manchester notation, used in early OWL documentation, made this very clear by turning the edge into a function:

What's most interesting about this is that while `person:isMarried` itself is abstract (you can think of it as a function with two parameters), the resulting object is NOT in fact a person, but a marriage instance:

If at some time Jane divorces Mark and marries Harry, then you end up with another marriage that uses the same template:

These are two separate marriages, two separate instances, and they are clearly not the same marriage.
In an RDF graph, this kind of association typically needed to be described by what amounted to a third form normalization:

There are advantages to this approach: first, you have a clear declaration of type (Marriage), and you essentially invert the marriage function. Additionally, you can add more assertions that help qualify this node:

You can also describe other relationships by referencing the created object:

which makes it possible to ask questions like Who were the children of Jane?

If you are building a genealogy database, this level of complexity and abstraction is useful, but it does require that you explicitly model these entities and that you then expect that there will be a large number (this is where combinatorics and factorials begin to kick in creating geometric growth in databases).
A property graph short-circuits this by specifying that an edge is a concrete node that can take attributes but not relationships. In effect, the property edge has both the abstract relationship description (`person:isMarriedTo`) and the relationships that exist between the nodes that are bound to this assertion or function. However, this benefit comes from the fact that property graphs essentially have nodes that are inaccessible to other nodes. This tends to make property graphs more optimized for performance, at the cost of making them less versatile for modeling or inferencing.
In some cases it makes sense to explicitly label these edge relational models, but sometimes you just don't have that luxury: for instance, what happens when you get data in the form

You can take a shortcut here by creating a reification, a very fancy word that means creating a reference to a triple as a single assertion. Reifications actually were in place why back in the first RDF proposal, and look something like this:

The problem with this is that it is fairly unwieldy. RDF* and SPARQL* were proposals that would provide a syntax that would do much the same thing in Turtle and SPARQL respectively but without the verbosity. The syntax was to wrap double angle brackets around a given triple to indicate that it should be treated as a reification:
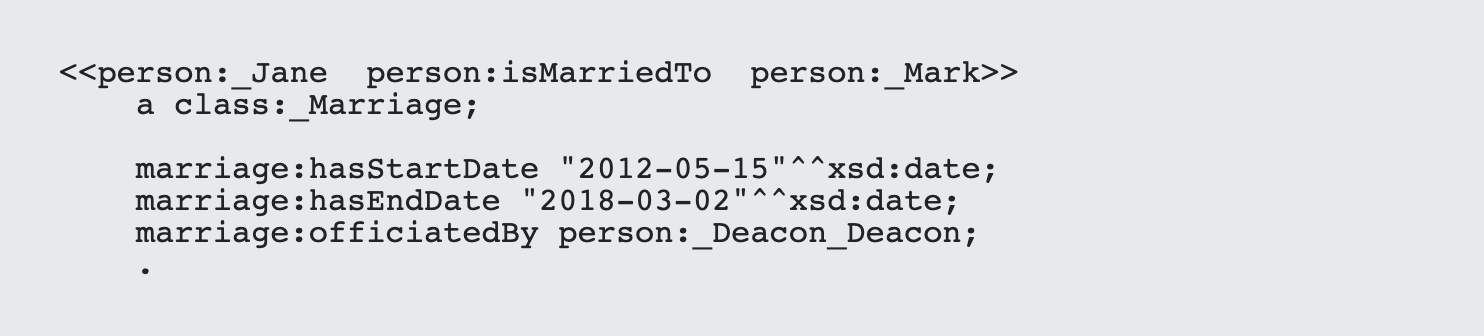
In effect, this creates a uniquely identifiable URI that represents a triple. It's worth noting that this doesn't affect any of the components of that triple. For instance, I can still say:

Reification in the RDF (in either guise) can somewhat simplify the generation of RDF, but the more powerful benefits come when you provide support in SPARQL for the same concept.
For instance, SPARQL* supports three functions rdf:subject,rdf:predicate and rdf:object. This comes in handy for doing things like finding out whom Jane Doe was married to on January 1, 2015.

This example is more complicated than it should be only because person:isMarriedTo is symmetric. What's worth noting, however, is that, from SPARQL's standpoint, the reified value in ?marriage is a node just like any other node. If the predicate hadn't been symmetric, the expression:

could have been replaced with

There are two additional functions that SPARQL* supports: rdf:isTriple() and rdf:Statement. The first takes a node and tests whether it has the rdf:subject,rdf:predicate and rdf:object predicates defined for the entity, while the subject creates a triple statement from the corresponding node URIs:
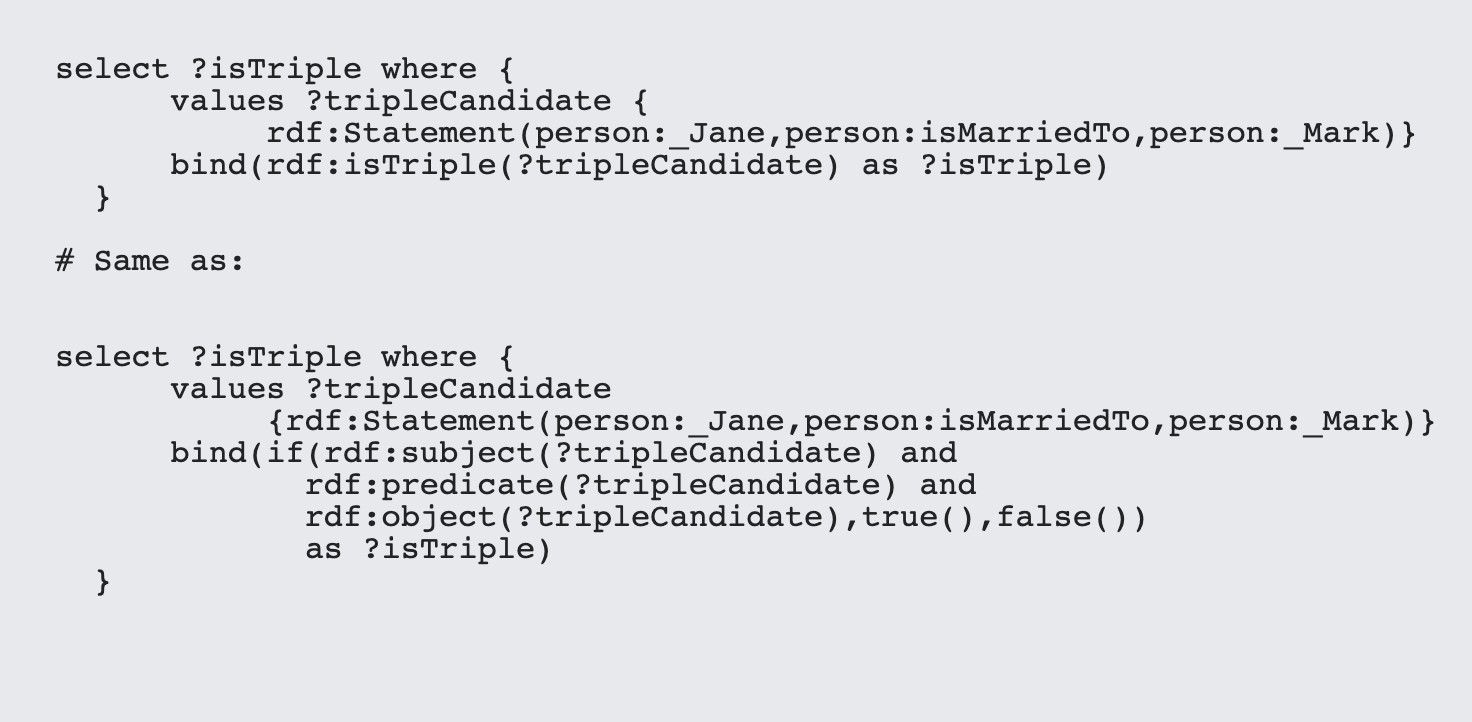
It's also worth noting that if any of the three components are null values, then the rdf:Statement() function will also return a null value and the isTriple() function will return false().
So when would you use reification? Surprisingly, not quite as many as you'd think. One seeming obvious use case comes when you want to annotate a relationship without creating a formal class to support the annotation. For instance let's say that you have a particular price associated with a given product, and that price changes regularly even if the rest of the product does not. You can annotate that price change over time as follows:

This annotational approach lets you track the price evolution of a given product over time, and also provides a way of indicating whether the current assertion is active. Of course, if the price changes away from "21.95" then changes back, you suddenly end up with multiple hasLastUpdate, hasApprovalBy and isActive assertions - unless the new reification has a different URI than the old one does.
This can lead to some unexpected (though consistent) results. For instance, if you create a sequence in SPARQL, such as:

It's entirely possible that you will get multiple values returned.
This actually gets to a deeper issue in RDF, which is the fact that reifications can create a large number of seemingly duplicate triples that aren't actually duplicates, especially if reification was an automatic capability of creating triples in the first place. In effect, it requires another field in what is already becoming a crowded tuple, as "triples" now have one additional slot for graphs, a second slot for types in objects, and now a third slot (for a total of six) for managing a unique URI that acts as the reified URI for the entry, when you're talking about potentially billions of triples, each of these slots has a cumulative effect in terms of both performance and memory requirements.
This raises a question - do you need RDF*? From the annotational standpoint, quite possibly, as it provides a means of tracking volatile property and relationship value changes over time. From a modeling perspective, however, perhaps not. For instance, the marriage example given earlier in this article can actually be resolved quite handily by simply creating a marriage class that points to both (or potentially more than both) spouses with a `marriage:hasSpouse` property, rather than attempting to create a poorly considered `person:isMarriedTo` relationship.
Put another way - RDF* should not be used to solve modeling deficiencies. The marriage example without RDF* is actually easier to articulate and understand as just one instance of this.

The primary illustration of this comes in the area of paths. Property graphs are used frequently in path analysis, where the goal is to either minimize or maximize the aggregate values of a particular property that crosses a path. A good example of this would be airline maps, where an airline flies certain routes, and the goal is to minimize the distance travelled to get to a particular airport from another airport. Again, this is where modeling can actual prove more effective than trying to emulate property-graph-like behavior.
For instance, you can define an airline route as the path taken between airports to get to a final destination. While you COULD use RDF* for this, you're probably better off putting the time into modeling this correctly:

In this particular case, calculating flight distances for different routes, while not trivial, is doable. The trick is to understand that sequences in RDF are represented by rdf:first/rdf:rest chains, where rdf:first points to a given item in the sequence, and rdf:rest points to the next pointer in the chain:

It's always worth remembering that RDF graphs generally work best by capturing derived information. Thus, once such route distances are calculated once, they can always be stored back into the graph to minimize the overall computational costs. In other words, with knowledge graphs, the more information that you can index, the more intelligent the overall system becomes:

Reification plays a big part in managing annotations, and a lesser role in operational logic such as per property permissions, and for that, RDF* and SPARQL* provide some powerful tools. However, in general, intelligent model design is all that is really needed to make RDF graphs both as efficient and as flexible as labeled property graphs. That RDF is not used as much tends to come down to the fact that most developers prefer to model their domain as little as possible, even though the long-term benefits of intelligent modeling make such solutions useful for far longer than plug-and-play labeled property graphs.
Another area worth exploring is the ability to extend SPARQL through various tools. I'll explore this in more detail in my next post.

I was eagerly looking for this one.
Excellent explanation
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest