Comments (3)
Kevin Poole
Extremely dangerous technology that'll be exploited very soon
Kevin Douglas
I don't want to imagine life after ten years.
Callum Perkins
This technology will be abused in the future...
As a veteran of way too many zoom conferences, It's perhaps not all that surprising that I would have discovered one of the cooler features of the app - the ability to create an algorithmic green screen that lets you superimpose both static background and videos behind you.
The algorithm is not perfect - every so often a shoulder will disappear or hair will suddenly do really weird things, but given that it's basically isolating your outline, ascertaining what's the background and what's you, and then superimposing (or, in the jargon of the SFX industry compositing) the new background over what's left, the effect is pretty damned impressive.

There is now a thriving industry of companies that supply specialty green screens that you can set up behind you for a surprisingly inexpensive amount, letting you quite literally put yourself in the middle of the action. For remote roleplaying, especially as the dungeon master, it's hard to beat, but it's also an indication of just how rapidly we are reaching the point where what had once been studio-level graphical effects are now making their way to our desktops.
In a previous article, I made the observation that there is typically a gap of about six years between the time that your favorite special effects first appear in Hollywood (or more properly, in the area around Skywalker ranch south of San Jose that's become the mecca of the digital effects industry) and the time that the same special effects make their way to high-end gaming systems. It's about four years after that (or about a decade total, that it's in your smartphones and iPad and laptops, effectively becoming ubiquitous. Most of this is accomplished by increasingly powerful GPU chips that have moved beyond taking the burden of rendering on the screen off of the CPU to become full-blown graphics studios in their own rights.
Human beings are surprisingly hard to model. Buildings are easy not necessarily because they are linear (though that doesn't hurt) but because they are generally opaque. Humans are not, not completely. We have textures on our skin where flesh folds and bends, light actually gets a few microns below the surface before bouncing off again, and hair is a reality everywhere on the human body. Hair is hard because you have to model enough strands separately to give the illusion that you're modeling everything. Eyes - don't get me started on eyes.
The algorithms for these kinds of renderings started out as software, but as they were worked out, they became standard fare for GPUs, which are especially well suited for the process of calculating the various vector equations involved in determining diffuse and ambient lighting, reflections, refractions, translucency, and similar convolutions (it also makes machine learning much easier, because the same type of vector operations are fairly critical for determining gradients and minima). This combination has become especially useful for the deployment of avatars, which require both kinds of fast calculation now coming online with these chips.

An avatar can be considered a virtual visual proxy for a person, and is usually paired with the concept of agents. An agent usually acts on your behalf to perform an action, such as the audio based agents such as Ciri, Alexa, Cortana, and so forth. Avatars are basically the representation that you show to the outside world of yourself, though it can be yourself as an idealized version of you, an elf, mermaid or orc, a Jedi knight, really the skies the limit. Agents can also have avatars (indeed, agents are called as such because they have agency, the ability to act quasi-independently to perform a specific set of tasks) that depict them as familiars, butlers, companion beings or "cute bots", because as a culture that's a narrative we've been conditioned towards, but
The connections between avatars, agents and video games are obvious, especially when dealing with shared worlds. In some respects, the whole notion of virtual reality should be seen as more or less synonymous with video games - someone creates a world that satisfies specific rules (both culturally and physically) and your avatar becomes your representation within that particular world. The world may be physically very different, but because the expectations within such a world is that it is meant to emulate an environment, game creators basically have to employ the same kind of suspension of disbelief principles that authors and animators do.
If you notice in superhero movies where a psionic character knocks someone down with a telekinetic blast, there is always some kind of visual (and frequently audible) effect involved, because without it, that suspension of disbelief is broken as our experience tells us that we should see something. We are sensory beings - we rely upon our senses to inform our perceptions of the world, and while our senses are good at noting inconsistencies, the more that we become reliant upon the assumption that the universe is magical, the less likely we are to be able to distinguish the avatars and virtual reality from our sensory reality.

Case in point - the above was a piece I created recently in a consumer-grade program called Daz Studio, a 3D rendering program. The figure and the wheelchair are completely digitally created - they exist as 3D meshes that are then rendered based upon available lighting. The background was a special kind of photograph called an HDRI (high dynamic-range imaging), in which a specialized rotating camera creates a photograph by literally spinning along all three axes to get a complete wrap-around environment in all directions, then creating a map that transforms the resulting image into the given environment in the right editing tools (this following is not quite the same background, but is illustrative).

HDRIs are becoming powerful media for 3D artists and animators because they not only encode visual information but also store lighting information - by placing a 3D model within the environment then rendering with this lighting, it becomes possible to cast consistent shadows, to create the appropriate illumination for backlighting, and to place that model into the physical context. You can also go one step further and build a 3D physical model (quite possibly with an HDRI wrap around) then render this back into another HDRI that can then be composited again to give very sophisticated views of a world that exists only within a computer.
This can be done today on retail hardware and software. It is time-consuming at the moment - the above anime mermaid took about twenty-five minutes to render a single frame at very high resolution (about 4000x4000 dpi), but it is possible to rent time on cloud-based render farms relatively inexpensively. However, again keep in mind the expectations on GPUs - custom GPUs in retail computers take between six to ten years to get to the point where they are emulating what's happening with high-end animation shops (and Skywalker Ranch), which means that by the late-2020s, the capability of creating real-time animations nearly indistinguishable from reality will be available in a typical smartphone or tablet.
Environments can be modeled algorithmically, but as machine learning and deep-learning systems become more sophisticated, they can also be generated directly from existing data - such as the data that has powered the self-driving revolution of the past few years. nVidia, for instance, has been experimenting heavily with simulated environments that are created contextually by taking existing footage, determining the representation of that information, then modeling that information on the fly without the need to manually design that model. It would be as if the above HDRs (as videos) could be extended to videos, modeled, then patched back together with associated transformations:

Animating realistic human motion is not easy. Currently, the process is performed using a process called rigging, Human bodies especially deform in weird ways as they move - the skin drapes and folds and is somewhat elastic, muscles have limits and change dimensions, and gravity and momentum have to be considered at every point. The calculations involved get very complicated, but they can be worked out - and 3D animators (many of whom have advanced degrees in mathematics) have been working out much of the foundation of these types of models for the last thirty years.

This is in many respects the holy grail of animation. We've been stuck in the uncanny valley for the last twenty years, where we're close enough that the motion seems to be near life-like but subtly disturbing, like watching a corpse sit up and start talking. The uncanny valley is due to that same suspension of disbelief principle and has to do with the way that we process threats. When a person talks with another person, even as they are verbally communicating, there's a second channel of body language that we're constantly evaluating - how people slouch, eye contact, nervous gestures, facial expressions and so forth. Women tend to be more subtly physically expressive than men (and more aware of such expressions than men) which has become somewhat memetic in recent years - she's worried about whether her boyfriend is angry or upset or pleased, he's thinking about getting a beer and is absolutely clueless about his girlfriend's inner confusion of his emotional state.
These kinds of things CAN be emulated. It is largely a matter of time, processing power, and the sophistication of AIs that can analyze a set of emotive clues and produce a sequence of action (an animation). I think it reasonable to say that this will happen within the next decade to the extent that it will be possible to create a "deep fake" that is, on the surface at least, completely indistinguishable from reality. Now in practice, the universe is noisy, and this means that algorithmically generated deep fakes are usually distinguishable based upon noise signatures in the data, but given the preponderance of digitally edited content already being produced, noise is not necessarily a guarantee of fidelity.
This has several implications for the next decade and beyond. The first is that people with commodity hardware and software can now create increasingly realistic content at a level comparable to a production studio from a few years before. The porn industry is already exploiting this fact, utilizing hybrid video/animation approaches to "augment" their actors in predictable and unpredictable ways. They are crude by contemporary standards (in more ways than one) but the trend is clearly there.

Samsung's Neon technology illustrates the fidelity of avatars, getting close to pushing beyond the uncanny valley.
AI and facial mapping tools are also now able to put someone's head and hair on someone else's body using the same kind of inferential motion capture, which is already raising some thorny issues about the degree to which one's likeness is copyrightable, and similar tools can generate surprisingly good three-dimensional models of a given person's face and physique, which can then be manipulated to say or do anything.
Similar innovations are occurring in the area of speech processing. Machine learning makes it possible to create sound filters that lets you take a corpus of sound fragments from a person's audio recordings and use that to generate good simulations of how they would say certain words or phrases. At a minimum, this kind of audio filter would become a great market if you wanted to have your avatar sound like Tom Hanks or Helena Bonham Carter, but again, the implications for political mischief, especially in an increasingly digitized world, are profound.

In 2017, during the Mueller investigation into Russian involvement favoring the Trump administration the year before, a video from 1OneClone made the rounds on Youtube that, while relatively obvious, illustrated the potential both for protest and for character assassination, in which various political figures heads were grafted onto characters from the Marvel Daredevil Season 1 ending montage. While satirical, it was also presaged the fact that the ability to digitally edit and create "fake" media for political purposes was clearly at hand, and it wasn't long before both sides began engaging in the process.
Doctoring photographs and videos is hardly new, but until what had been commercial editing capabilities made their way into consumer tools, most such videos were fairly obvious because of technical artifacts. Part of the reason that George Lucas remastered the original Star Wars films was due to the issue that the splices of the various space ship models into the film were becoming more and more obvious as the celluloid aged. Digital mastering involved actually re-building all of the physical model shots as 3D meshes and integrating them into the film.
Indeed, most of the video that is produced today is actually filmless, typically with a mixture of drone-based filming, stabilized camera rigs, and increasingly in process-CGI and streaming, so that video can actually be edited in near real-time. This means that we're reaching a point where a political leader speaking to a mostly empty venue can, with a few minutes on a graphics dedicated workstation, be speaking to an overflow crowd of adoring fans instead ... and there's the rub.
A picture is worth far more than a thousand words, and a video is worth more than a thousand pictures. We as a species are primarily visually, secondarily auditory, while reading is a phenomenon so recent that it's barely really entered our consciousness - most of humanity was not literate until the 16th century AD. Video is our subconsciousness's crack, going straight into the brain with comparatively limited filtering, and the incentives for everyone from marketing companies to political campaigns to religions to shape messages targeted along that pathway are a part of the reason that video advertising continues to be such a powerful force. We're just not critical when it comes to video, not in the same way we are with reading, and as such programming the brain to accept what is seen as being real is disturbingly powerful.
As much as AI may be at the root of the ability to create such deep fakes, it is also a potential means to flag them. Google's Jigsaw (above), for instance, is able to detect when images have been altered or even created from whole cloth through compositing. Similarly Adobe similarly has been working to create AI tools capable of detecting when a given image or video has been manipulated in Photoshop. In both cases, what these systems do is to search for patterns in the underlying bitmaps that are specifically artifacts of kernel manipulation, which is used for blending, moving portion of an image via drags, detecting duplication indicative of stamp tool manipulation and so forth.
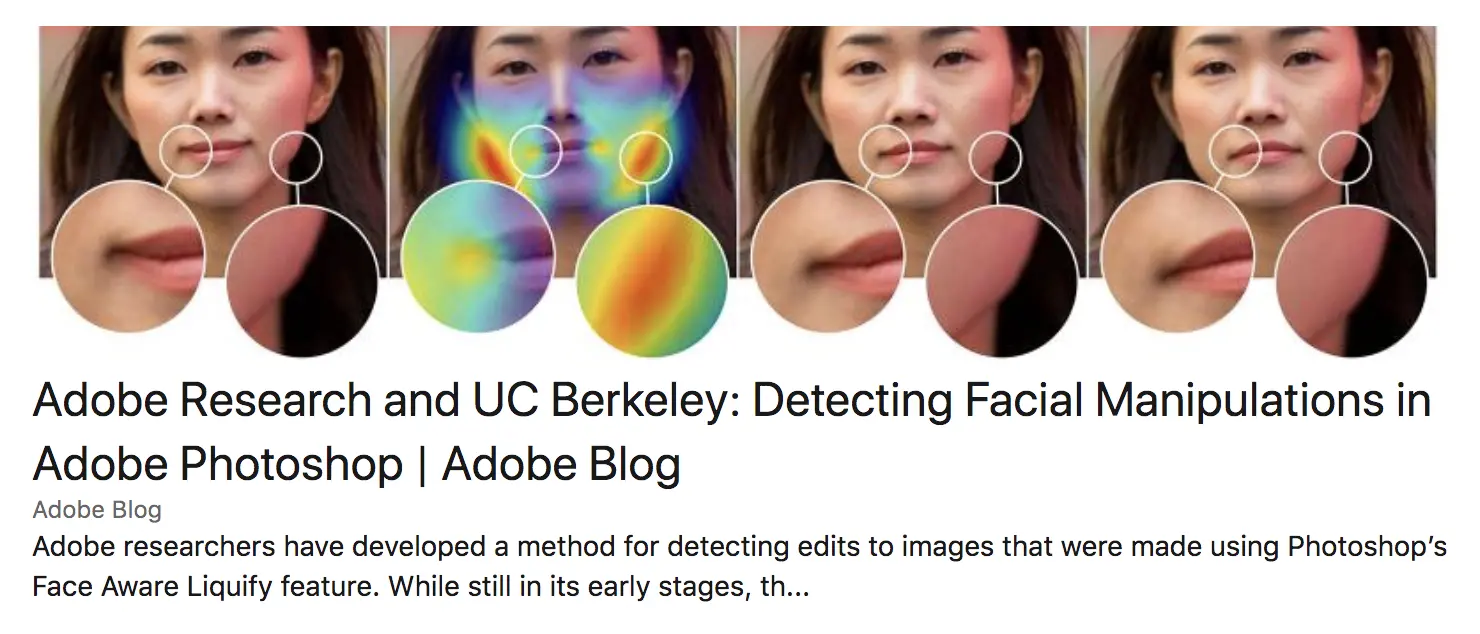
The approach is not perfect, as rescaling downward, a fairly common process, can limit any detectability due to noise, but it is indicative that determining fakes is doable, just not necessarily easy. Similarly, work is being down to sign videos in ways that are essentially codec independent, meaning that the signing (creating a hash code based upon particular traits within the video itself) can be done even when moving from say a Microsoft AVI file to an MPEG-4 video.
Of course, video can be manipulated during production as well. In May 2019, a video showing a confused House Speaker Nancy Pelosi was shown to be a fake primarily by comparing it to other videos that had been produced by different news agencies. The manipulated video (which had appeared as part of a since discontinued social media account) just simply sped up and slowed down pre-existing content - detectable by an AI program, but not involving complex tools to create.

Mona's looking kind of glum.
If you are interested in exploring avatars and potential deep fakes, I'd recommend downloading the Python based avatarify program, which gives you the ability to create an avatar from Albert Einstein, Steve Jobs, the Mona Lisa, or other generated avatar figures. While the precanned avatars are fun to play with, what are even remarkable are the StyleGAN avatars that are generated dynamically, which can then be fed into avatarify. The site This Person Does Not Exist showcases more such generated avatar images.

The future of avatars is here, both for good and bad. The ability to create believable simulacrums as well as the fantastic is reaching a stage where it is becoming available to the consumer market, and with it, quite possibly, a stage where seeing is no longer truly believing.

Extremely dangerous technology that'll be exploited very soon
I don't want to imagine life after ten years.
This technology will be abused in the future...
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest