Comments
- No comments found

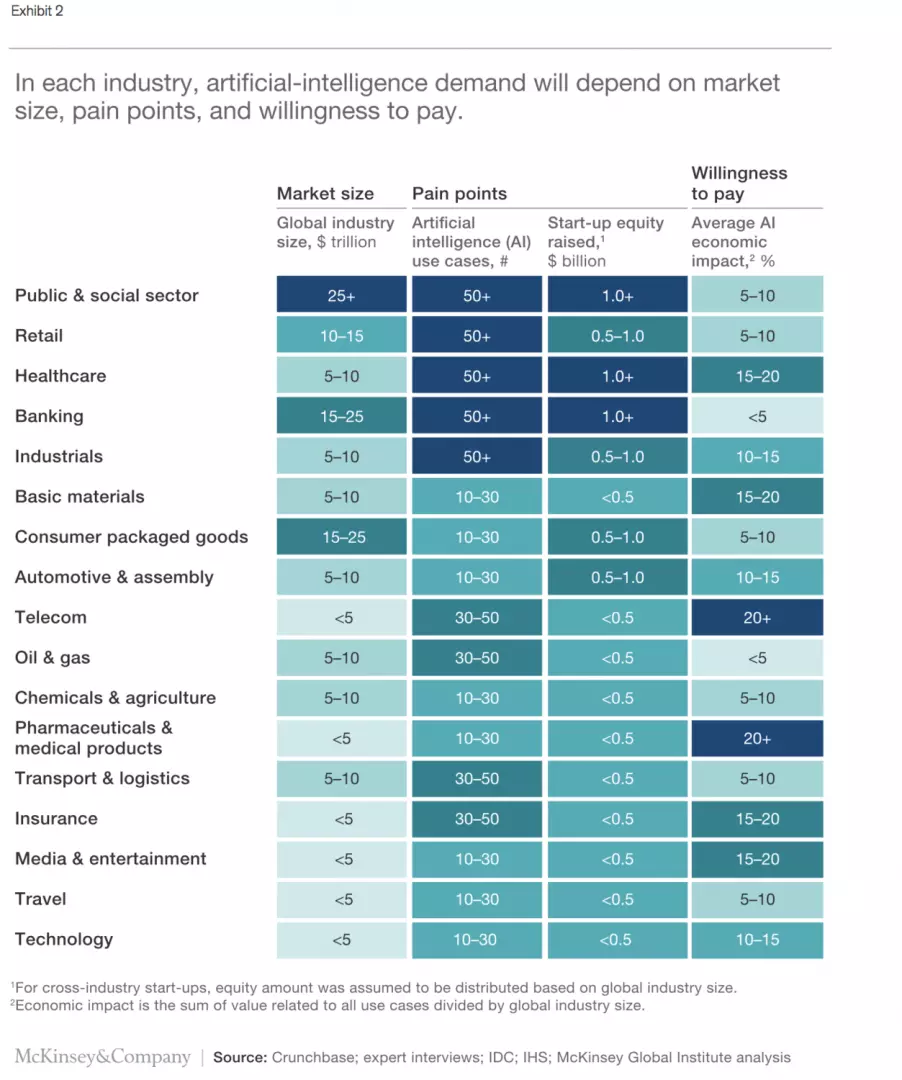
Investment in artificial intelligence (AI), machine learning and deep learning are growing from organizations outside the tech space.
Organisations around the world are seeking to accelerate digital transformation strategies in light of the Covid crisis.
Janusz Moneta and Lucy Sinclair observe that "COVID-19 has accelerated digital adoption — the time to transform is now" whilst Twilio study predicts that "COVID-19 has sped up digital transformation by 5.3 years".
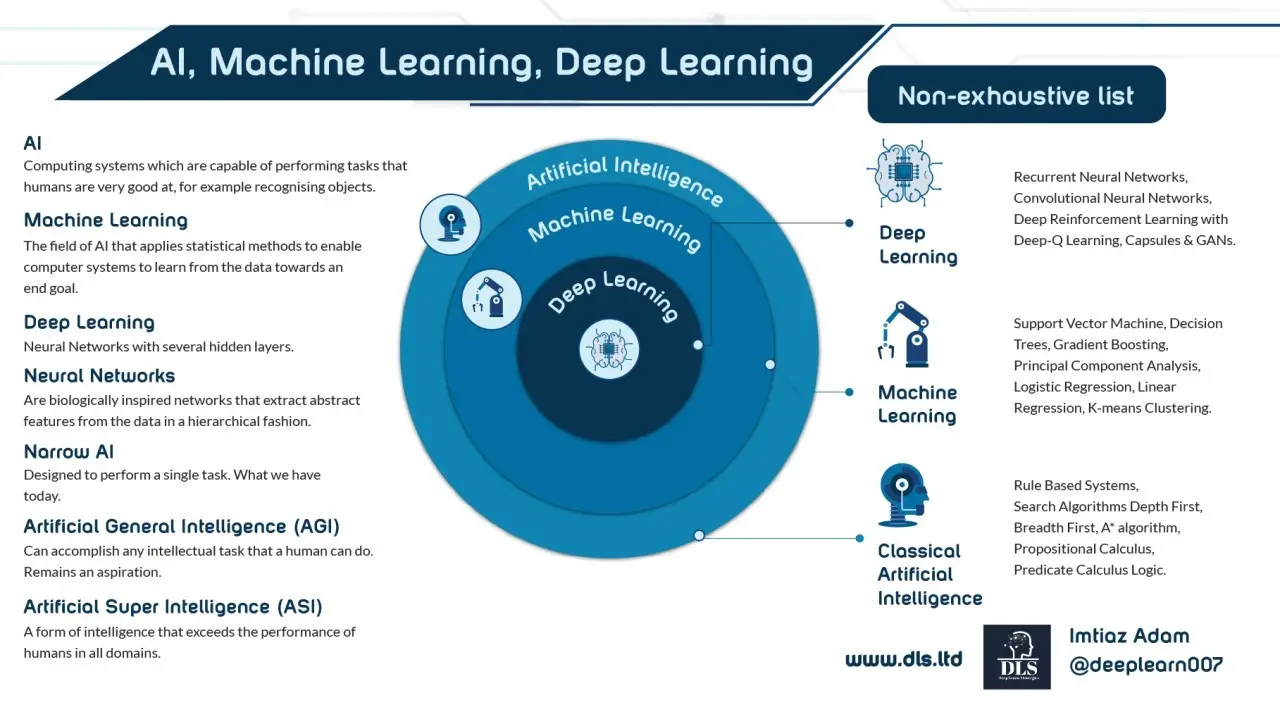
For the purpose of this article AI will be referred to an umbrella term that relates to computing systems which are capable of performing tasks that humans are very good at. Machine Learning will be referred to as a subset of AI that applies statistical methods to enable computer systems to learn from the data towards an end goal and Deep Learning a subset of Machine Learning that entails Neural Networks with several hidden layers.
See the following report on the hyperlink for a detailed analysis of the State of AI in 2020.
Machine Learning is set to change every sector of the Economy
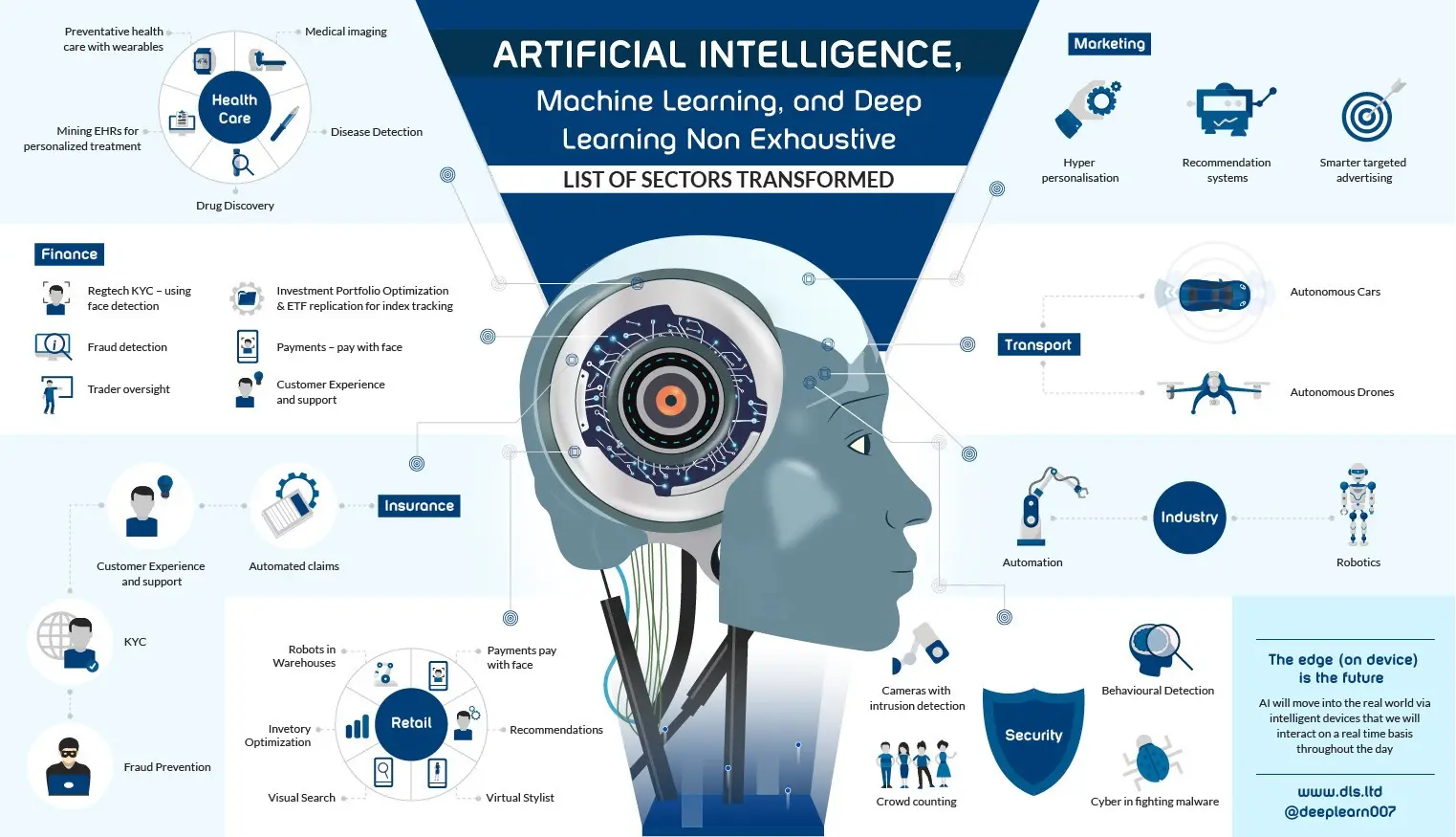
As the infographic above illustrates, Machine Learning will affect every sector of the economy from retail, finance, insurance, marketing, healthcare, cybersecurity transportation, and manufacturing. Had there been space then I would have added agriculture and education too.
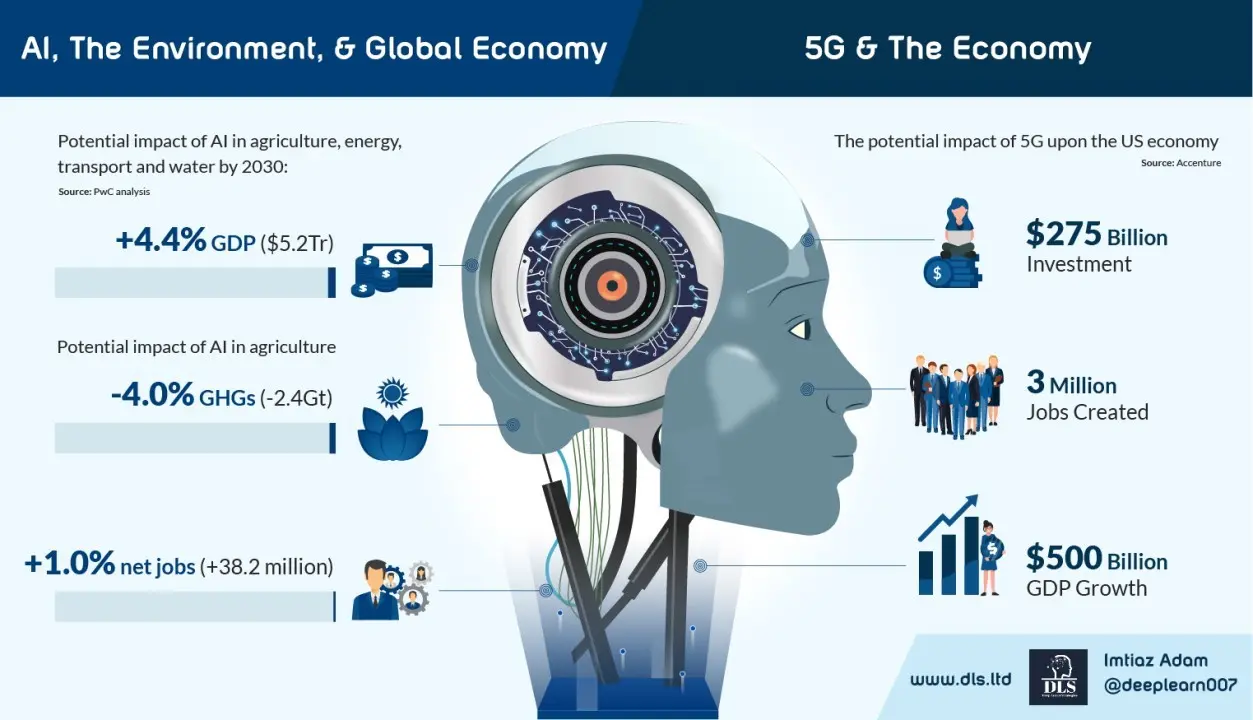
Furthermore as pressure grows on our policy makers to do something about economic recovery as well as responding to the threats of climate change, Machine Learning combined with other emerging technologies may deliver tangible benefits in relation to those policy objectives which will likely be increasingly aligned with corporate Environmental and Sustainable objectives going forwards.
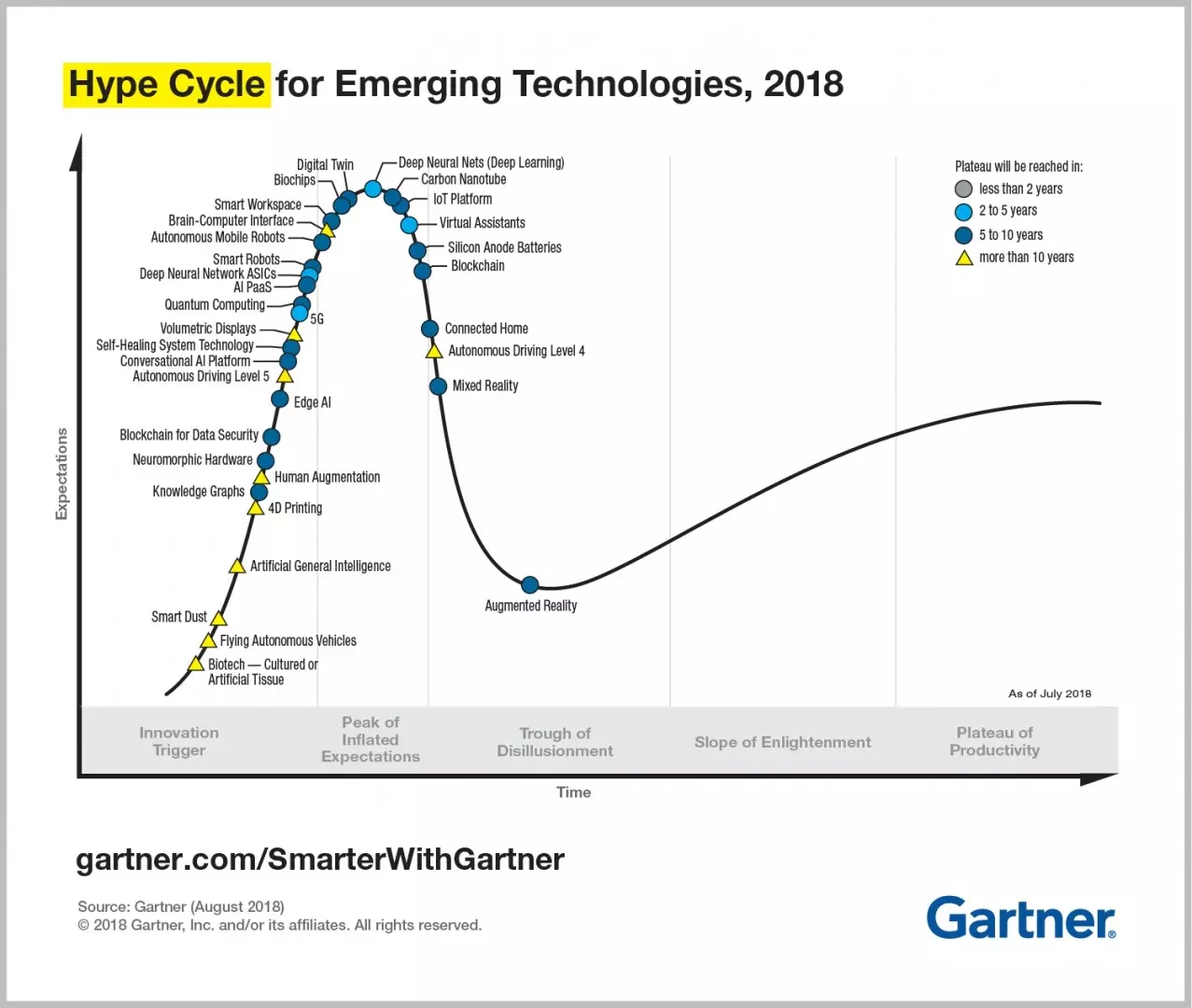
Source for the image above: Gartner Hype Cycle for AI 2020
Gartner observe the following:
"Despite the global impact of COVID-19, 47% of Artificial Intelligence (AI) investments were unchanged since the start of the pandemic and 30% of organizations actually planned to increase such investments, according to a Gartner poll. Only 16% had temporarily suspended AI investments, and just 7% had decreased them.
AI is starting to deliver on its potential and its benefits for businesses are becoming a reality.
"According to a recent Gartner survey, the C-suite is steering AI projects, with nearly 30% of projects directed by CEOs. Having the C-suite in the driver’s seat accelerates AI adoption and investment in AI solutions."
Responsible AI and AI governance also become a priority for AI on an industrial scale.
However, Machine Learning and Data Science is not a magical show. it requires a process with skilled professionals engaging in complicated tasks to deliver the results.
The Data Science Life Cycle has been summarised by Microsoft as shown in the image below:
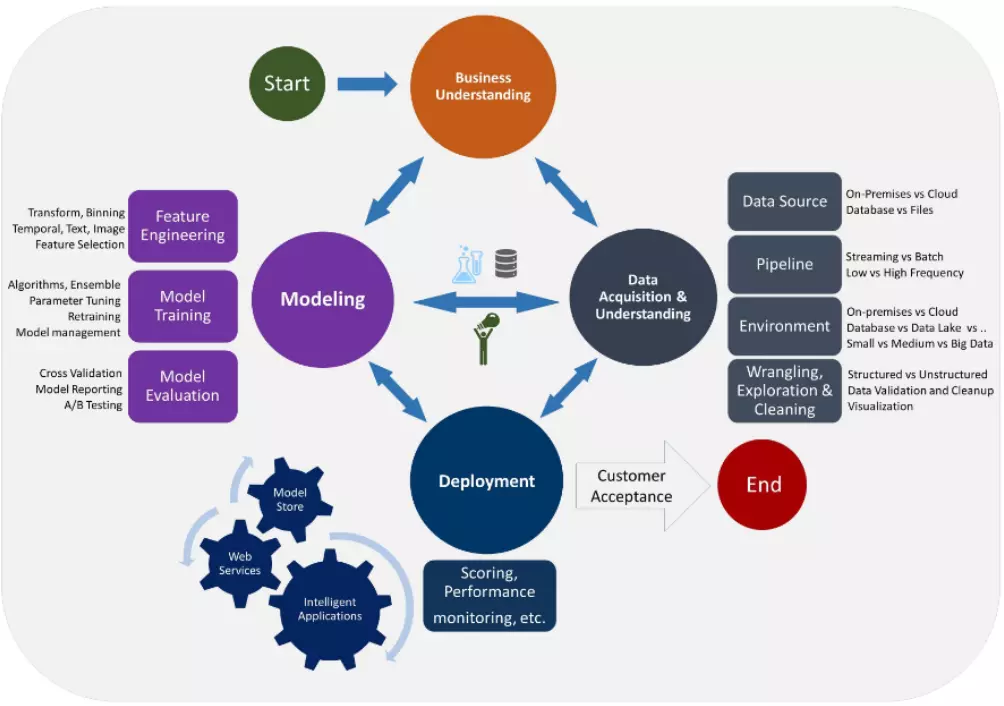
How can firms and organisations generally adopt Machine Learning technology and successfully achieve tangible benefits from Machine Learning and Data Science projects?
The strategic objectives of the firm, its business operations, data systems, and back end technology infrastructure will all be key in addition to organisational culture and internal knowhow.
Microsoft focus on Five lifecycle stages
The TDSP lifecycle is composed of five major stages that are executed iteratively. These stages include:
For each stage, we provide the following information:
Nevertheless, once we step away from the tech majors the success of Machine Learning projects has been less straightforward or successful.
Challenges with successful implementation of AI into the organisation
What should organisations do to avoid being one of the 87% that fail to succeed?
1) It's all about the Data! Data, data everywhere...
The rhyme of the ancient mariner "Water, water, everywhere, And all the boards did shrink; Water, water, everywhere, Nor any drop to drink . . . ”
The risk is the same with data. Just as the ancient mariner was unable to drink the water that he was surrounded by as it was salty sea water, data all over the organisation is no use if it is not captured and stored appropriately.

Image above: The Economist The world’s most valuable resource is no longer oil, but data
Data has been referred to as the new oil in the digital era, however, oil needs to be refined before it can be used and the same analogy applied to data. It needs to be cleaned and pre-processed before it is useful for a Machine Learning project.
Big Data has been a key driving force in the rise of Machine Learning and Deep Learning.
The explosion in data has been driven by the rise of online internet and mobile traffic with social media and ecommerce helping drive much of the deluge of data.
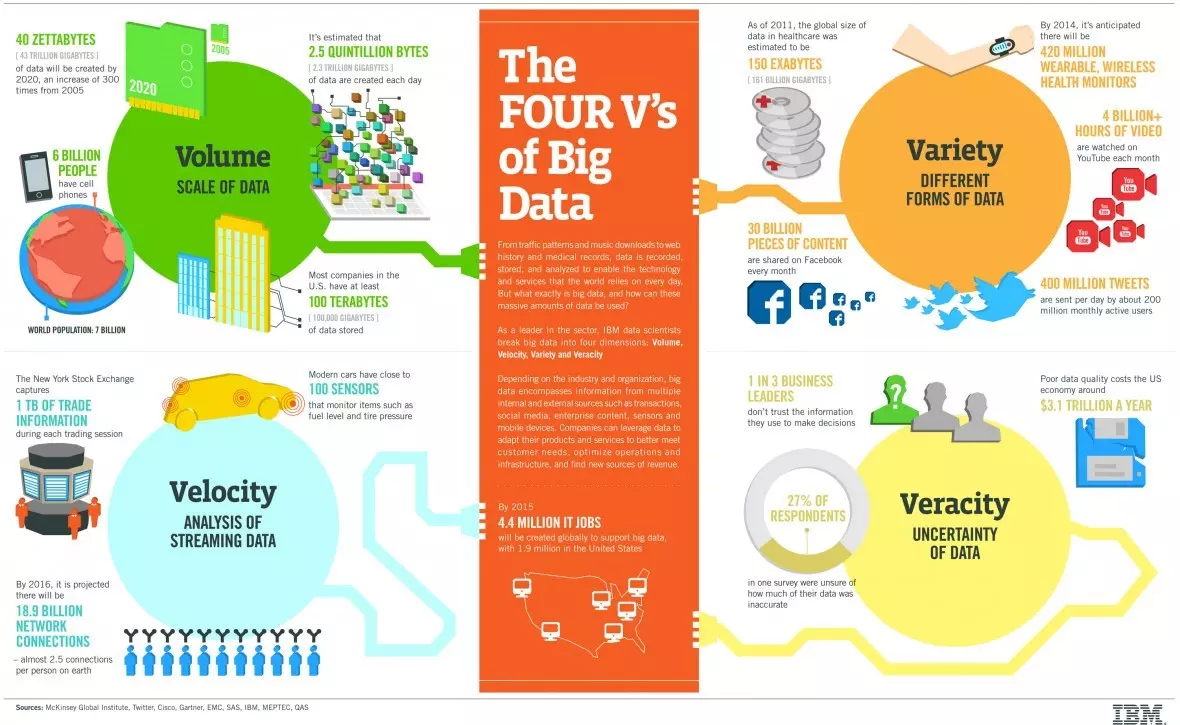
IBM produced the four Vs of Big data infographic shown above.
However, IBM later added a fifth V under the heading of Value. Anil Jain made the observation that "...big data must have value. That is, if you’re going to invest in the infrastructure required to collect and interpret data on a system-wide scale, it’s important to ensure that the insights that are generated are based on accurate data and lead to measurable improvements at the end of the day."
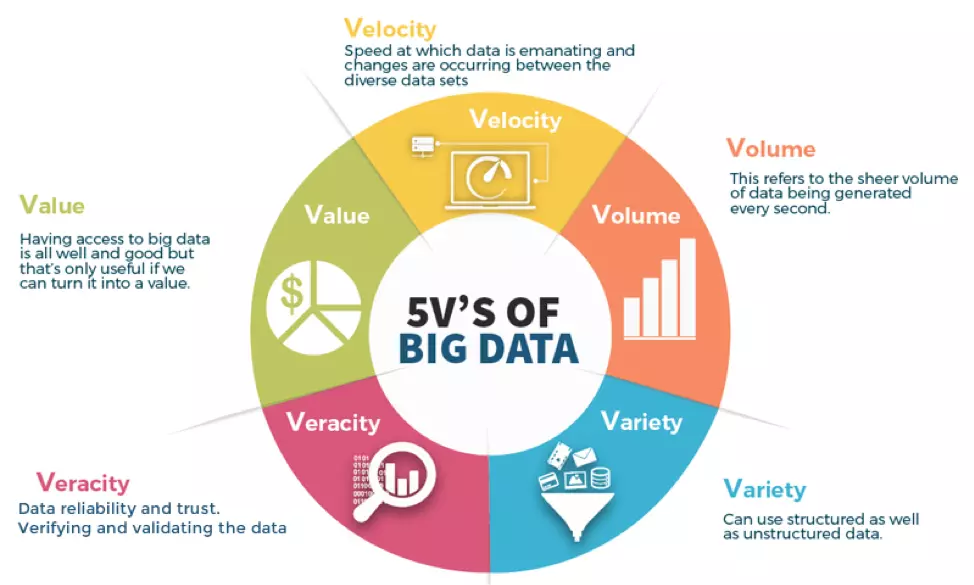
Source for image above: Nick The Data Veracity – Big Data
Nick in the Data Varacity observes that Data is an enterprise’s most valuable resource but also stresses that data governance is essential for organisations.
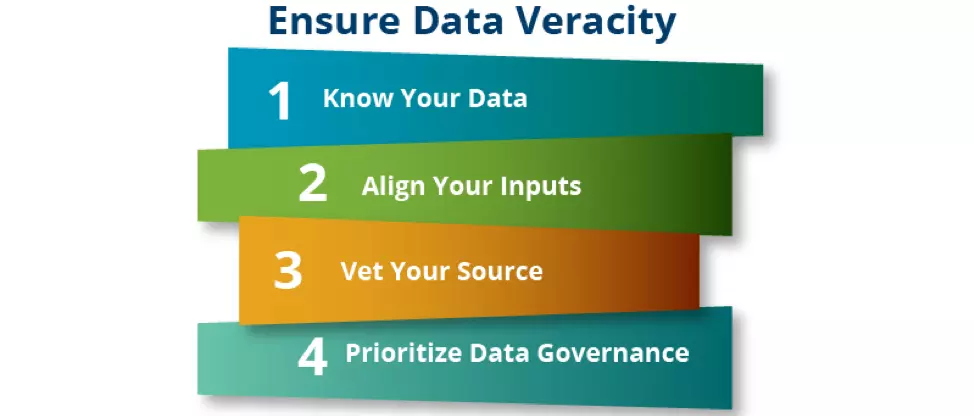
Source for image above: Nick The Data Veracity – Big Data
Raconteur illustrate just how much data was generated in 2019

Source for image above: Raconteur A Day in Data
Jeff Desjardins in an article published in the WEF entitled How much data is generated each day? states that "...the entire digital universe is expected to reach 44 zettabytes by 2020."
"If this number is correct, it will mean there are 40 times more bytes than there are stars in the observable universe."
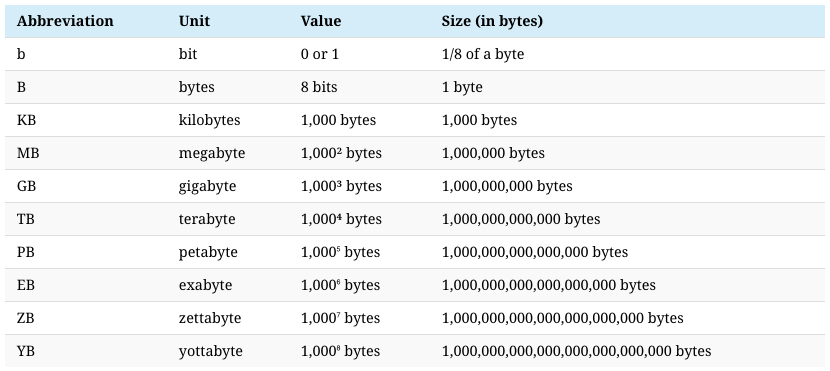
Source for the image above How much data is generated each day?
Jeff Desjardins highlights some of key daily statistics in the infographic :
By 2025, it’s estimated that 463 exabytes of data will be created each day globally – that’s the equivalent of 212,765,957 DVDs per day!

Source for the image above VisualCapitalist.com Here’s What Happens Every Minute on the Internet in 2020
The image above illustrates the advantage that the tech majors including the social media giants possess in terms of access to data and the legacy organisations are unlikely to possess the same volumes of data. However, data is set to continue to grow and as we move into an increasingly digital era with Data-Driven decision making we will need to apply Machine Learning and Deep Learning models to make sense of the data and to provide meaningful interactions with customers or respond appropriately in relation to internal operational matters.
As a starting point for the organisation seeking to develop Machine Learning I suggest that the process should entail asking questions relating to data about what, how and where.
Questions that we may ask include: What data do we possess? How and where is it captured? Are we working with structured data stored in relational Databases using SQL for example PostgreSQL or with unstructured data stored in NoSQL?
The majority of the work by Data Scientists and Machine Learning engineers maybe devoted to data pre-processing and working in Python with libraries such as Numpy, Pandas Matplotlib and Seaborn.
There is the expression in Machine Learning garbage in, garbage out (GIGO). If the data is not good then the results will be bad.
The team also has to evaluate how much data is stored, the quality and type of data.
The reality is that the majority of Machine Learning today relies on Supervised Learning (see algorithms section 3 below) which in turn requires annotated or labeled data as the foundation for the ground truth.
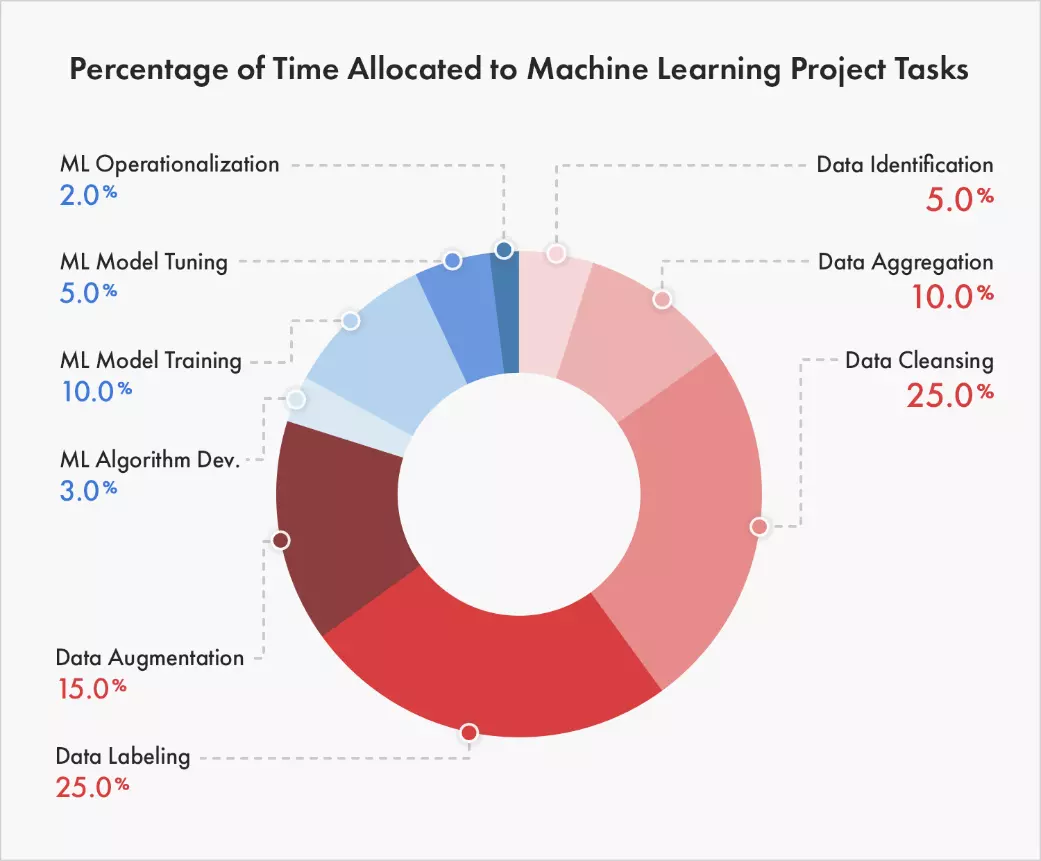
Niti Sharma An Introduction to Data Labeling in Artificial Intelligence Data Wrangling consumes over 80% of the time in AI projects.
Most data organisations hold is not labeled, and labeled data is the foundation of AI jobs and AI projects.
"Labeled data, means marking up or annotating your data for the target model so it can predict. In general, data labeling includes data tagging, annotation, moderation, classification, transcription, and processing."
Particular features are highlighted by labeled data and the classification of those attributes maybe be analysed by models for patterns in order to predict the new targets. An example would be labelling images as cancerous and benign or non-cancerous for a set of medical images that a Convolutional Neural Network (CNN) computer vision algorithm may then classify unseen images of the same class of data in the future.
Niti Sharma also notes some key points to consider.
In a typical AI project, professionals can encounter the following challenges when undertaking data labeling:
Machine Learning models typically require large amounts to carefully labeled data for successfully training supervised learning tasks with the labels often applied by humans.
"Firms spent over USD 1.7 billion on data labeling in 2019. This number can reach USD 4.1 billion by 2024."
"Cognilytica says that mastery in the given subject is not required to perform data labeling. However, a certain amount of what AI professionals say ‘domain expertise’ is crucial. This means even amateurs with the right training can thrive as data-labelers."
Stephanie Overby 8 reasons AI projects fail observes that Poor data governance is a key challenge and reason for failure. GIGO still applies and some key observations are quoted below:
“Most enterprises underestimate the importance of quality data in enabling AI implementation success,”
“Unfortunately, some companies have poor data governance and poor data hygiene practices that result in data that are suspect, duplicated, or called something else somewhere else. Moreover, these firms have multiple, disparate systems housing bits and pieces of the required information.”
Risks can also arise from skewed data samples. “This can lead to problems such as overfitting, for instance, thereby leading to incorrect outputs when run in production,”
“AI systems will only learn what they are fed. So there’s always a risk of human biases being learned and propagated through machines.”
The problem with poor data quality is that it will impact the quality of features that a Machine Learning model is using to learn.
What is a feature and why we need the engineering of it?
Features / Attributes: these are used to represent the data in a form that the algorithms can understand and process. For example, features in an image may represent edges and corners.
Feature selection is also an important part of the process and the quality of data will impact the Feature Engineering process. Feature engineering may be less of an issue for Computer Vision with Deep Learning CNNs, but in many other cases Feature Engineering will be of great importance to the success or failure of the Machine Learning project.
Source for Image Above: Souresh Day CNN application Automated Feature Extraction
Jean-François Puget in Feature Engineering For Deep Learning states that "In the case of image recognition, it is true that lots of feature extraction became obsolete with Deep Learning. Same for natural language processing where the use of recurrent neural networks made a lot of feature engineering obsolete too."
However, Jean-François Puget argues that "..many Deep Learning Neural Networks contain hard-coded data processing, feature extraction, and feature engineering. They may require less of these than other Machine Learning algorithms, but they still require some."
In any event even with image recognition with a CNN if the data ingestion engine is flawed and data is incorrectly labelled the Deep Neural Network will also learn incorrectly in the training due to the misclassification of the ground truth annotations. An example that I personally experienced relates to data feeds from well known international calibre retail brands with two of them mixing up shorts with shirts, and skirts with shirts. In both cases women's skirts and shorts were being placed into mens shirts and the CNN that was trained for similarity detection and visual search ended up misclassifying images resulting in a need to go back and clean the data further and retrain the model in order to fix the issue. What this did demonstrate was that even famous brands could be better with their own data.
In relation to Supervised Machine Learning techniques outside of Deep Learning Computer Vision and NLP, feature engineering is a key part of the process.
Emre Rençberoğlu Fundamental Techniques of Feature Engineering for Machine Learning explains that "Basically, all Machine Learning algorithms use some input data to create outputs. This input data comprise features, which are usually in the form of structured columns. Algorithms require features with some specific characteristic to work properly. Here, the need for feature engineering arises."
The features you use influence more than everything else the result. No algorithm alone, to my knowledge, can supplement the information gain given by correct feature engineering.
The image below should clarify exactly why data pre-processing is so important to the Machine Learning process.
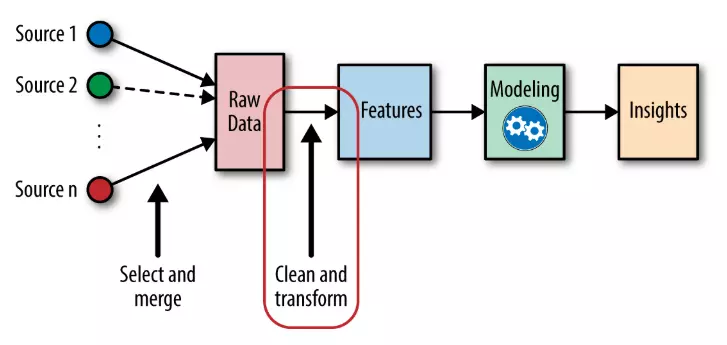
Source for Image above: Data Preprocessing - Machine Learning
In any event whether the feature engineering is handled by the algorithm itself in the case of a CNN or whether hand featured, if the data is incorrectly labelled in the training dataset then the model will learn the incorrectly labelled features as representing the ground truth it is being fed for training meaning that we'll end up with increased misclassifications in the out of sample (or real-world) performance - GIGO.
2) Aligning the business strategy and Data Science goals of the project. Asking the right questions.
Objectives of the Machine Learning or Data Science project, asking the correct question, business strategy and objective measures for success are all key for the successful outcome of a Machine Learning initiative.
Is the strategic objective to increase revenue for example grow the customer base with targeted marketing campaigns or is the aim to reduce operational costs?
It is important to have a very clear objective for the project that can be measured and evaluated from the outset. One could argue that this should be number one on the list but I believe all organisations should at least start with ensuring a clear Data Strategy from the outset as we enter a data driven world.
Not having a clearly defined objective is often a major reason why Machine Learning projects fail.
Alberto Artasanchez authored an article published in KDnuggets entitled "9 Reasons why your machine learning project will fail" and suggested that asking the wrong question was a major reason for projects to fail.
"If you ask the wrong questions, you will get the wrong answers. An example comes to mind from the financial industry and the problem of fraud identification."
The starting point maybe to question whether a given transaction is fraudulent. In order to assess whether or not that is the case, one will require a dataset that comprises fraudulent and non-fraudulent examples of transactions. It is highly likely that the labelled dataset maybe created with the assistance of humans for example a number of experts in the subject matter who are trained in fraud detection.
The challenge is that the dataset maybe labelled with examples of fraudulent behaviour that the experts experienced in the past. Hence the model will capture patterns of fraud that relate to the previous pattern of fraud. Whereas if a bad actor develops a novel technique to commit fraud, our system may be unable to detect it.
Artasanchez suggests that the optimal question to ask maybe “Is this transaction anomalous or not?”.
Business and strategic alignment with the Data Science team is imperative for a successful outcome of the Machine Learning process.
For objective measures to evaluate the Machine Learning project we need to have an objective baseline that would show us what Business As Usual would constitute. This will go back to point one above and the data. We should be able to measure and evaluate what the current cost of a problem to a company is of a given problem (for example unplanned outages and the resulting losses to manufacturing runs and asset life degradation) in order to accurately evaluate the Return on Investment (ROI) from the investment into the Machine Learning project. If we are unable to evaluate the current problem then how can we ever evaluate whether the Machine Learning generated a positive ROI?
What is the C-level strategic objective for the organisation? How does it fit into the product business strategy?

Will it be a focus on the left side of Porter's generic strategies and hence be related to efficiency gains, or will it be on adding differentiation to services for example enhancing the personalisation of the offering and targeted marketing campaigns.
The C-Level including the CEO need to take ownership of the Machine Learning and Data Science development within the organisation. They need to decide how to build it into the fabric of the organisation as a Core Competence.
Source for image above: Prahalad and Hamel The Core Competence of the Corporation
3) Algorithm
The business and Data Science teams need to consider the correct algorithm in relation to the problem that they are seeking to address and the data that they possess. It is not just about going for the most exciting cutting edge algorithm as that will not always be relevant given the particular use case. The latest state of the art approaches in the research papers often need the organisation to have access to an advanced research team and may relate to areas such as Computer Vision, Natural Language Processing, or Autonomous Robotics. For many organisations if they are relatively new to Machine Learning then it maybe sensible to consider "Keep It Simple Straightforward (KISS)".

An initial focus on KISS rather thank seeking to solve for the most complex and challenging problems from the immediate start is more likely to result in a positive outcome for the Machine Learning initiatives across the organisation.
In many cases Machine Learning projects to date entail supervised learning approaches which as noted in point one above requires the sufficient availability of quality labeled data.
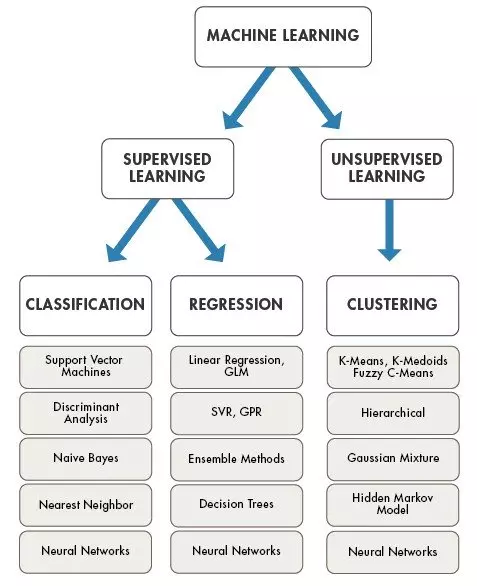
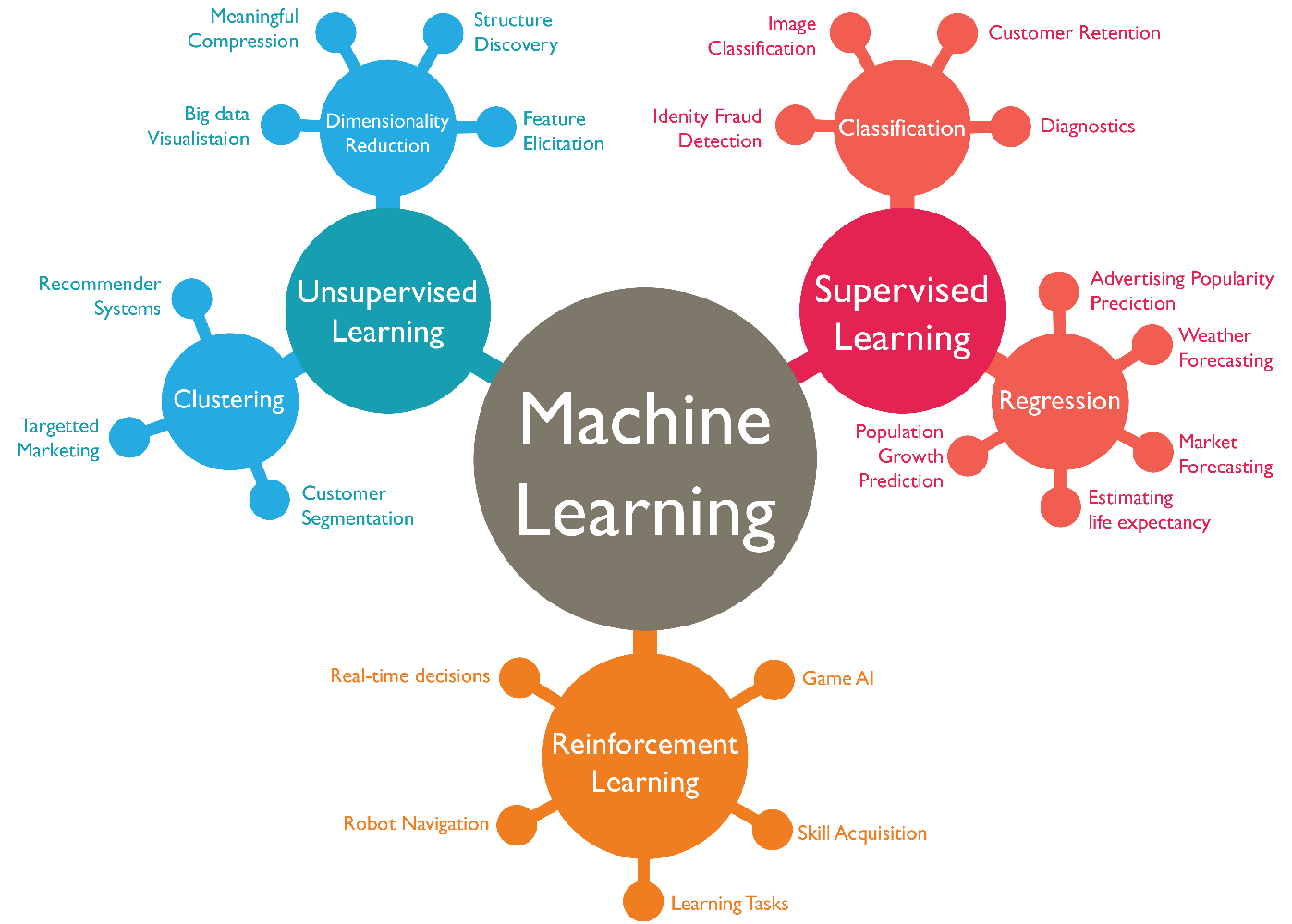
However, I set out the main approaches to Machine Learning for reference and also as some maybe seeking to address areas such as clustering and segmentation with unsupervised learning.
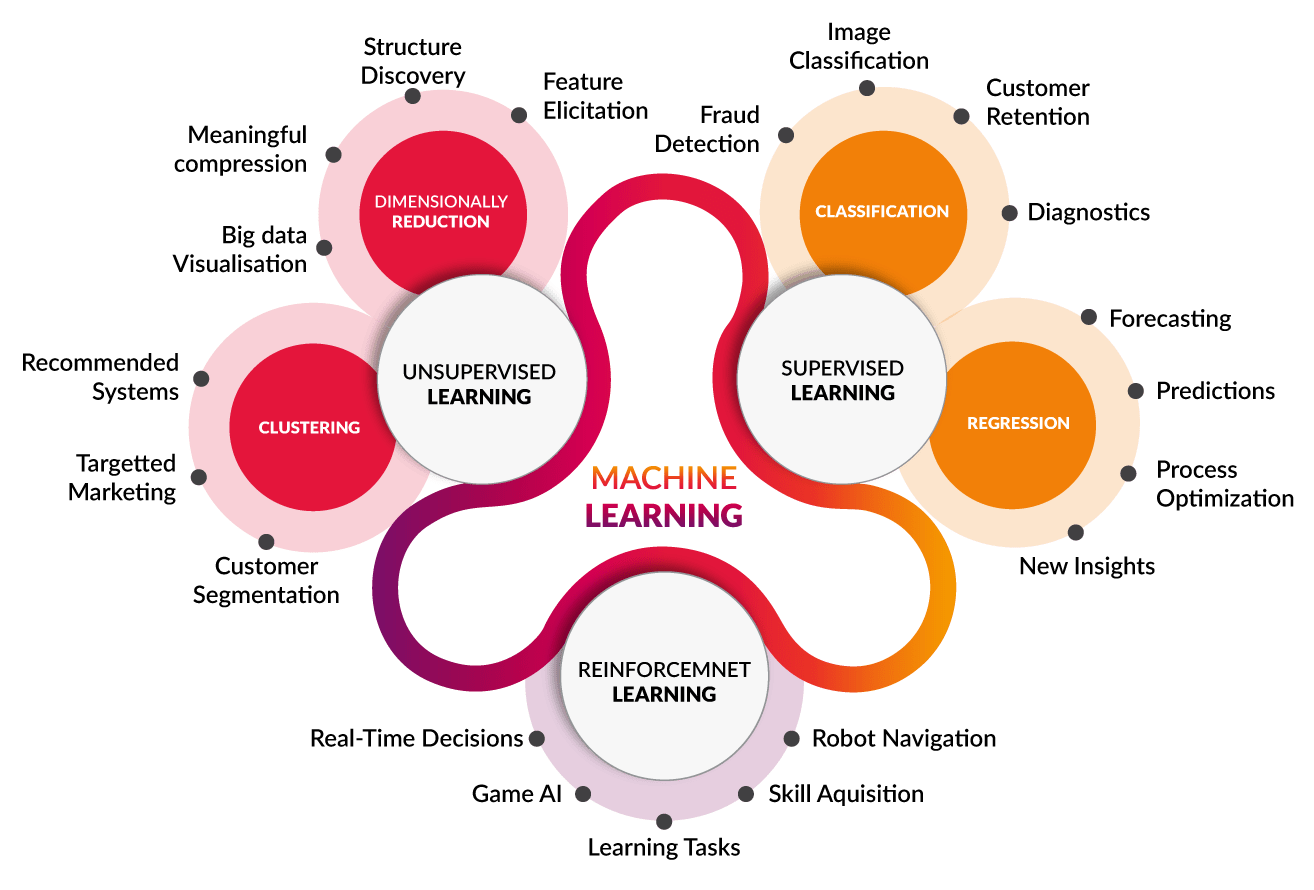
Source for image above Cognub
The Types of Machine Learning
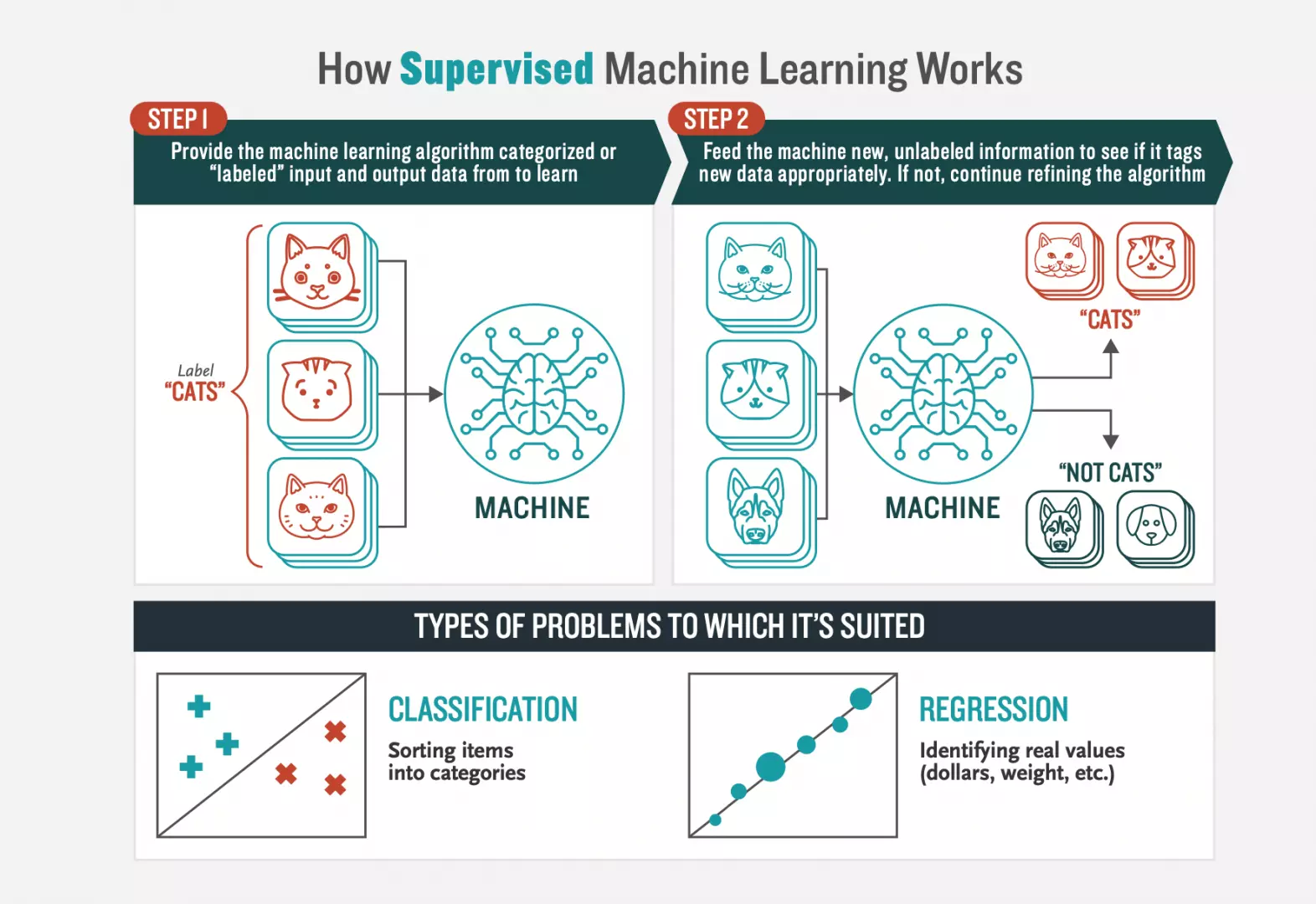
Supervised Learning: a learning algorithm that works with data that is labelled (annotated). For example learning to classify fruits with labelled images of fruits as apple, orange, lemon, etc.
Unsupervised Learning: is a learning algorithm to discover patterns hidden in data that is not labelled (annotated). An example is segmenting customers into different clusters.
Semi-Supervised Learning: is a learning algorithm when only when a small fraction of the data is labelled.
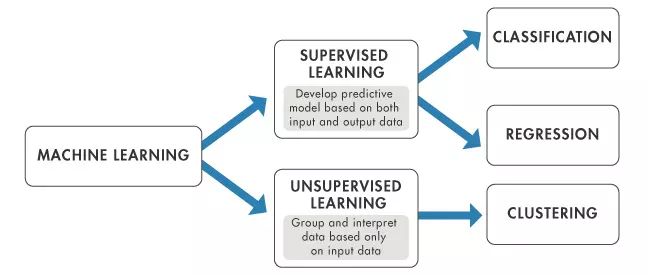
Regression, Clustering and Classification are the 3 main areas of Machine Learning.
Classification summarised by Jason Brownlee "is about predicting a label and regression is about predicting a quantity. Classification is the task of predicting a discrete class label. Classification predictions can be evaluated using accuracy, whereas regression predictions cannot."
Regression predictive modelling is summarised by Jason Brownlee "is the task of approximating a mapping function (f) from input variables (X) to a continuous output variable (y). Regression is the task of predicting a continuous quantity. Regression predictions can be evaluated using root mean squared error, whereas classification predictions cannot."
Clustering summarised by Surya Priy "is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups. It is basically a collection of objects on the basis of similarity and dissimilarity between them."
Reinforcement Learning: is an area that deals with modelling agents in an environment that continuously rewards the agent for taking the right decision. An example is an agent that is playing chess against a human being, An agent gets rewarded when it gets a right move and penalised when it makes a wrong move. Once trained, the agent can compete with a human being in a real match.
It maybe that the solution requires a Regression based approach or is a Classification issue
Source for image above Mathworks
Supervised Learning Illustrated
Source for Image Above: Booz Allen
Unsupervised Learning Illustrated
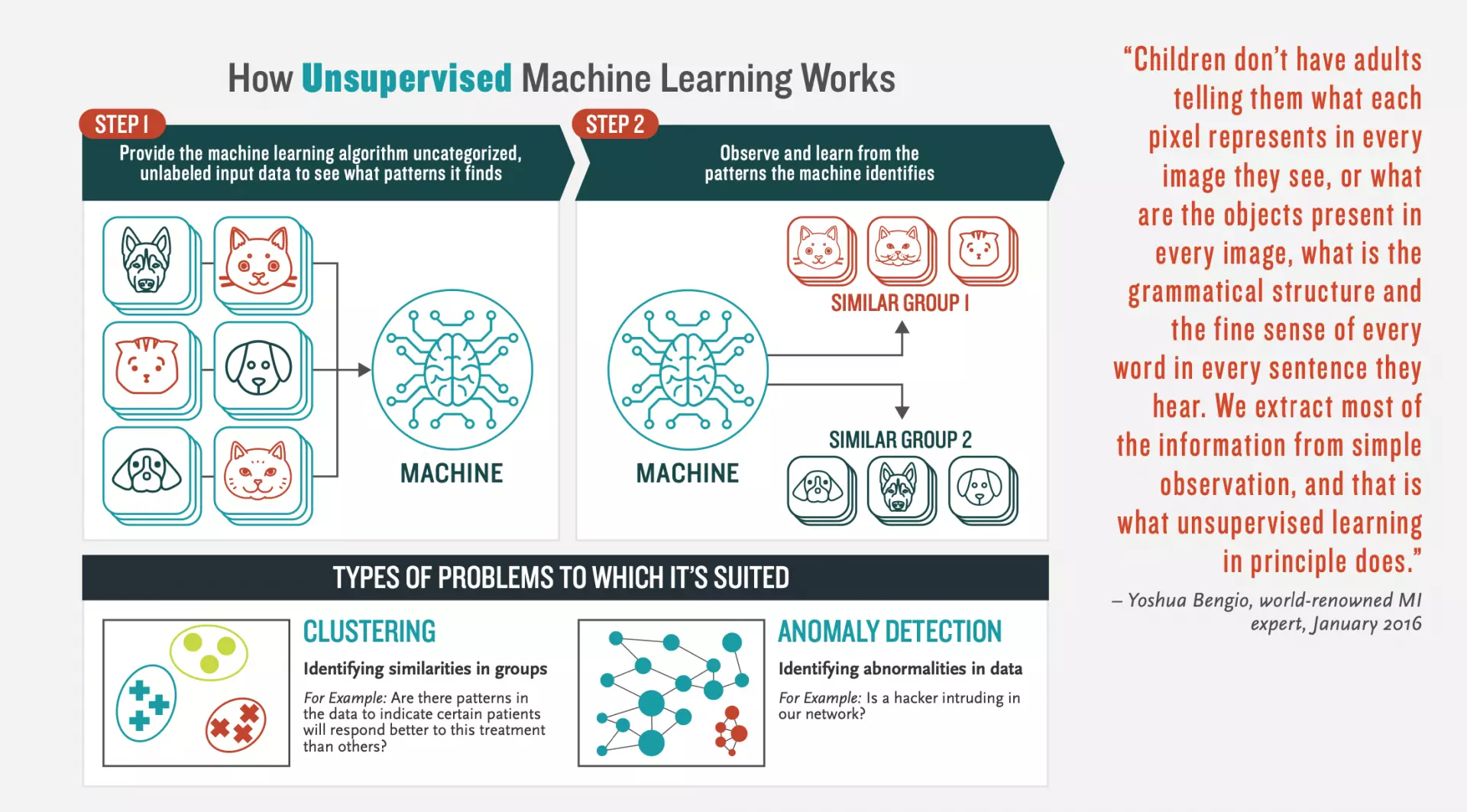
Source for Image Above: Booz Allen
Classification, Regression and Clustering
Comparison of the three common output types produced through Machine Learning. Icons made by Freepik from www.flaticon.com is licensed by CC 3.0 BY
See Blaker Lawrence Machine Learning — What it is and why it should interest you!
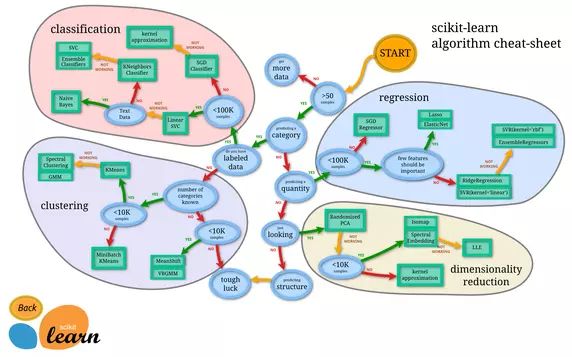
Source for image above Mathworks
Jason Brownlee "Introduction to Dimensionality Reduction for Machine Learning" states that "Dimensionality reduction refers to techniques for reducing the number of input variables in training data."
When dealing with high dimensional data, it is often useful to reduce the dimensionality by projecting the data to a lower dimensional subspace which captures the “essence” of the data. This is called dimensionality reduction.
— Page 11, Machine Learning: A Probabilistic Perspective, 2012.
"High-dimensionality might mean hundreds, thousands, or even millions of input variables."
"Fewer input dimensions often mean correspondingly fewer parameters or a simpler structure in the machine learning model, referred to as degrees of freedom. A model with too many degrees of freedom is likely to overfit the training dataset and therefore may not perform well on new data."
"It is desirable to have simple models that generalize well, and in turn, input data with few input variables. This is particularly true for linear models where the number of inputs and the degrees of freedom of the model are often closely related."
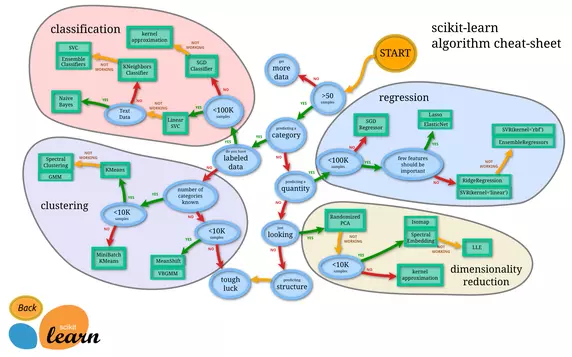
Source for Image Above ScikitLearn Choosing the Right Estimator - worth taking a look at.
A good example of Dimensionality reduction algorithm is Principal Component Analysis (PCA).
Another good illustration of Machine Learning techniques is provided by Dan Shewan 10 Companies Using Machine Learning in Cool Ways
We'll go into more detail on the algorithms in the final part of this article.
4) A Common Language and Communication
There needs to be clear communication between the Data Scientists or Machine Learning Engineers on the one hand and the business or operational team on the other.
Baskarada and Koronios Unicorn data scientist: the rarest of breeds observe that "Many organizations are seeking unicorn Data Scientists, that rarest of breeds that can do it all. They are said to be experts in many traditionally distinct disciplines, including mathematics, statistics, computer science, Artificial Intelligence, and more."
We need to find more facilitators who can help bridge the gap between the two sides of the scientists and engineers on the one hand and the business side on the other and find a common language.
A problem facing many organisations be they private sector firms of public sector organisations is that AI is not clearly understood by the business or operational teams and many Data Scientists come from strong technical backgrounds but may not have a detailed understanding of the underlying business or the objectives of the firm.
Data Scientists and Machine Learning engineers in the future will have to become more outward looking. When we code and get into the maths and data analysis we can easily become rather inward looking and introverted as we seek to abstract and solve problems. This needs to be balanced with communication.
Data Visualisation is very important for communicating in particular to a non-technical audience. Often the business and operational team will not understand some of the key metrics that we use in Machine Learning such as Confusion Matrix, and objective functions with losses. It may frustrate Data Scientists but we need to be able to communicate what we are doing and results in a manner that the commercial team can understand. Often Data Visualisation will be a key tool. An image is worth 1000 words!
Some key libraries in Python for Data Vis include:
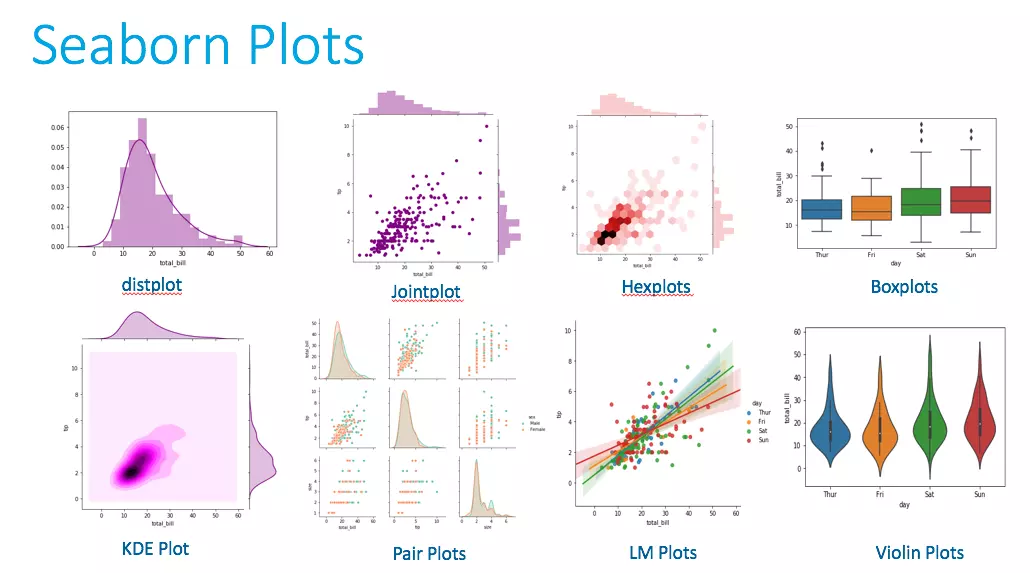
Source for image above: Mukul Singh Chauhan | Data Visualisation Using Seaborn
Others exist and the following links will provide information:
10 Python Data Visualization Libraries for Any Field | Mode
5) Culture is key!
Don't have Unrealistic Expectations and embrace a learning culture.
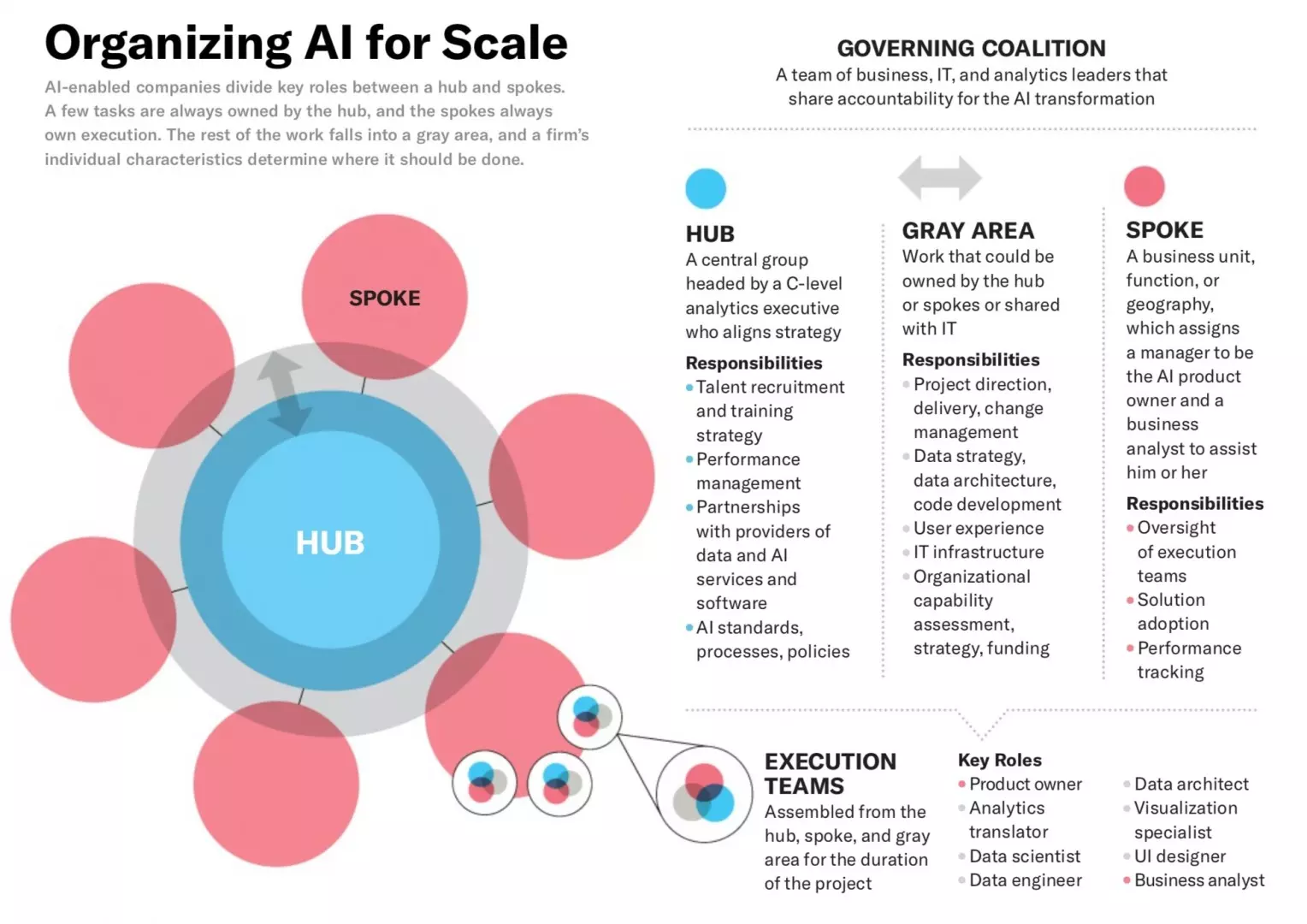
Source for Image above: Building the AI-Powered Organization. Technology isn’t the biggest challenge, culture is.
Organisations should not expect their first Machine Learning project to completely transform their organisation from the outset and magically deliver a goldmine of additional revenue or cost savings. It is going to be an incremental and iterative process. The first project(s) in Data Science and Machine Learning should be viewed a learning curve for the organisation and enable the firm to launch more ambitious projects as the learning increases across the organisation. Again it is important to have clear objectives and metrics against which to measure and evaluate whether the project was a success.
The technology majors view Tech as a revenue generator and business opportunity. Many legacy organisations view technology as a cost and burdensome necessity. Data Science and Machine Learning risk falling into the burdensome necessity in which case a cultural failure is likely form the outset. The organisation has to embrace change from the highest level at the C-level including the CEO and view technology as not just an alien territory but a core competence as JP Morgan have embraced technology and Machine Learning in the banking sector and Google in the digital world.
6) Select a realistic target for the first project: go for low hanging fruit that will enable your backend teams, business and operational staff and Data Scientists to collaborate effectively. I would not recommend Deep Reinforcement Learning as the first project for the organisation as it is a more complex area. Don't go for the most complex solutions or problems for the initial steps in AI.
Selecting the low hanging fruit goes back to point one above regarding data.
Jonathan Bowl in an article entitled "Are you missing the low-hanging fruit on your data-tree?" observes that "Many companies are missing out on the low-hanging fruit because they don’t realise how much data they already have. The data they currently do use, is mostly to monitor historic activity as opposed to powering future business performance and decisions. The problem is that the inability to use data is causing firms to miss out on vital insights, and therefore new business opportunities."
"So if businesses have access to all this data, where exactly is it? Well that’s the problem. It’s everywhere. It’s sat in different places all over the business. It’s fragmented among many departments, databases and line-of-business applications. And even for those who know of its existence, it’s incredibly frustrating because they can’t get it all in one place, which is the biggest challenge. "
"Unbelievably, we live in a world where only 5% of corporate data has been successfully analysed to drive business value. That’s a staggering 95% that is left uncovered in silos connected to solitary devices or applications, organisational silos in departments or subsidiaries with a single view on the value of that data, or cultural silos where a lack of innovation is hindering the value that data could bring."
7) Data Science Team: invest in the team properly and try to have at least one person in the team who has brought a project to production before. It is important to have the project managed by someone who has experience of a Machine Learning pipeline as they will be aware of the potential issues that may arise and how to avoid them.
The aim should be for the Data Scientists and Machine Learning engineers to become a core competence capability of the firm.
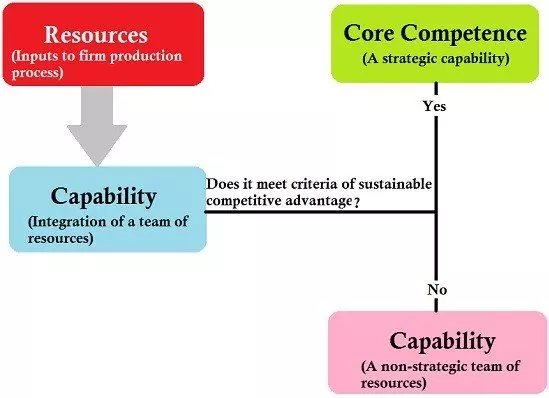
In order to achieve this there has to be sufficient investment and backing into the team.
In terms of the background of Data Scientists this can be from many areas. Typically many Data Scientists have backgrounds in Computer Science, Mathematics, Physics and other scientific (e.g. biochemistry, engineering) backgrounds. There are also others with educational backgrounds in Economics, and Finance (for example Econometrics). In Quantitative Finance we have to learn pretty much most (and often more) of the maths and statistics used in Machine Learning. That said, I believe that if the individual possesses an analytical mind, is determined and shows an aptitude for problem solving, coding and understanding of statistical methods, then that person will have what it takes to succeed.

Arpan Chakraborty 5 Skills You Need to Become a Machine Learning Engineer
Arpan Chakraborty enlists the five following skills required to succeed as a Machine Learning engineer:
1. Computer Science Fundamentals and Programming
2. Probability and Statistics
3. Data Modeling and Evaluation
4. Applying Machine Learning Algorithms and Libraries
5. Software Engineering and System Design
8) Testing, Training, Model Evaluation
We need to ensure that we have split the data into training and testing data sets. Training is what the Machine Learning model will learn from and is referred to as in sample, whereas the testing data set is referred to as a out of sample and this is where we can see whether the model has truly performing and whether it has generalised well or not.
It is often typical to split the data by 70% to 30% or 80% to 20% Training to Test.
A validation data set may also be used to evaluate a given model. For example we may split the data for example by 70%, 20%, 10% for Training, Testing, and Validation.
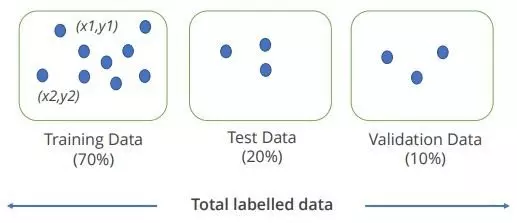
Source for Image above:Simplilearn Machine Learning
Tarang Shah About Train, Validation and Test Sets in Machine Learning explains Training, Test and Validation as follows:
Training Dataset: The sample of data used to fit the model.
"Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset."
"Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters. The evaluation becomes more biased as skill on the validation dataset is incorporated into the model configuration."
"Note on Cross Validation: Many a times, people first split their dataset into 2 — Train and Test. After this, they keep aside the Test set, and randomly choose X% of their Train dataset to be the actual Train set and the remaining (100-X)% to be the Validation set, where X is a fixed number(say 80%), the model is then iteratively trained and validated on these different sets. There are multiple ways to do this, and is commonly known as Cross Validation. Basically you use your training set to generate multiple splits of the Train and Validation sets. Cross validation avoids over fitting and is getting more and more popular, with K-fold Cross Validation being the most popular method of cross validation."
For more on k-fold Cross Validation see also Jason Brownlee A Gentle Introduction to k-fold Cross-Validation and Siladittya Manna K-Fold Cross Validation for Deep Learning Models using Keras.
Overfitting
It is important at this stage to check for Overfitting of the model.
Overfitting is a significant limitation for almost all predicting technologies. It is also one of the common biases in big data.
Underfitting refers to a model that can neither model the training data nor generalize to new data.
An underfit machine learning model is not a suitable model and will be obvious as it will have poor performance on the training data.
Jason Brownlee Overfitting and Underfitting With Machine Learning Algorithms
Elite Data Science observe that "In statistics, goodness of fit refers to how closely a model’s predicted values match the observed (true) values."
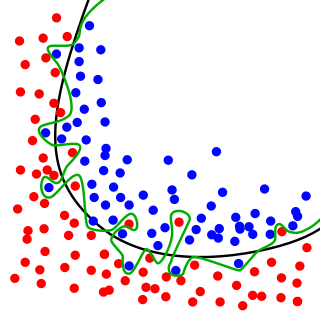
While the black line fits the data well, the green line is overfit.
To solve for overfitting we may increase the size of the training data set or decrease the complexity of the model. Further details are provided on Regularization Methods for Deep Learning and overfitting at the end of this article.
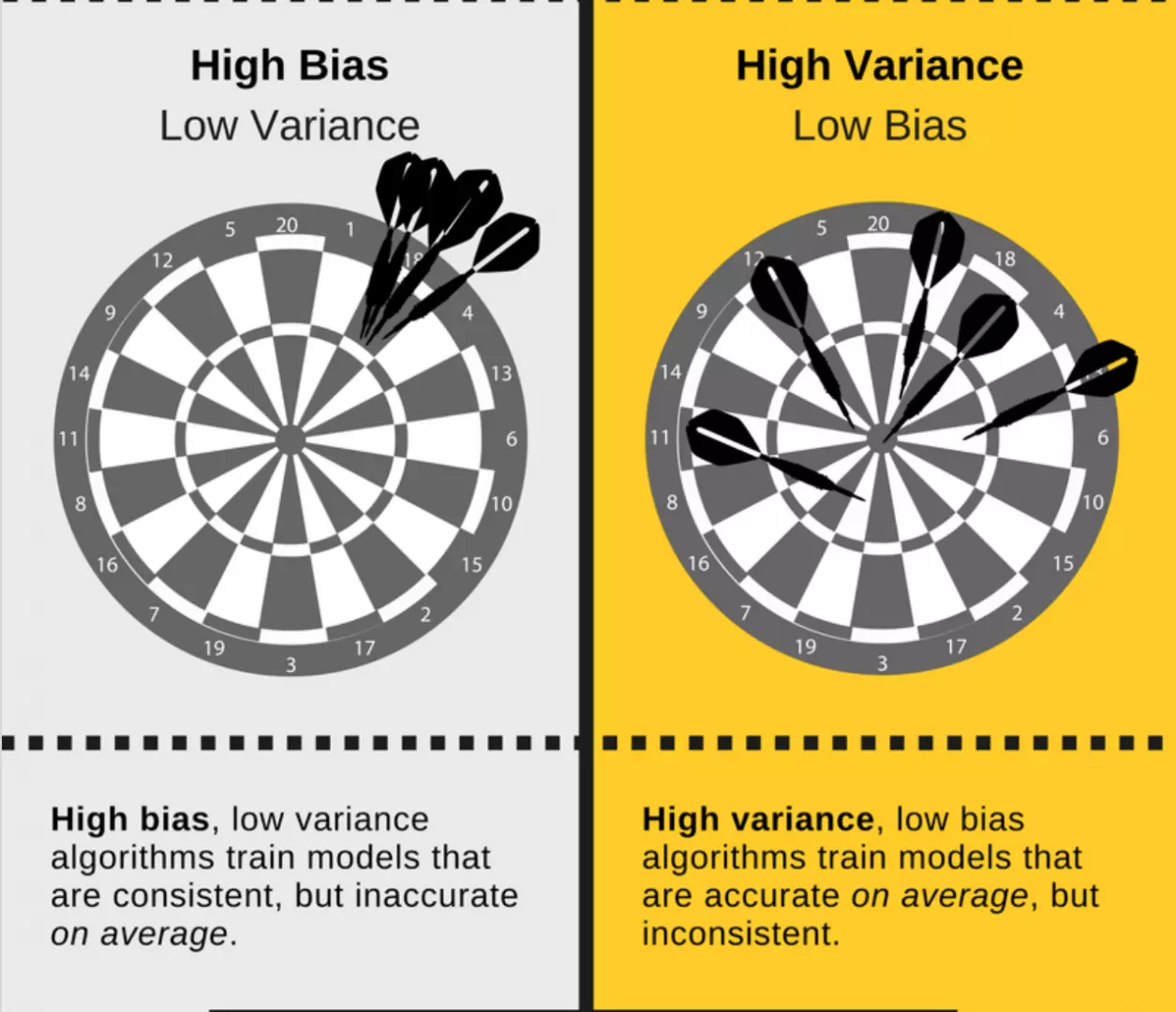
Bias / Variance Trade-off
Elite Data Science published WTF is the Bias-Variance Tradeoff? The Bias-Variance Tradeoff is relevant for supervised Machine Learning - specifically for predictive modelling. It's a way to diagnose the performance of an algorithm by breaking down its prediction error.
In Machine Learning, an algorithm is simply a repeatable process used to train a model from a given set of training data.
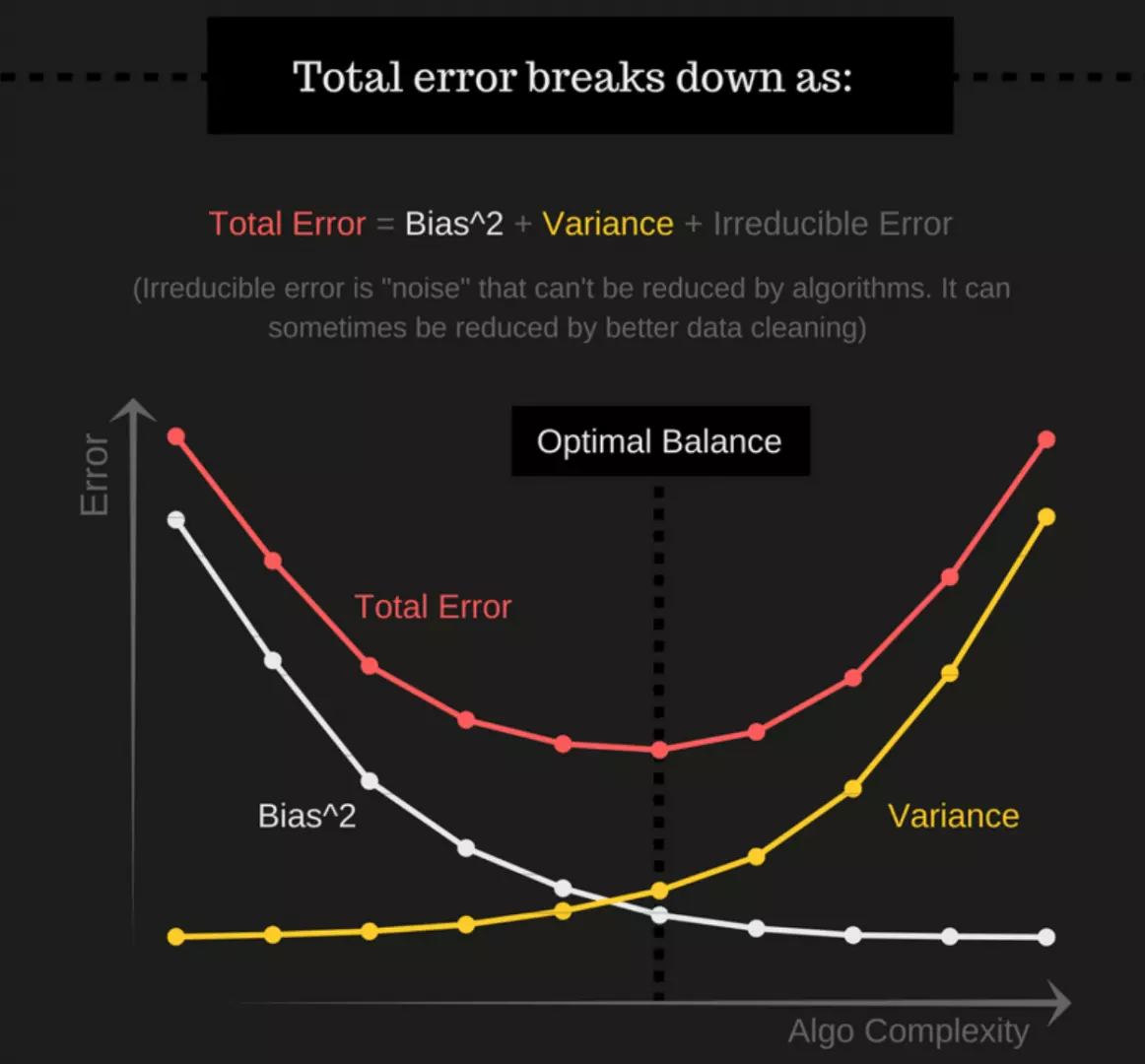
"There are 3 types of prediction error: bias, variance, and irreducible error."
"Irreducible error is also known as "noise," and it can't be reduced by your choice in algorithm. It typically comes from inherent randomness, a mis-framed problem, or an incomplete feature set."
"The other two types of errors, however, can be reduced because they stem from your algorithm choice."
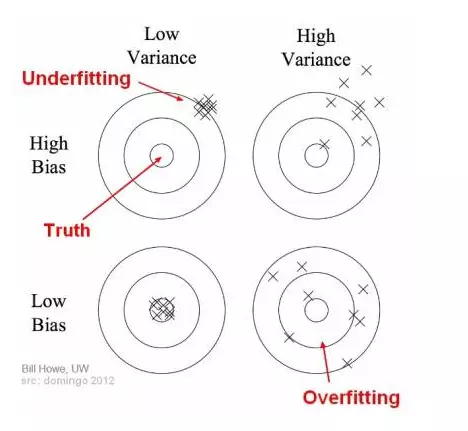
For more on Image Above see: Seema Singh Understanding the Bias-Variance Tradeoff
Bias is the difference between your model's expected predictions and the true values.
Seema Singh Understanding the Bias-Variance Tradeoff explains that "Bias is the difference between the average prediction of our model and the correct value which we are trying to predict. Model with high bias pays very little attention to the training data and oversimplifies the model. It always leads to high error on training and test data."
Seema Singh Understanding the Bias-Variance Tradeoff further explains "Variance is the variability of model prediction for a given data point or a value which tells us spread of our data. Model with high variance pays a lot of attention to training data and does not generalize on the data which it hasn’t seen before. As a result, such models perform very well on training data but has high error rates on test data."
Seema Singh Understanding the Bias-Variance Tradeoff also explains that"If our model is too simple and has very few parameters then it may have high bias and low variance. On the other hand if our model has large number of parameters then it’s going to have high variance and low bias. So we need to find the right/good balance without overfitting and underfitting the data."
"This tradeoff in complexity is why there is a tradeoff between bias and variance. An algorithm can’t be more complex and less complex at the same time."
Total Error
"To build a good model, we need to find a good balance between bias and variance such that it minimizes the total error."
Source for three images below: Elite Data Science WTF is the Bias-Variance Tradeoff?

In Machine Learning in order to find the optimal solution, we need some way of measuring the quality of any solution. This is done via what is known as an objective function, with the objective applied in the sense of a goal.
Jason Brownlee What Is a Loss Function and Loss? states that "In the context of an optimization algorithm, the function used to evaluate a candidate solution (i.e. a set of weights) is referred to as the objective function."
"We may seek to maximize or minimize the objective function, meaning that we are searching for a candidate solution that has the highest or lowest score respectively."
"Typically, with neural networks, we seek to minimize the error. As such, the objective function is often referred to as a cost function or a loss function and the value calculated by the loss function is referred to as simply “loss.”"
In Data Science we may evaluate the resulting model using a Confusion Matrix as a technique for summarizing the performance of a classification algorithm.
Rachel Draelos in "Measuring Performance: The Confusion Matrix "observes that "Confusion matrices are calculated using the predictions of a model on a data set. By looking at a Confusion Matrix, you can gain a better understanding of the strengths and weaknesses of your model, and you can better compare two alternative models to understand which one is better for your application. Traditionally, a confusion matrix is calculated using a model’s predictions on a held-out test set."
This is an example of a Confusion Matrix:

"The column labels “Actually Positive” and “Actually Negative” refer to the ground-truth labels in your data set, i.e. whether a handwritten digit is truly a 1 or a 0, whether a patient was truly diagnosed with a disease (1) or not (0), whether a chest x-ray actually shows pneumonia (1) or not (0), etc."
"The row labels “Predicted Positive” and “Predicted Negative” refer to your model’s predictions, i.e. what your model thinks the label is."
See also:
Classification: ROC Curve and AUC
Sarang Narkhede Understanding AUC - ROC Curve
How to Use ROC Curves and Precision-Recall Curves for Classification
For details of evaluating a regression model see Songhau Wu Best metrics to evaluate Regression Model?
For more details on evaluating Machine Learning models see Alvira Swalin Choosing the Right Metric for Evaluating Machine Learning Models — Part 2
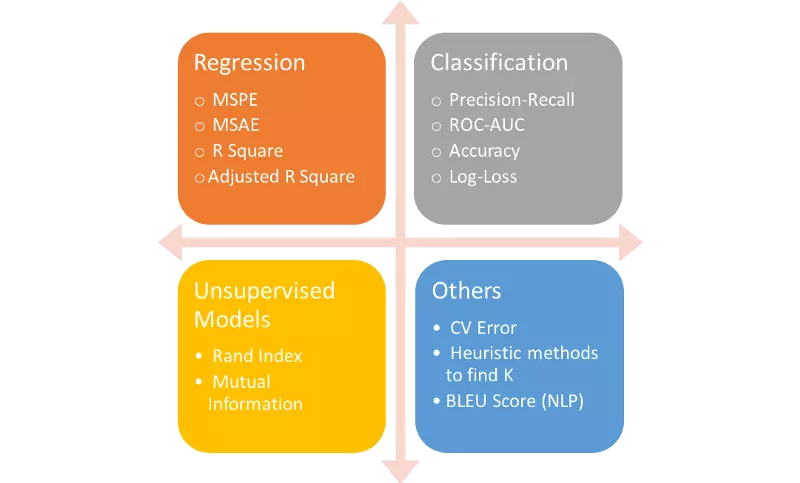
Source for Image Above: Alvira Swalin Choosing the Right Metric for Evaluating Machine Learning Models — Part 2
9) Deploying the Model to Production
Once we have evaluated our models for performance and are satisfied with the results we move onto deployment.
This will require close cooperation between the backend team, Dev Ops and the Data Science team.
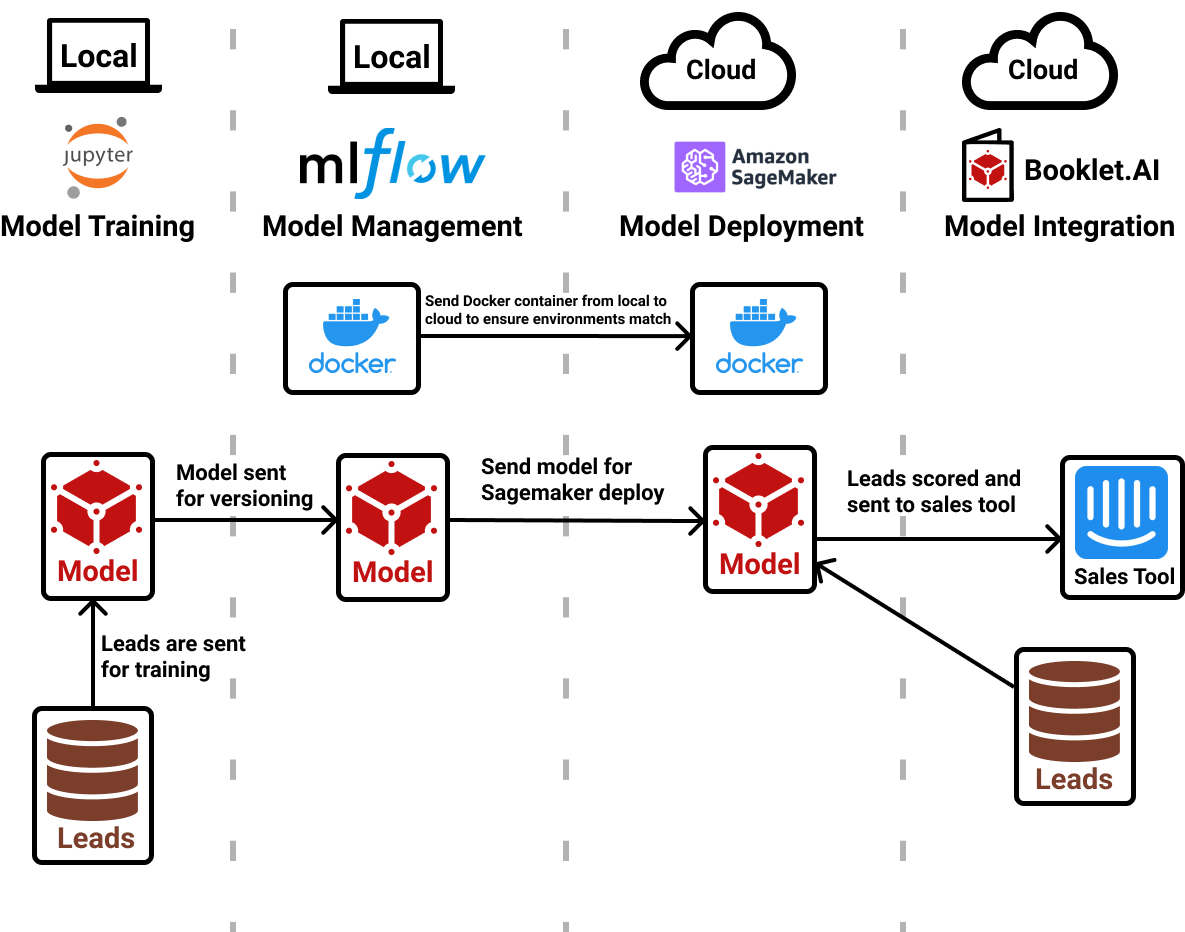
Source for Image Above: Adam Barnhard A True End-to-End ML Example: Lead Scoring
"Deploying models: In order to make a model accessible, you need to deploy the model. This means hosting your model as an API endpoint, so that it is easy to reference and score against your model in a standard way. There is a super long list of tools that deploy models for you. MLflow isn’t actually one of those tools. Instead, MLflow allows easy deployment of your managed model to a variety of different tools. It could be on your local machine, Microsoft Azure, or AWS Sagemaker."
Julien Kervizic Overview of Different Approaches to Deploying Machine Learning Models in Production
"Choosing how to deploy a predictive models into production is quite a complex affair, there are different way to handle the lifecycle management of the predictive models, different formats to stores them, multiple ways to deploy them and very vast technical landscape to pick from."
"Understanding specific use cases, the team’s technical and analytics maturity, the overall organization structure and its’ interactions, help come to the the right approach for deploying predictive models to production."
For a further example see: Harshit Tyagi How to Develop an End-to-End Machine Learning Project and Deploy it to Heroku with Flask
Shashank Prasanna authored an article entitled "Why use Docker containers for machine learning development?" and stated that:
"Containers can fully encapsulate not just your training code, but the entire dependency stack down to the hardware libraries. What you get is a machine learning development environment that is consistent and portable. With containers, both collaboration and scaling on a cluster becomes much easier. If you develop code and run training in a container environment, you can conveniently share not just your training scripts, but your entire development environment by pushing your container image into a container registry, and having a collaborator or a cluster management service pull the container image and run it to reproduce your results."
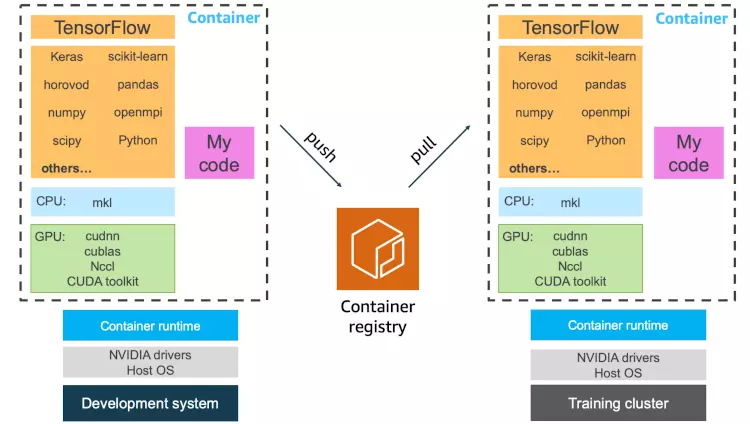
Source for image above: Shashank Prasanna Why use Docker containers for machine learning development?
Dario Redicic Let’s Deploy a Machine Learning Model stressed that we need to "Ensure that continued monitoring and evaluation of results of the Machine Learning model to check for performance over time. Using architecture with a container such as Docker can be very useful for implementation and future revisions. For more complex builds and projects Kubernates solutions may be considered."
This may require working with a Devops specialist or team who have a proven track record and experience.
Jonathan Johnson notes in Containerized Machine Learning: An Intro to ML in Containers
Training an ML model on your own machine, without containerizing, can:
Containerizing your ML workflow requires putting your ML models in a container (Docker is sufficient), then deploying it on a machine. Kubernetes is the most modern container orchestration tool, and all the major cloud providers offer it.
10) Documentation
Ensure that everything is documented both in line commenting on the code and also an overall document that explains what was done and ensure that the document is complete and accurate by requiring the team to run everything past the project manager and test against the document. People may leave. If the resource is lost, you need to be confident that anyone talking their place in the future can successfully take over the project and manage it.
Commence with appropriate documentation at the very start of the process.
11) AI and Machine Learning Governance at the Board Level
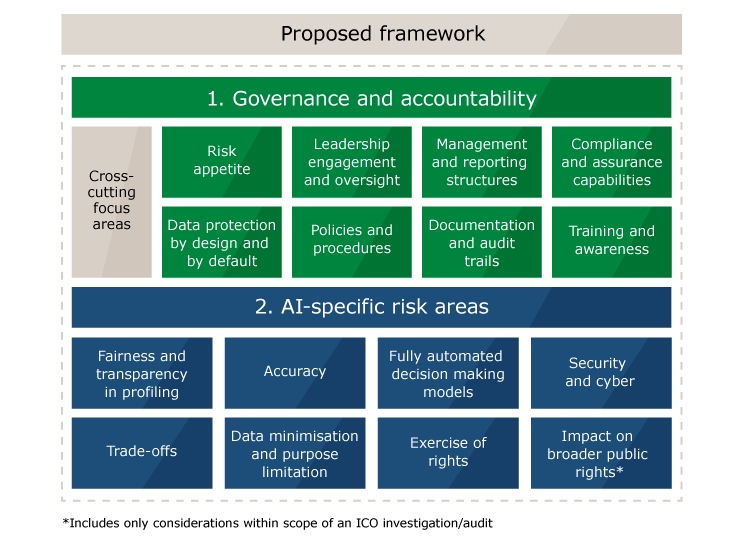
Source for the image above: Kenn So The emergence of the professional AI risk manager
Firms need to take responsibility for AI at a board level and implement a firm wide policy that the Data Science and business teams will adopt. Key aspects will include:
Ethics: ensure that various potential issues have been considered. Tay, the chatbot launched by Microsoft on Twitter with the intention of learning from users quickly became target of extremists resulting in Tay picking up racists and other offensive language. Microsoft ended up having to quickly pull Tay.
Diversity: gender and race. Is our underlying dataset inherently bias in a manner that it would unfairly discriminate and is there sufficient diversity within the Data Science team. An example is Google's face detection classifying black faces as animals.
CNET published Why facial recognition's racial bias problem is so hard to crack "Good luck if you're a woman or a darker-skinned person."
"There are various reasons why facial recognition services might have a harder time identifying minorities and women compared with white men. Public photos that tech workers use to train computers to recognize faces could include more white people than minorities, said Clare Garvie, a senior associate at Georgetown Law School's Center on Privacy and Technology."
Legal issues: including privacy such as GDPR, HIPAA, etc. For some in regulated sectors scubas financial services or healthcare there may be other ethical or legal issues that they also need to ensure compliance with.
Explainability may impact the type of Machine Learning or Data Science approach that is adopted. Explainable AI will be dealt with in my next article.
Causality: don't confuse correlation with causality. Causal inference is an area of active research in AI. Causal Inference and Machine Learning will also be dealt with in my next article.
Arjun Sethi in Why your board needs an AI Council proposes a framework for an AI Council.
What: The AI council is an advisory council with a board-level mandate to ensure that company strategy actively anticipates and keeps pace with AI advances.
Why: AI is already opening an array of previously unimagined opportunities for both the use and abuse of technology. Shareholders implicitly rely on your board to ensure that the company is taking full advantage of the former, while steadfastly safeguarding against the latter.
Specific imperatives that merit sustained AI council attention include:
Who: The AI council should combine current directors alongside outsiders who're experts in the domain.
Irrespective of their respective backgrounds, the individuals comprising the AI council need to possess an ability to look beyond the horizon and envision both the pending innovations in AI and their implications too.
12) Beyond the Horizon: Strategic agility and Strategic Innovation to constantly change and adapt
Technology including AI is not a static area. Machine Learning and in particular Deep Learning is constantly evolving. We will often find that techniques that were state of the art 3 years ago are no longer the cutting edge (for example Transformers edging out RNNs including LSTMs in Natural Language Processing). Moreover, there may be changes in our underlying datasets or we may have changes in the underlying market structure of our products and customers.
To remain successful organisations have to constantly embrace change and respond dynamically. Machine Learning is an iterative and ongoing process. The Digital Transformation process is not static and nor does it have a clearly defined end. The digital segment will evolve and once the organisation has embraced becoming a Data-Driven organisation with Machine Learning, it will have to continue to learn and evolve in order to continue to extract value from the data, remain ahead of competitors and deliver satisfaction to its customers.
Furthermore, Machine Learning and Deep Learning is set to move to the Edge (on device) as 5G networks scale in the period 2021 to 2025. 5G networks will not only be far faster than 4G networks with substantially reduced latency they will also increase device connectivity substantially in turn allowing more connected devices.
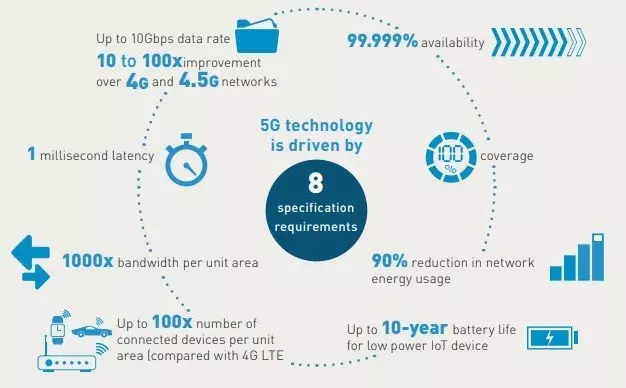
Source for image above: ThalesGroup Introducing 5G technology and networks (speed, use cases and rollout)

Source for image above: ThalesGroup Introducing 5G technology and networks (speed, use cases and rollout)
Statista forecast that by 2025 there will be over 75 billion connected devices which amounts to approximately 9 per person on the planet! Organisations will need Machine Learning and Deep Learning to make sense of the deluge of data.
For example by 2025, nearly 30 percent of data generated will be real-time, IDC says

Source for image above: Data Age 2025: the datasphere and data-readiness from edge to core
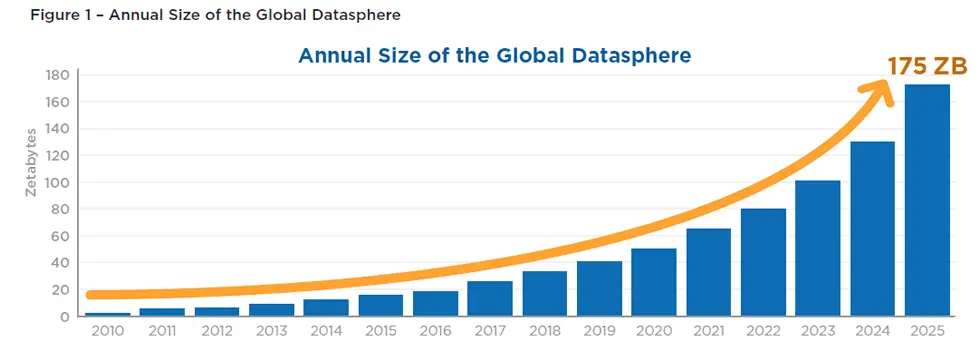
Source for image above: Annual size of the global datasphere – source: IDC Datasphere whitepaper – download here (PDF opens)
The emergence of hybrid edge cloud computing entails training the model on the cloud and then deploying onto the edge with inferencing on the device.
For more information see: Martin Percival Making way for cloud edge adoption: it starts with the hybrid cloud
Federated Learning with Differential Privacy may also emerge as a key technique in the era of 5G networks and Edge computing with decentralised data.
Frameworks include:
Google posted a blog in 2017 entitled “Federated Learning: Collaborative Machine Learning without Centralised Training Data” along with details of novel technique termed federated optimisation “Federated Optimization: Distributed Machine Learning for On-Device Intelligence” (Oct. 2016).
ODSC - Open Data Science published What is Federated Learning? where they state the following:
"Federated Learning is an approach that downloads the current model and computes an updated model at the device itself (ala edge computing) using local data. These locally trained models are then sent from the devices back to the central server where they are aggregated, i.e. averaging weights, and then a single consolidated and improved global model is sent back to the devices."
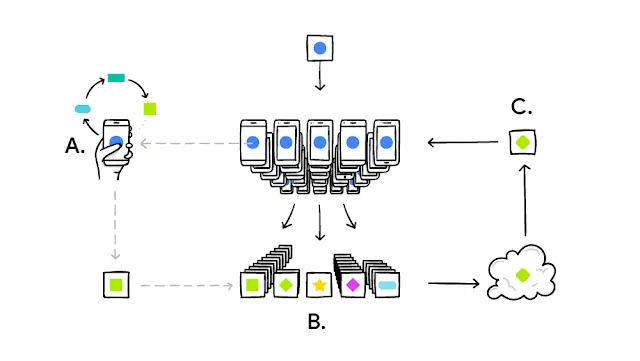
Source for image above: ODSC - Open Data Science published What is Federated Learning?
Your phone personalizes the model locally, based on your usage (A). Many users’ updates are aggregated (B) to form a consensus change (C) to the shared model, after which the procedure is repeated.
Source: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
In summary the environment that we live in is not static. Our world is dynamic and Digital Technology is constantly evolving. The pace of change and Digital Transformation is set to rapidly accelerate in the period 2022 to 2025 and for organisations not to be left on the wayside and become irrelevant to their customers they need to embrace AI technology and also adopt strategic agility and an innovation culture to respond to the pace of Digital Transformation as we enter the era of 5G and industry 4.0 with the the AIIoT.
At the very least organisations should become comfortable and experienced with successfully implementing the Machine Learning techniques of today to generate ROI and learn about the potential benefits of the technology.
This section will focus from Random Forest and Gradient Boosting models onto Deep Learning techniques.
However, as I sometimes receive questions about clustering and segmentation I suggest that those organisations commence with k-Means.
Kevin Arvai authored an article entitled K-Means Clustering in Python: A Practical Guide and observed that:
"The k-means clustering method is an unsupervised machine learning technique used to identify clusters of data objects in a dataset. There are many different types of clustering methods, but k-means is one of the oldest and most approachable. These traits make implementing k-means clustering in Python reasonably straightforward, even for novice programmers and Data Scientists."
Source for image above sklearn.cluster.KMeans
For more on clustering and source of the Image Above see: Scikit-Learn Clustering
Boosting and Ensemble Models
This is a method used to take several weak learners that perform poorly and then combine these weak learners into a strong classifier. Adaptive boosting (AdaBoost) can be applied towards both classification and regression problems and creates a strong classifier by combining multiple weak classifiers
Ensemble Learning techniques have proved popular and effective tools for a number of problems that companies maybe seeking to solve for. A good example is the Random Forest model. For an overview of Random Forest see How to Develop a Random Forest Ensemble in Python.
Dinesh Bacham and Dr Janet Zhao at Moody's authored Machine Learning: Challenges, Lessons, and Opportunities in Credit Risk Modeling where they observed that "The common objective behind machine learning and traditional statistical learning tools is to learn from data. Both approaches aim to investigate the underlying relationships by using a training dataset. Typically, statistical learning methods assume formal relationships between variables in the form of mathematical equations, while machine learning methods can learn from data without requiring any rules-based programming. As a result of this flexibility, machine learning methods can better fit the patterns in data." The image below illustrates this point.
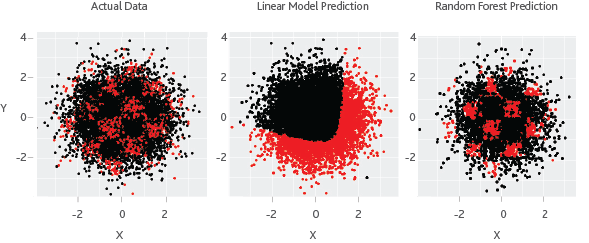
"In this simulated example, the first chart shows the actual distribution of data points with respect to X and Y, while the points in red are classified as defaults. One can relate this to a geographical map, where the X axis is longitude, and the Y axis is latitude. The areas in red represent high-risk demographics, where we see a higher default rate. As expected, a linear statistical model cannot fit this complex non-linear and non-monotonic behavior. The random forest model, a widely used machine learning method, is flexible enough to identify the hot spots because it is not limited to predicting linear or continuous relationships. A machine learning model, unconstrained by some of the assumptions of classic statistical models, can yield much better insights that a human analyst could not infer from the data. At times, the prediction contrasts starkly with traditional models."
An important advancements in Machine Learning over the past 5 years has been the evolution and rise of Boosting algorithms for Supervised Learning that have proven to be highly effective for structured data.
Recent key examples include XG Boost that proved highly successful in Kaggle competitions with tabular or structured data (see Tianqi Chen and Carlos Guestrin 2016), Light Gradient Boosting Machine (Light GBM) introduced my Microsoft in 2017, and CatBooset introduced by Yandex in 2017. For more on Ensemble Learning see the article by Jason Brownlee Ensemble Learningand an article published in kdnuggets.com entitled CatBoost vs. Light GBM vs. XGBoost.
XG Boost

LightGBM
CatBoost vs XGBoost

Kevin Vecmanis XGBoost Hyperparameter Tuning - A Visual Guide
Neptune AI Understanding LightGBM Parameters (and How to Tune Them)
Catboost tutorials
For many firms and organisations these Machine Learning techniques will deliver solutions they are seeking in relation to Data Science and analytics.
The following lecture from DataBricks summit sets out the areas where Gradient Boosting models maybe optimal to be used instead of Deep Learning models.

For areas such as Computer Vision, NLP, autonomous navigation and robotic perception, accelerating drug discovery we may look at Deep Learning approaches.
Deep Learning
Neural Networks with several hidden layers loosely inspired on the biology of the human brain are termed Deep Neural Networks. They have been responsible for many of the advancements in the field of AI research and applied AI over the course of the last decade.
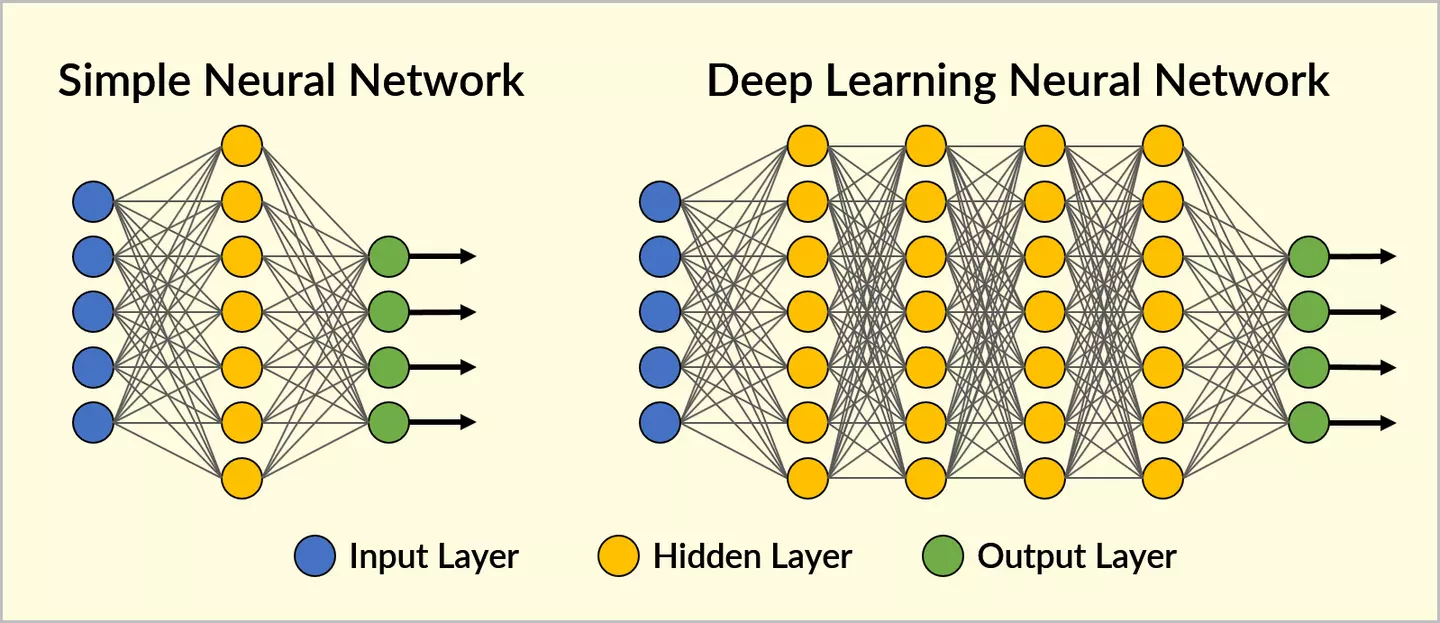
Source for image above: Ray Bernard Deep Learning to the Rescue
Techniques include
Convolutional Neural Networks (CNNs) that have revolutionised the field of Computer Vision in particular since the AlexNet team won the ImageNet competition in 2012 albeit they have been around for longer.
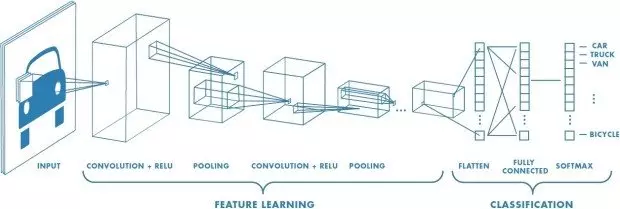
Source for image above: Mathworks Convolutional Neural Network 3 things you need to know
Example of a network with many convolutional layers. Filters are applied to each training image at different resolutions, and the output of each convolved image is used as the input to the next layer.
CNNs have been responsible for many of the recent advances in Computer Vision indecent years. The breakthrough moment occurred with the victory of AlexNet in the ImageNet competition in 2012 and precipitated the likes of Google, Facebook and other tech majors scrambling after Deep Learning experts at a time when there were not so many trained in the field.
CNNs maybe applied towards object detection, image classification and segmentation. Specific examples include:
For more see Jason Brownlee How Do Convolutional Layers Work in Deep Learning Neural Networks?
See also Pulkit Sharma A Comprehensive Tutorial to learn Convolutional Neural Networks from Scratch (deeplearning.ai Course #4)

Graph Neural Networks (GNNs) as explained by Zhou et al. "are connectionist models that capture the dependence of graphs via message passing between the nodes of graphs. Unlike standard neural networks, graph neural networks retain a state that can represent information from its neighbourhood with arbitrary depth."
Applications include chemistry with drug discovery and robotic perception.
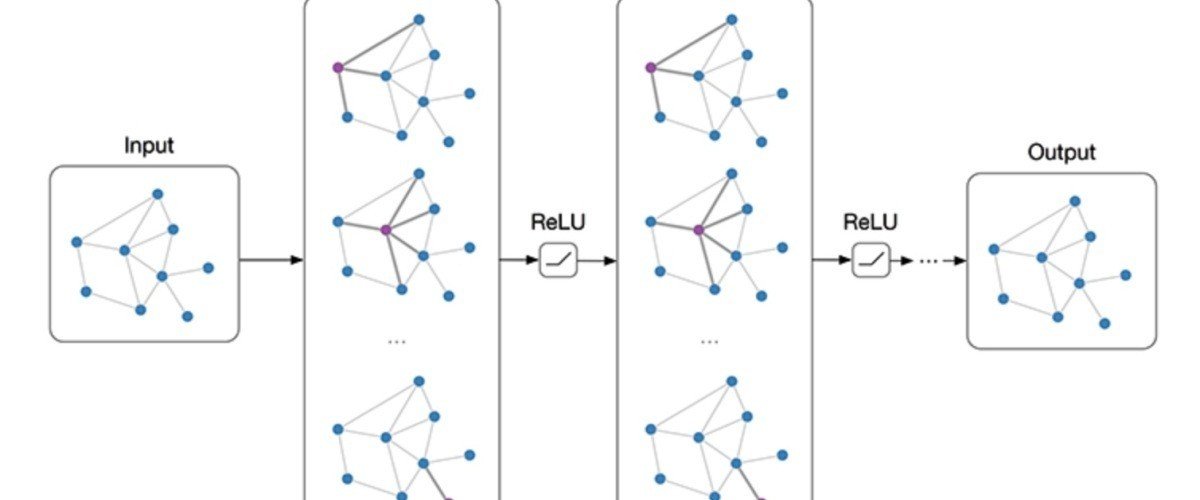
Source for image above Graph Convolutional Neural Network (Part I)
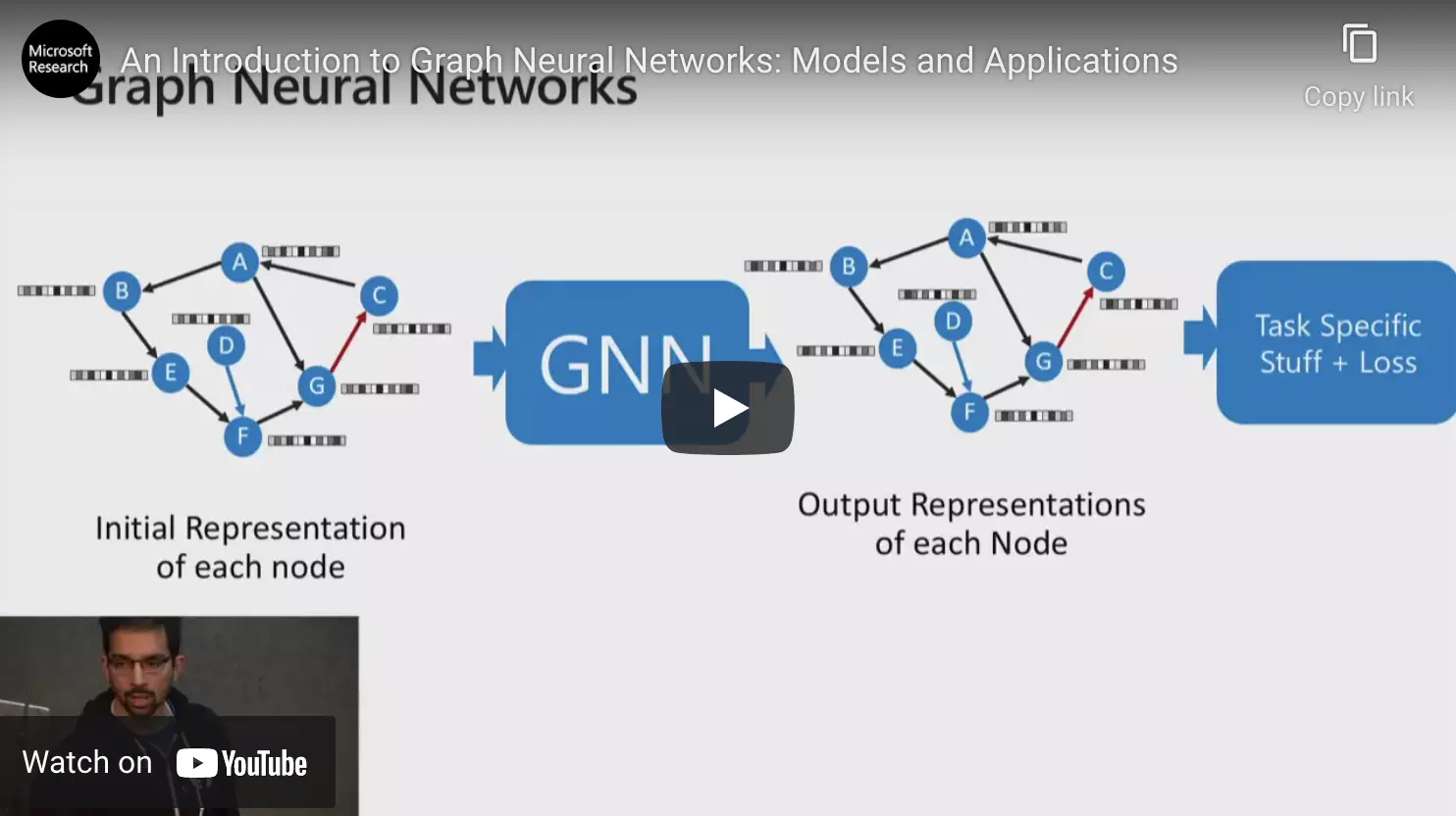
Recurrent Neural Networks (RNNs) including Long Short Term Memory (LSTM) cells, and Gated Recurrent Units (GRUs) that have been applied to Time Series and until recently were often used in NLP with Text data.
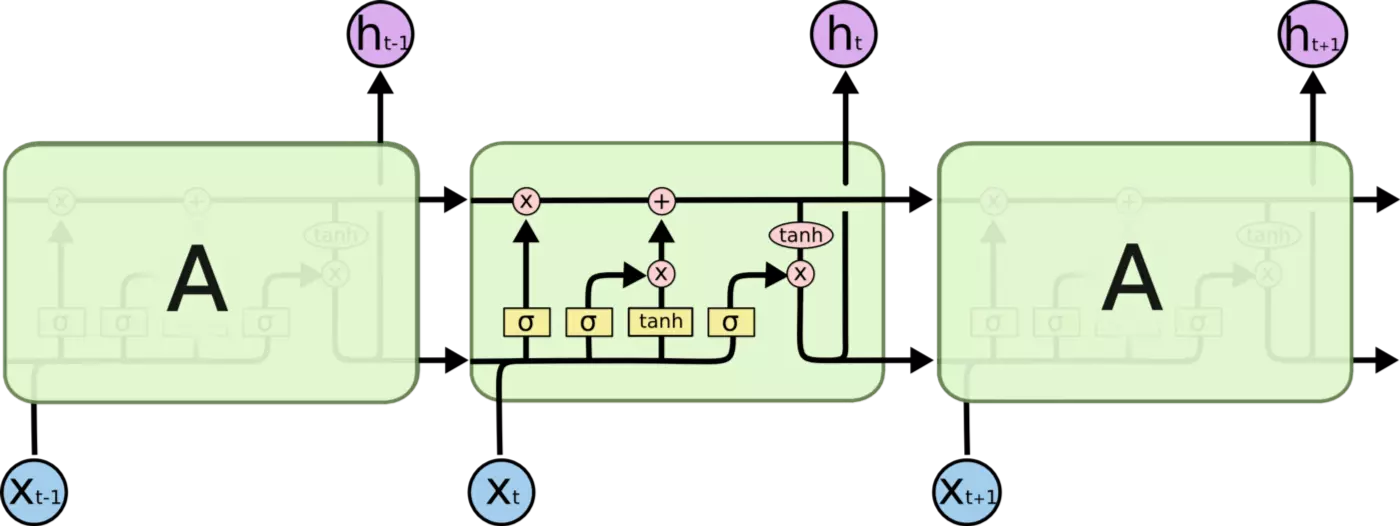
Source for LSTM Image image above Colah's Blog
Transformers with Self-Attention have literally been transforming the Natural Language Processing (NLP) space with models such as BERT and GPT-3.
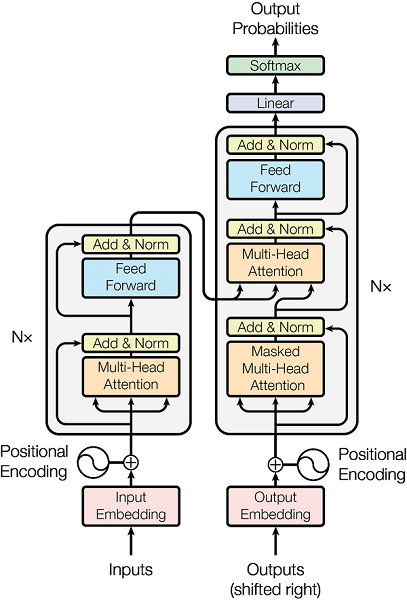
Video by The A.I. Hacker - Michael Phi Illustrated Guide to Transformers Neural Network: A step by step explanation

Transformers are starting to make their impact in the field of Computer Vision with the
An article by Wired entitled ‘Farewell Convolutions’ – ML Community Applauds Anonymous ICLR 2021 Paper That Uses Transformers for Image Recognition at Scale "A new research paper, An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale, has the machine learning community both excited and curious. With Transformer architectures now being extended to the computer vision (CV) field, the paper suggests the direct application of Transformers to image recognition can outperform even the best convolutional neural networks when scaled appropriately. Unlike prior works using self-attention in CV, the scalable design does not introduce any image-specific inductive biases into the architecture."
The paper is available on Open Review with the Abstract stating:
"While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer can perform very well on image classification tasks when applied directly to sequences of image patches. When pre-trained on large amounts of data and transferred to multiple recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc), Vision Transformer attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train."
Wikipedia defines an Autoencoder as .."a type of artificial neural network used to learn efficient data codings in an unsupervised manner. The aim of an autoencoder is to learn a representation (encoding) for a set of data, typically for dimensionality reduction, by training the network to ignore signal “noise”. Along with the reduction side, a reconstructing side is learnt, where the Autoencoder tries to generate from the reduced encoding a representation as close as possible to its original input, hence its name."
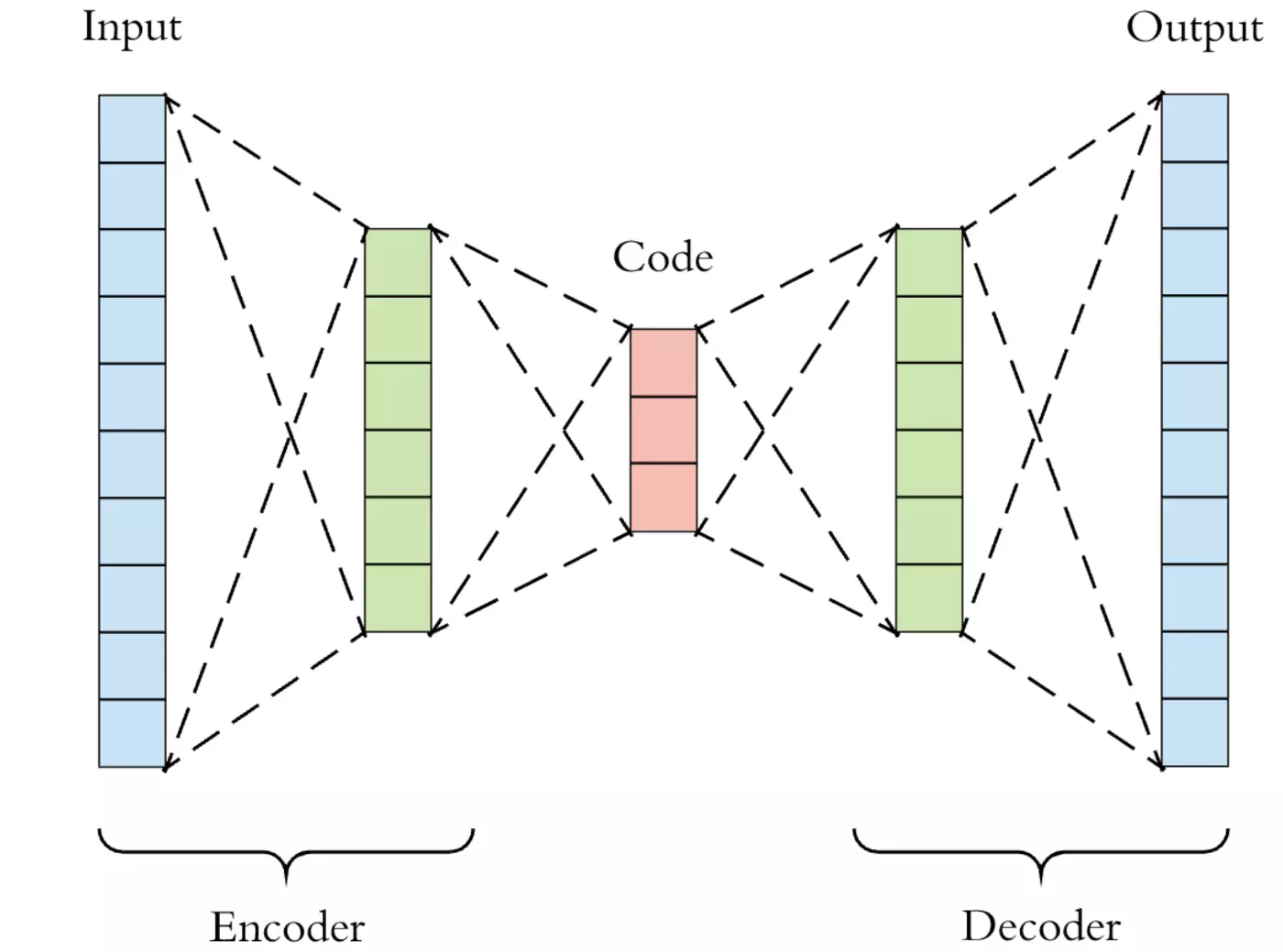
Source for Image Above: Matthew Stewart Comprehensive Introduction to Autoencoders
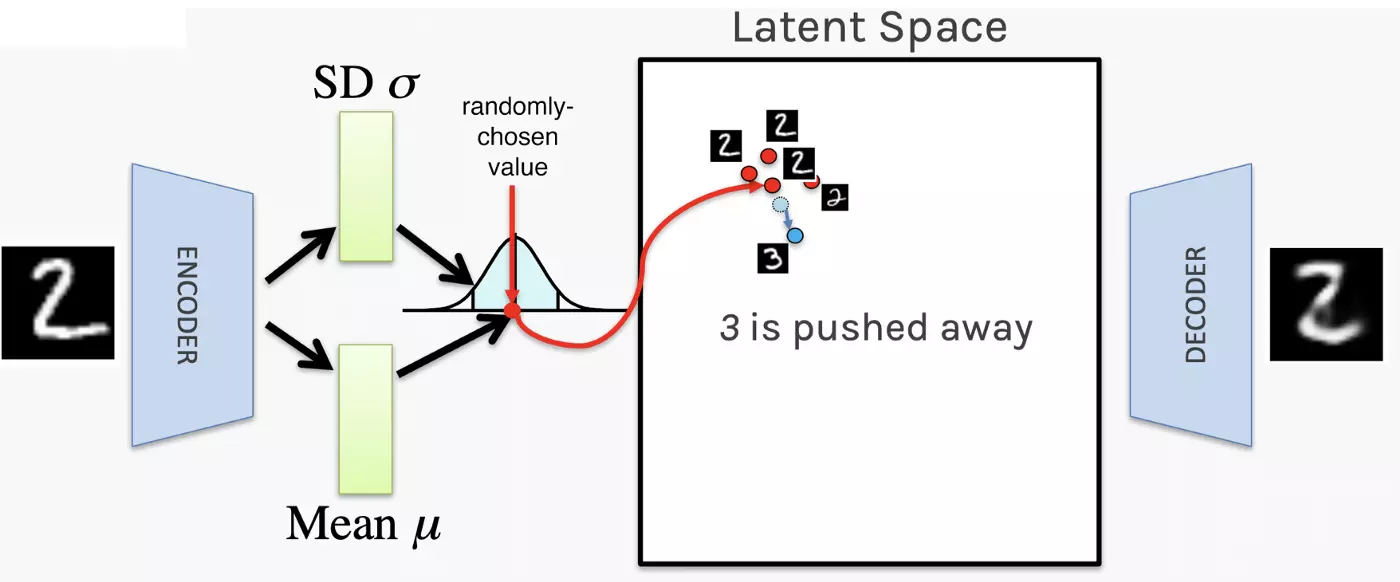
Source for Image Above: Matthew Stewart Comprehensive Introduction to Autoencoders
Wikipedia defines Variational Autoencoders (VAEs) as generative models, like Generative Adversarial Networks. "Their association with this group of models derives mainly from the architectural affinity with the basic autoencoder (the final training objective has an encoder and a decoder), but their mathematical formulation differs significantly. VAEs are directed probabilistic graphical models (DPGM) whose posterior is approximated by a neural network, forming an autoencoder-like architecture. Differently from discriminative modeling that aims to learn a predictor given the observation, generative modeling tries to simulate how the data is generated, in order to understand the underlying causal relations. Causal relations have indeed the great potential of being generalizable."
Generative Adversarial Networks (GANs) have achieved notoriety for deep fakes. As Ram Saggar notes "GANs are now capable of creating realistic images out of the noise."
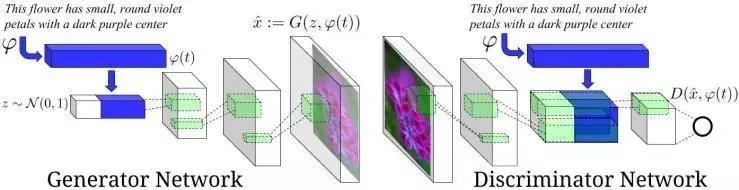
Jason Brownlee A Gentle Introduction to Generative Adversarial Networks (GANs) states that "Generative Adversarial Networks, or GANs, are a Deep Learning-based generative model."
"More generally, GANs are a model architecture for training a generative model, and it is most common to use Deep Learning models in this architecture."
The GAN architecture was first described in the 2014 paper by Ian Goodfellow, et al. in a paper entitled “Generative Adversarial Networks.”
"The GAN model architecture involves two sub-models: a generator model for generating new examples and a discriminator model for classifying whether generated examples are real, from the domain, or fake, generated by the generator model."
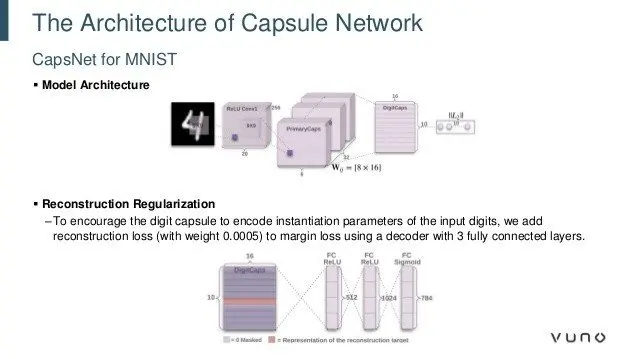
Capsules
Capsules remain an area of ongoing research.
To learn more about Capsules see: Hinton et al. Dynamic Routing Between Capsules
Hinton et al. Stacked Capsule Autoencoders is summarised by Fangyu Cai in "Geoffrey Hinton’s Unsupervised Capsule Networks Achieve SOTA Results on SVHN" with the following observation:
"Hinton and Sabour have now co-developed an unsupervised version of the capsule network in a joint research effort with the Oxford Robotics Institute. In the paper Stacked Capsule Autoencoders, they show the new approach can achieve state-of-the-art results for unsupervised classification on the SVHN (Street View House Numbers Dataset, which comprises over 600k real-world images of house numbers from Google Street View Images); and near state-of-the-art performance on the MNIST handwritten digit dataset."
"Akin to modules in human brains, capsules are outstandingly good at understanding and encoding nuances such as pose (position, size, orientation), deformation, velocity, albedo, hue, texture etc. A capsule system understands an object by interpreting the organized set of its interrelated parts geometrically. Since these geometric relationships remain intact, a system can rely on them to identify objects even with changes in viewpoint, ie translation invariance."
"The researchers used an unsupervised version of a capsule network, where a neural encoder trained through backpropagation looks at all image parts to infer the presence and poses of object capsules."
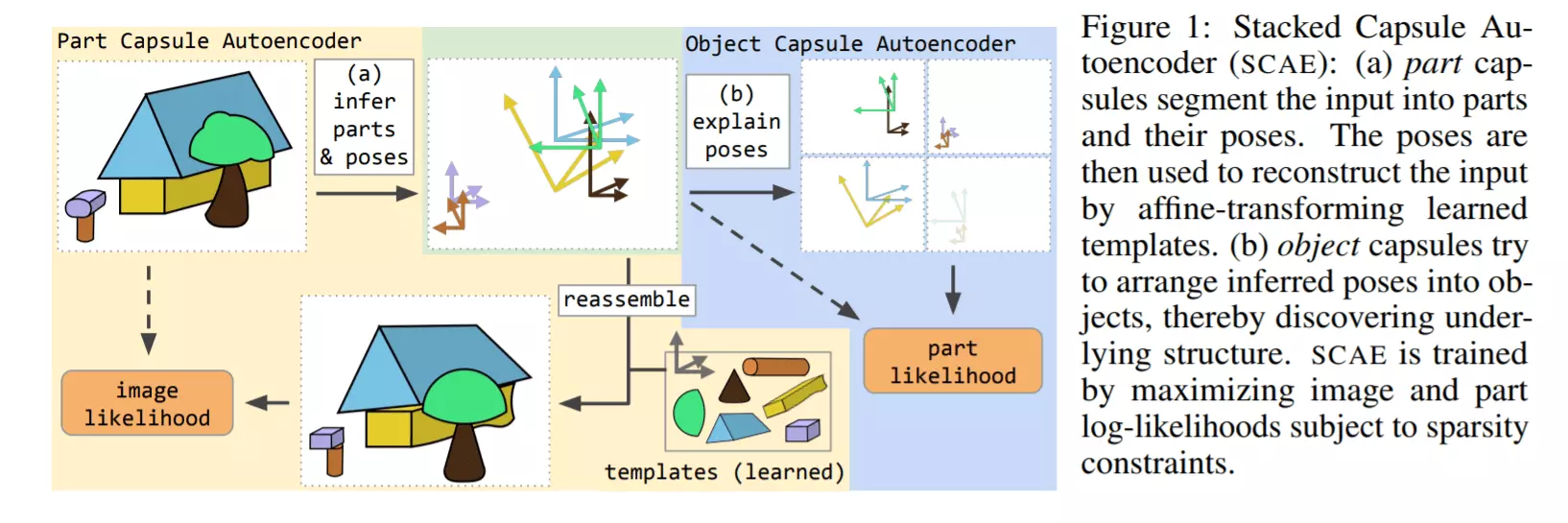
Potential application of Capsules in healthcare is provided by Wang et al. Capsule Networks Showed Excellent Performance in the Classification of hERG Blockers/Nonblockers
Huang and Zhou authored DA-CapsNet: dual attention mechanism capsule network and state the following:
"Capsule networks (CapsNets) are effective at recognizing various attributes of specific entities in the image, including pose (position, size, direction), deformation, speed, reflectivity, hue, texture, and so on. When recognizing the image, CapsNets can judge that the image is not a face. The ability of a CapsNet to recognize image attributes depends on the characteristics of the capsules. The higher the level of a capsule, the more information it grasps. The dynamic routing algorithm is used to change low-level capsules into high-level capsules. "
Transfer Learning
Jason Brownlee in A Gentle Introduction to Transfer Learning for Deep Learning defines "Transfer learning is a Machine Learning method where a model developed for a task is reused as the starting point for a model on a second task."
"It is a popular approach in Deep Learning where pre-trained models are used as the starting point on computer vision and natural language processing tasks given the vast compute and time resources required to develop neural network models on these problems and from the huge jumps in skill that they provide on related problems."
Glossary of some key terms in Machine Learning
Features / Attributes: these are used to represent the data in a form that the algorithms can understand and process. For example, features in an image may represent edges and corners.
Entropy: the amount of uncertainty in a random variable.
Information Gain: the amount of information gained as a result of some prior knowledge.
Jason Brownlee What is the Difference Between a Parameter and a Hyperparameter?
"A model parameter is a configuration variable that is internal to the model and whose value can be estimated from data."
"Parameters are key to machine learning algorithms. They are the part of the model that is learned from historical training data."
"A model hyperparameter is a configuration that is external to the model and whose value cannot be estimated from data."
Softmax: The Softmax regression is a form of logistic regression that normalises an input value into a vector of values that follows a probability distribution whose total sums up to 1.
Overfitting with Deep Learning: Deep Learning Neural Networks are likely to quickly overfit a training dataset with few examples.
Jason Brownlee How to Avoid Overfitting in Deep Learning Neural Networks observes that to reduce overfitting one may constrain the complexity of the model.
Two approaches may be applied in relation to an overfit model:
Regularization Methods for Neural Networks may entail the following"
See also Shiv Vignesh The Perfect Fit for a DNN
"Activation functions are mathematical equations that determine the output of a neural network. The function is attached to each neuron in the network, and determines whether it should be activated (“fired”) or not, based on whether each neuron’s input is relevant for the model’s prediction. Activation functions also help normalize the output of each neuron to a range between 1 and 0 or between -1 and 1."
Imtiaz Adam is a Hybrid Strategist and Data Scientist. He is focussed on the latest developments in artificial intelligence and machine learning techniques with a particular focus on deep learning. Imtiaz holds an MSc in Computer Science with research in AI (Distinction) University of London, MBA (Distinction), Sloan in Strategy Fellow London Business School, MSc Finance with Quantitative Econometric Modelling (Distinction) at Cass Business School. He is the Founder of Deep Learn Strategies Limited, and served as Director & Global Head of a business he founded at Morgan Stanley in Climate Finance & ESG Strategic Advisory. He has a strong expertise in enterprise sales & marketing, data science, and corporate & business strategist.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest