Comments
- No comments found

Large language models (LLMs) have gained immense popularity in recent years for their ability to generate human-like output.
It is important to state that tools like ChatGPT, GPT-4, DALL-E and DALL-E 2 are only as effective as the instructions provided to them. These AI models are simply tools designed to generate text and images based on the data they are trained on. Therefore, the quality and accuracy of the responses generated by these models are heavily dependent on the instructions given to them. Without clear and accurate instructions, the outputs generated by these models may be inaccurate, misleading, or even harmful. Thus, it is essential to use these tools with caution and provide them with accurate and unbiased instructions to ensure the reliability of their outputs.
As the use of LLMs becomes more prevalent, concerns are growing over their potential negative impact. The dark side of LLMs lies in their ability to amplify biases, spread misinformation, and even generate harmful content. This article explores the potential dangers of large language models, and what can be done to mitigate these risks.
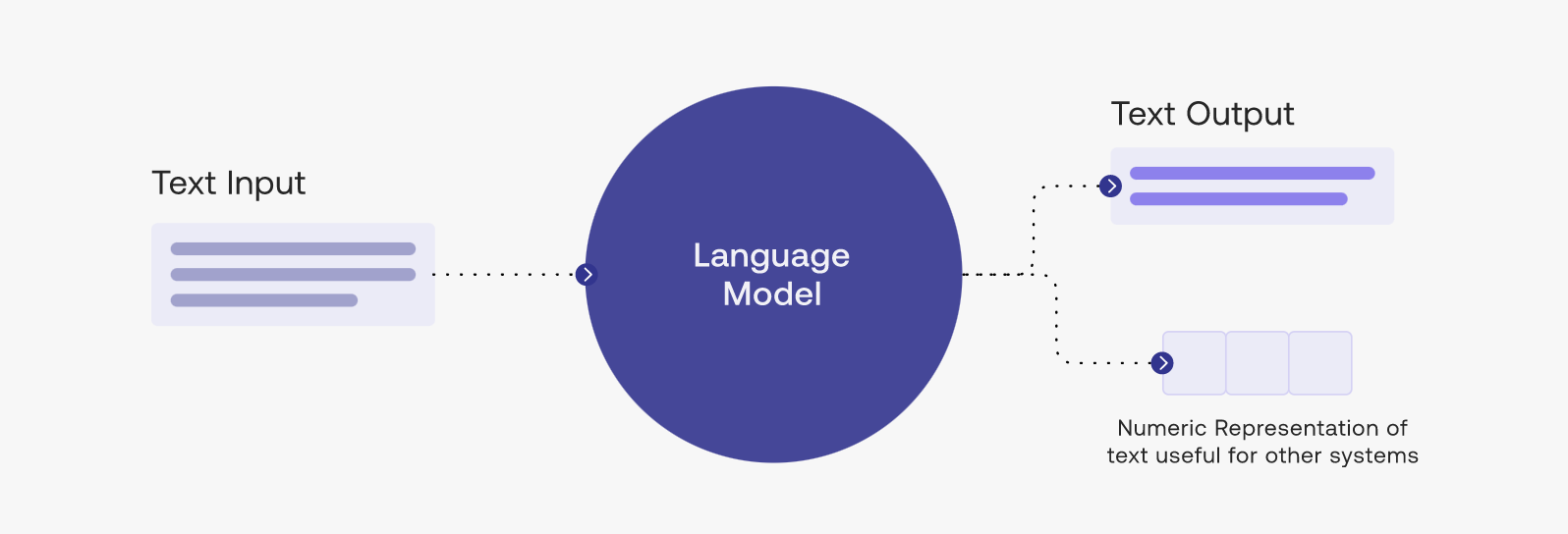
Large language models have the ability to generate text that is virtually indistinguishable from that produced by humans, making them incredibly powerful tools. They can be used for a range of applications, from customer service chatbots to automated news articles. However, their power comes with the potential for abuse.
One of the biggest concerns with large language models is their ability to amplify biases. Large language models are trained on vast amounts of data, which can include biases and stereotypes. When these biases are incorporated into the model, they can be perpetuated in the text generated by the model. For instance, an LLM trained on biased data could generate text that perpetuates racial or gender stereotypes.
Another danger of large language models is their potential to spread misinformation. Large language models are trained on vast amounts of text, much of which is unverified or even intentionally false. When an LLM generates text, it may inadvertently generate false or misleading information. This is particularly concerning when LLM-generated text is used for news articles or social media posts, where false information can quickly spread and have serious consequences.
In addition to amplifying biases and spreading misinformation, large language models have the potential to generate harmful content. This can include hate speech, fake reviews, and even deepfakes. Deepfakes are videos or images generated by large language models that can make it appear as though someone said or did something they never actually did. These types of harmful content can have serious consequences, such as inciting violence or damaging someone's reputation.
While the risks of large language models are significant, there are steps that can be taken to mitigate these risks. One approach is to improve the quality of the data used to train large language models. By ensuring that the data used to train large language models is diverse and free of biases, the resulting text generated by the model will be less likely to perpetuate biases or spread misinformation.
Watermarking can also help mitigate the potential risks of Large Language Models (LLMs). By embedding a unique identifier, or "watermark," into LLM-generated text, it becomes possible to trace the origin of the text back to the specific model and dataset used to generate it. This can be useful in identifying potential biases or harmful content generated by large language models and in holding developers accountable for their models. Watermarking can also be used to protect against copyright infringement or plagiarism, as it provides a way to prove the original source of the text. Overall, watermarking is a promising technique for mitigating the risks of large language models and ensuring greater transparency and accountability in AI-generated text.
Another approach is to develop techniques for detecting and mitigating biased or harmful content generated by large language models. This could include implementing algorithms that flag potentially harmful content or creating human oversight processes to review LLM-generated text.
Transparency is critical when it comes to large language models. Users of LLM-generated text should be made aware of the potential biases and limitations of the model. Additionally, LLM developers should be transparent about the data used to train the model and the techniques used to mitigate potential risks.

Large language models have the potential to revolutionize the way we generate and consume text. Their power comes with significant risks. If left unchecked, large language models can perpetuate biases, spread misinformation, and even generate harmful content. To mitigate these risks, it is essential that we improve the quality of data used to train large language models, develop techniques for detecting and mitigating biased or harmful content, and promote transparency around large language models development and use. By taking these steps, we can unlock the potential of large language models while minimizing their potential negative impact.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest