Comments
- No comments found

There are 4 concepts that are at the core of machine learning (ML): data, algorithm, a model, and statistical learning.
Machine learning is about designing algorithms that automatically extract valuable information from statistical data. The emphasis here is on correlations and “automatism”, i.e., machine learning is concerned about general-purpose methodologies that can be applied to many datasets, while producing something that is meaningful.
Since machine learning is inherently data driven, data is at the core data of machine learning. The goal of machine learning is to design general-purpose methodologies to extract valuable patterns from data, ideally without much domain-specific expertise.
A “machine learning algorithm” means a system that makes predictions based on input data, named as predictors. Or, the “machine learning algorithm” means a system that adapts some internal parameters of the predictor to perform well on future unseen input data.
A model is said to learn from data if its performance on a given task improves after the data is taken into account. The goal is to find good models that generalize well to yet unseen data, which we may care about in the future.
Learning can be understood as a learning way to automatically find patterns and structure in data by optimizing the parameters of the model.
Statistical Machine Learning involves mathematical fields, such as linear algebra, function analysis, or calculus, geometry, discrete mathematics, statistics, probability theory and mathematical programming.
But such a machine learning is missing the fundamentals of dataset theory, a foundational system for the whole of mathematics, as well as computer science and data-driven AI.
An AI dataset is not a set or multiset, list, bunch, bag, heap, sample, weighted set, collection, and suite, but a poset.
A set is merely gathering together into a whole of definite, distinct, well-defined objects, the set's elements or members, as data, numbers, people, letters of the alphabet, other sets, and so on.
Machine data/representation/concept/category learning/formation is the machine learning task of learning a function that maps an input to an output based on example input-output pairs, as the feature vector space X and its label space Y. And a learning algorithm seeks a function f, where X is the input space and Y is the output space, of some space of possible functions F, called the hypothesis space.
It infers a function from labeled training data consisting of a set of training examples, where each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a "reasonable" way.
A partially ordered set (poset) formalizes and generalizes the concept of an ordering, sequencing, or arrangement of the elements of a set.
Formally, a partial order is any binary relation that is reflexive, antisymmetric, and transitive.
A poset consists of a set together with a binary relation indicating that, for certain pairs of elements in the set, one of the elements precedes the other in the ordering. Again, there may be pairs of elements for which neither element precedes the other in the poset. Partial orders thus generalize total orders, in which every pair is comparable.
A poset can be visualized through its Hasse diagram, which depicts the ordering relation.
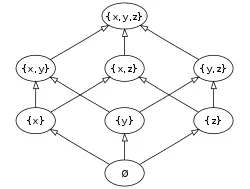
The Hasse diagram of the set of all subsets of a three-element set {x, y, z}, ordered by inclusion.
Standard examples of data posets include:
Now, a data set (or dataset) is defined as a collection of data, listing values for each of the variables for each member of the data set. In the case of tabular data, a data set corresponds to database tables, where every column represents a particular variable or feature and attribute, and each row corresponds to a given record of the data set in question.
But data sets can also consist of a collection of documents or files. Data set is the unit to measure the information released in a public open data repository. The European Open Data portal mentions > half a million data sets.
So, no consensus about it, if not take a data poset as the common background.
Overall, there are two generations of machine learning: statistical machine learning (SML) and causal machine learning (CML).
There are 5 concepts behind causal machine learning: reality, data, causal algorithm, a causal model, and causal learning.

Science and Technology 21, New Physica by Azamat Abdoullaev - Read the e-book version here.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest