Comments
- No comments found

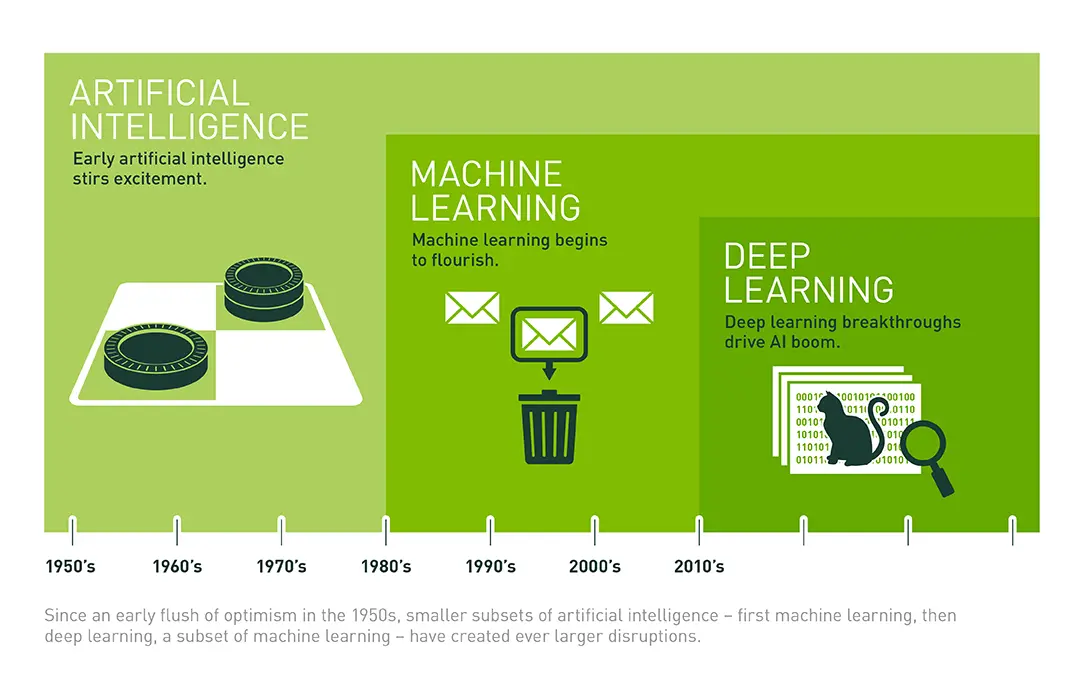
Artificial intelligence (AI) is increasingly affecting the world around us. It is increasingly making an impact in retail, financial services, along with other sectors of the economy.
Applications of machine learning allow for mass personalisation at scale in marketing across different sectors of the economy and improved outcomes for health care by detecting cancer at an earlier stage with medical imaging.
AI has undergone a transformation in the past decade, from being a field in research that at some point had previously stagnated to one where it is expected to become the dominant technology of the next decade (and thereafter too). The journey of how AI arrived at its current state has been both a fascinating and at times a difficult journey. We'll start with a refresher of the definitions of AI.
Source for image above NVIDIA
AI deals with the area of developing computing systems which are capable of performing tasks that humans are very good at, for example recognising objects, recognising and making sense of speech, and decision making in a constrained environment. Classical AI algorithms and approaches included rules-based systems, search algorithms that entailed uninformed search (breadth first, depth first, universal cost search), and informed search such as A and A* algorithms that used a heuristic. A heuristic is used to rank alternatives options based upon the information that is available. Techopedia explains heuristics as methods that "use available data, rather than predefined solutions, to solve machine and human problems. Heuristical solutions are not necessarily provable or accurate but are usually good enough to solve small-scale issues that are part of a larger problem."
The early Classical AI approaches laid a strong foundation for more advanced approaches today that are better suited to large search spaces and big data sets. It also entailed approaches from logic, involving propositional and predicate calculus. Whilst such approaches are suitable for deterministic scenarios, the problems encountered in the real world are often better suited to probabilistic approaches.
There are three types of AI:
Narrow AI: the field of AI where the machine is designed to perform a single task and the machine gets very good at performing that particular task. However, once the machine is trained, it does not generalise to unseen domains. This is the form of AI that we have today, for example Google Translate.
Artificial General Intelligence (AGI): a form of AI that can accomplish any intellectual task that a human being can do. It is more conscious and makes decisions similar to the way humans take decisions. AGI remains an aspiration at this moment in time with various forecasts ranging from 2029 to 2049 or even never in terms of its arrival. It may arrive within the next 20 or so years but it has challenges including those relating to hardware, energy consumption required in today’s powerful machines, and a true ability to multitask as humans do.
Super Intelligence: is a form of intelligence that exceeds the performance of humans in all domains (as defined by Nick Bostrom). This refers to aspects like general wisdom, problem solving and creativity. For more on Super Intelligence and the types of AI see article by Mitchell Tweedie.
Machine Learning is defined as the field of AI that applies statistical methods to enable computer systems to learn from the data towards an end goal. The types of Machine Learning include Supervised, Unsupervised and Semi-Supervised Learning (Reinforcement Learning is dealt with further below).
Artificial Neural Networks are biologically inspired networks that extract abstract features from the data in a hierarchical fashion. Deep Learning refers to the field of Neural Networks with several hidden layers. Such a neural network is often referred to as a deep neural network. Much of the AI revolution during this decade has been related to developments linked to Deep Learning as noted by the Economist article "From not working to neural networking".
AI and Machine learning are based upon foundations from Mathematics and Computer Science (CS). Important techniques used within AI & Machine Learning were invented before CS was created. Key examples include the work of Thomas Bayes, which led Pierre-Simon Laplace to define Bayes’ Theorem (1812). The least squares method for data fitting from Adrien-Marie Legendre in 1805 is another example. Furthermore, Andrey Markov developed methods that went on to be termed Markov Chains (1913). Moreover, the foundations of first-order logic were developed independently by German Mathematician and Philosopher Gottlob Frege in 1879 and American Philosopher and Mathematician Charles Saunders Pierce who published articles on the subject between 1867 and 1906.
For AI or Machine Learning to exist we need the hardware in the form of computers. In 1936 (and 1938 with a correction) Alan Turning, Cambridge Mathematician produced a paper entitled On Computable Numbers, with an Application to the Entscheidungs problem whereby a theoretical machine known as universal computing machine possessed infinite store (memory) with data and instructions. It is termed a Universal Turing Machine today. The 1940s witnessed development of stored program computing with programs held within the same memory utilised for the data. In 1945 the von Neumann architecture (Princeton architecture) was published by John von Neumann in the First Draft of a Report on the EDVAC. It proposed a theoretical design for a stored program computer that serves as the basis for almost all modern computers.
Other Key developments in Computing include:
Contributions to AI and Machine Learning are set out below in a mostly chronological order with some exceptions, for example I placed the more recent Boosting models after the section on the arrival of Boosting approaches, and Evolutionary Genetic Algorithms just above Neuroevolution to allow for a logical connection. The bullet points below provide a non-exhaustive list of contributions until the AI Winters with the later sections covering developments that occurred after the AI Winters:
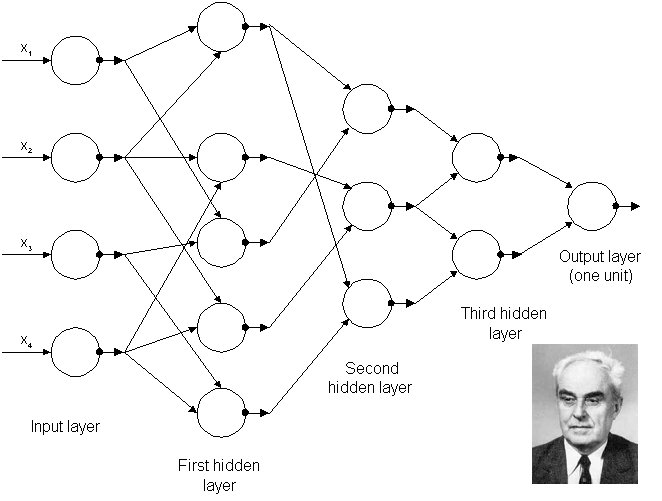
The architecture of the first known deep network which was trained by Ukrainian researcher Alexey Grigorevich Ivakhnenko in 1965. The feature selection steps after every layer lead to an ever-narrowing architecture which terminates when no further improvement can be achieved by the addition of another layer. Image of Prof. Alexey Ivakhnenko courtesy of Wikipedia. Alexey Ivakhnenko is most famous for developing the Group Method of Data Handling (GMDH), a method of inductive statistical learning, for which he is sometimes referred to as the "Father of Deep Learning"
The field of AI faced a rocky road with a period of setbacks in research and development known as the AI Winters. There were two major winters in 1974–1980 and 1987–1993 (smaller episodes followed). The first AI winter occurred as DARPA undertook funding cuts in the early 1970s and Lighthill's report to UK Parliament in 1973 was critical of the lack of AI breakthroughs and resulted in a significant loss of confidence in AI. The second AI winter occurred at time when probabilistic approaches hit barriers as they failed to perform as intended due to issues with acquisition of data and representation. During this time expert systems dominated in the 1980s whilst statistical based approaches were out of favour. Russell & Norvig (2003 page 24) noted that “Overall the AI industry boomed from a few million dollars in 1980 to billions of dollars in 1988. Soon after came a period called the “AI Winter”.
Roger Schank and Marvin Minsky—two leading AI researchers who had survived the "winter" of the 1970s—warned the business community that enthusiasm for AI had spiraled out of control in the 1980s and that disappointment would certainly follow. In 1987, three years after Minsky and Schank's prediction, the market for specialized AI hardware collapsed.
It should be noted that although the AI Winters had an adverse impact upon AI research, there were some advancements in the late 1970s and 1980s, for example:
Neural Networks research had been mostly abandoned by AI and CS around the same time of the AI winters and rise of Symbolic AI. Researchers Hopfield, Rumelhart and Hinton paved the way for the return of Neural Networks with with the reinvention of backpropagation in 1986.
The basics of continuous backpropagation were derived in the context of control theory by Henry J. Kelley in 1960 and by Arthur E. Bryson in 1961 and adopted for Neural Networks, backpropagation fell out of favour until work by Geoff Hinton and others using fast modern processors demonstrated its effectiveness. It is termed back-propagation due to the manner in which the training works whereby the direction is opposite to the flow of data (in a feed-forward network) and entails a recursive process.
Tim Dettmers states that "the modern form was derived first by Linnainmaa in his 1970 masters thesis that included FORTRAN code for backpropagation but did not mention its application to neural networks. Even at this point, backpropagation was relatively unknown and very few documented applications of backpropagation existed until the early 1980s (e.g. Werbos in 1982)."
Rumehlart, Hinton and Williams in Nature in 1986 stated “ We describe a new learning procedure, back-propagation, for networks of neurons-like units. The procedure repeatedly adjusts the weights of the connections in the network so as to minimize a measure of the difference between the actual output vector of the net and the desired output vector. As a result of the weight adjustments, internal ‘hidden’ units which are not part of the input or output come to represent important features of the task domain, and the regularities in the task are captured by the interactions of these units.”
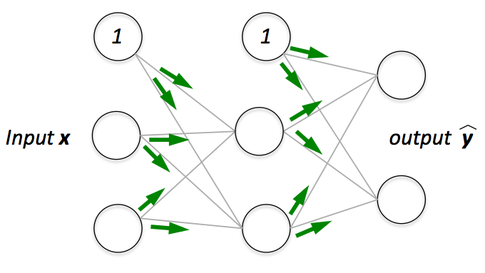
Image Source Sebastian Rashka Forward Propagation
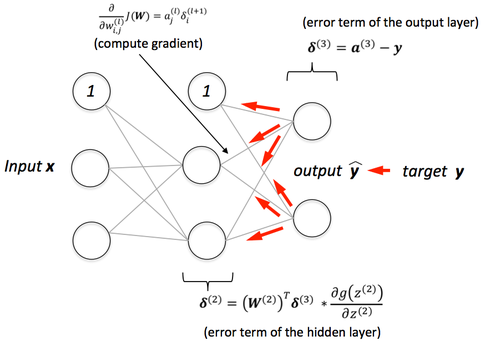
Image Source Sebastian Rashka Back-propagation
Yann LeCun was a postdoctoral research associate in Geofferey Hinton's lab at the University of Toronto from 1987 to 1988. Yann LeCun published a paper on the "A Theoretical Framework for backpropagation". In 1989 Yann LeCun et al. applied back-propagation to recognise the handwritten zip code digits provided by the US Postal service . The technique became a foundation of modern computer vision.
The late 1980s and in particular the 1990s is a period where there was an increased emphasis upon the intersection of CS and Statistics resulting in a shift towards probabilistic, data-driven approaches to AI. Some key examples are set out in the section below.
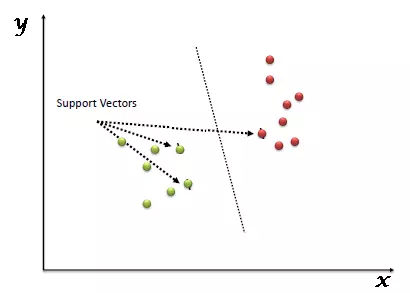
Source for Image Above Analytics Vidhya Understanding Support Vector Machine algorithm
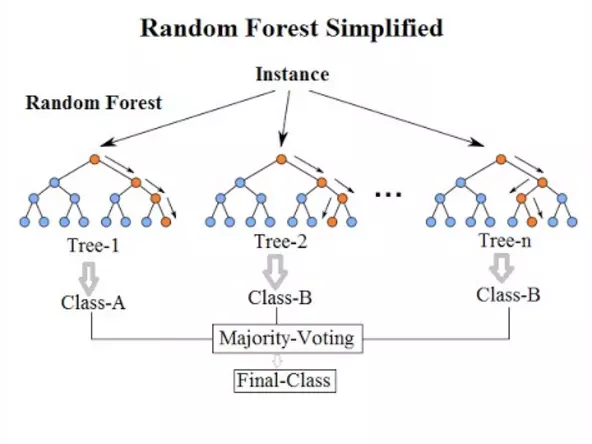
Source for Random Forest Image above Will Koehrsen Random Forest Simple Explanation
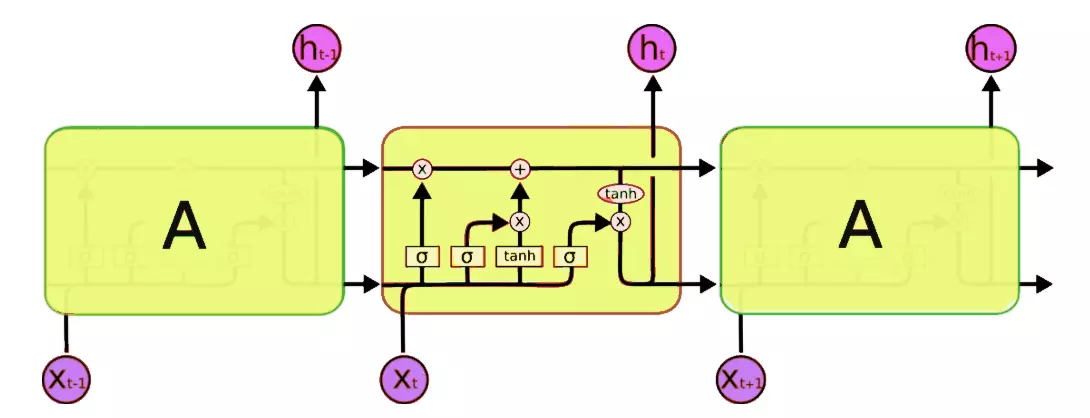
Source for Image Above Analytics Vidyha Introduction to LSTM
Yann LeCunn stated the following:
"CNNs are a special kind of multi-layer neural networks. Like almost every other neural network they are trained with a version of the back-propagation algorithm. Where they differ is in the architecture. "
"CNNs are designed to recognize visual patterns directly from pixel images with minimal preprocessing. "
"They can recognize patterns with extreme variability (such as handwritten characters), and with robustness to distortions and simple geometric transformations. "
"LeNet-5 is our latest convolutional network designed for handwritten and machine-printed character recognition. "
Source for image above BBC
In 2006, Hinton made a breakthrough whereby Deep Learning (Deep Neural Networks) beat other AI algorithms with Kate Allen of the Star noting "In quick succession, Neural Networks, rebranded as “Deep Learning,” began beating traditional AI in every critical task: recognizing speech, characterizing images, generating natural, readable sentences. Google, Facebook, Microsoft and nearly every other technology giant have embarked on a Deep Learning gold rush, competing for the world’s tiny clutch of experts. Deep Learning startups, seeded by hundreds of millions in Venture capital, are mushrooming."
The breakthrough that led to a resurgence of interest in Neural Networks referred to above related to a paper published in 2006 by Hinton et al. A fast learning algorithm for deep belief nets. It is noted by Andrey Kurenkov that "the movement that is ‘Deep Learning’ can very persuasively be said to have started precisely with this paper. But, more important than the name was the idea — that Neural Networks with many layers really could be trained well, if the weights are initialized in a clever way rather than randomly."
Kevin Krewel observed in an NVIDIA Blog that "The CPU (Central Processing Unit) has often been called the brains of the PC. But increasingly, that brain is being enhanced by another part of the PC – the GPU (Graphics Processing Unit)".
The application of GPUs have played an important role in the training and scaling of Deep Learning. For example a blog hosted on the NVIDIA website observed that Insight64 principal analyst Nathan Brookwood described the unique capabilities of the GPU this way: “GPUs are optimized for taking huge batches of data and performing the same operation over and over very quickly, unlike PC microprocessors, which tend to skip all over the place.”
Examples of GPUs playing an important role in enabling Deep Learning techniques such as CNNs to perform faster include:
In 2012 a Stanford Team led by Andrew NG and Jeff Dean connected 16,000 computer processors and used the pool of 10 million images, taken from YouTube videos and demonstrated that an artificial neural network could successfully teach itself to recognize cats.
A key moment in modern AI history also occurred in 2012 with AlexNet that was developed by Alex Krizhevsky and Illya Sutskever along with Geoffrey Hinton (who was Alex Krizhevsky's PhD supervisor). AlexNet is a CNN that uses a GPU during training. AlexNet competed in the ImageNet Challenge in 2012 with the network significantly outperforming its rivals. This was a key moment in Machine Learning history to demonstrate the power of Deep Learning and Graphical Processing Units GPUs in the field of Computer Vision.
As the Economist reported "In 2010 the winning system could correctly label an image 72% of the time (for humans, the average is 95%). In 2012 one team, led by Geoff Hinton at the University of Toronto, achieved a jump in accuracy to 85%, thanks to a novel technique known as “Deep Learning”. This brought further rapid improvements, producing an accuracy of 96% in the ImageNet Challenge in 2015 and surpassing humans for the first time."
As the internet, mobile and social media grew in reach, so too did the creation of digital data and this in turn has fuelled the ongoing development of Machine Learning. The importance of data for Deep Learning is shown in the chart by Andrew NG.
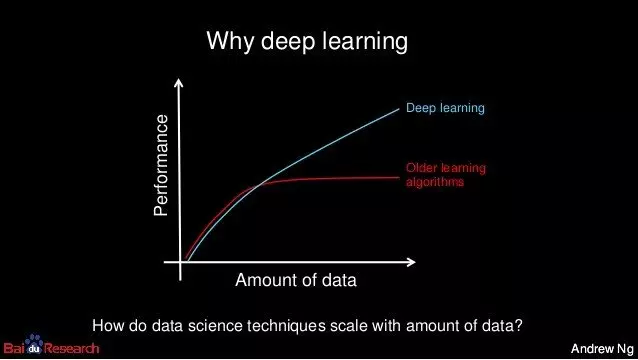
Source for chart above Andrew NG.
According to a report from IBM Marketing Cloud, “10 Key Marketing Trends For 2017,” 90% of the data in the world today has been created in the last two years alone, at 2.5 quintillion bytes of data a day!
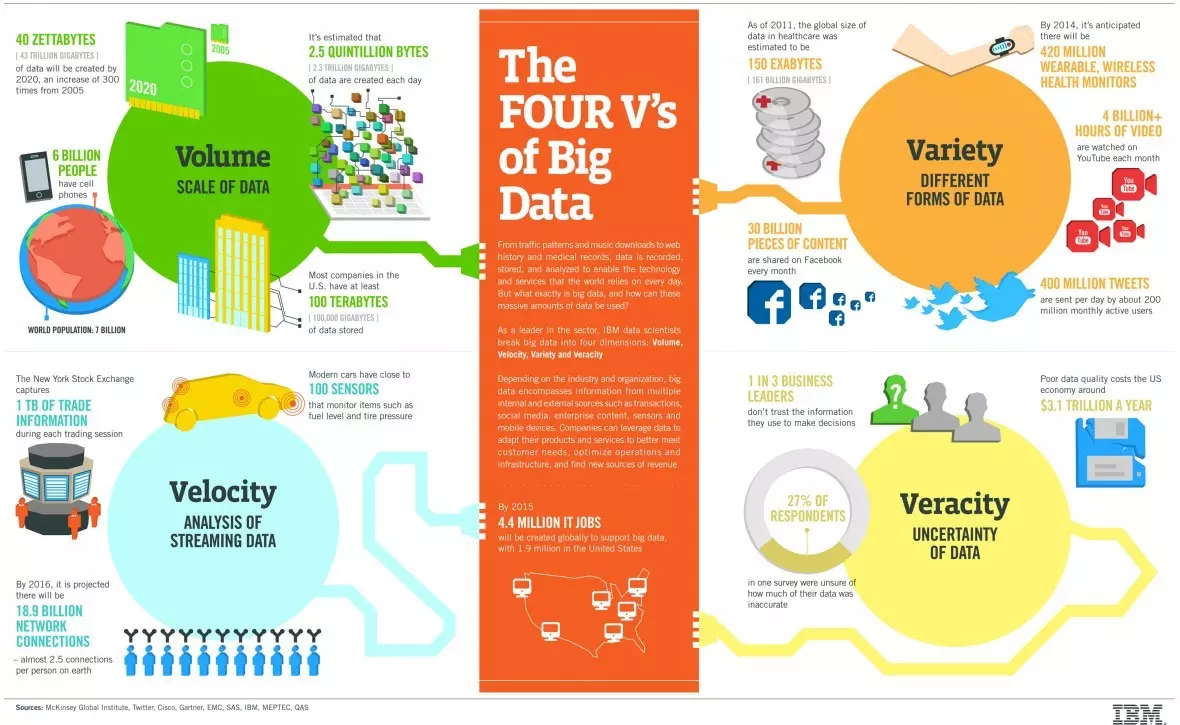
Source for the image above IBM The Four V's of Big Data Graphic
Data has continued to grow and Visual Capitalist shows what happens in a minute on the internet.

Source for Graphic Above Visual Capitalist What Happens In An Internet Minute
It should be no surprise that many of the leading researchers and breakthroughs in Deep Learning now originate from research teams within the tech and social media giants. They also possess an advantage with the volume and variety of data that they can access. Furthermore, the Social Media giants such as Facebook and Twitter have algorithmic influence over what we see and interact with and hence this is leading to debates over ethics and potential regulation of the social media giants that is likely to continue.
Overfitting occurs when a model learns the training data too well. Deep Neural Networks entail stacking many hidden layers. Jeremy Jordan in Deep Neural Networks: preventing overfitting observed "This deep stacking allows us to learn more complex relationships in the data. However, because we're increasing the complexity of the model, we're also more prone to potentially overfitting our data."
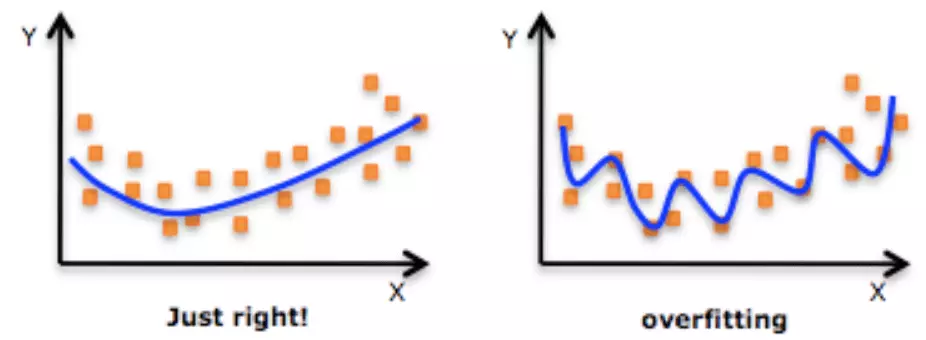
Source for Image Above DataRobot Overfitting
Jason Brownlee Machine Learning Mastery explains that this happens "when a model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data. This means that the noise or random fluctuations in the training data is picked up and learned as concepts by the model. The problem is that these concepts do not apply to new data and negatively impact the models ability to generalize."
Hinton et al. published a paper in 2012 relating to dropout as a means of regularisation of networks to reduce the risk of overfitting. Dropout entails dropping out hidden along with visible units in a Neural Network. A good summary of using dropout is provided by Jason Brownlee A Gentle Introduction to Dropout for Regularizing Deep Neural Networks.
The technique of batch normalization for Deep Neural Networks were developed by Sergey Ioffe and Christian Szegedy of Google to reduce the risk of overfitting and for allowing each layer of a network to learn by itself a little bit more independently of other layers as noted by Firdaouss Doukkali.
GANs are part of the Neural Network family and entail unsupervised learning. They entail two Neural Networks, a Generator and a Discriminator, that compete with one and another in a zero-sum game.
The training involves an iterative approach whereby the Generator seeks to generate samples that may trick the Discriminator to believe that they are genuine, whilst the Discriminator seeks to identify the real samples from the samples that are not genuine. The end result is a Generator that is relatively capable at producing samples relative to the target ones. The method is used to generate visual images such as photos that may appear on the surface to be genuine to the human observer.
In 2014 Ian Goodfellow et al. introduced the name GAN in a paper that popularized the concept and influenced subsequent work. Examples of the achievements of GANs include the generation of faces in 2017 as demonstrated in a paper entitled "This Person Does Not Exist: Neither Will Anything Eventually with AI."
Furthermore GANs made their entrance into the artistic stage with the Creative Adversarial Network (CAN). In 2018 it was reported in the New York Times that art created by a GAN was sold in the article AI Art at Christie’s Sells for $432,500.

“Edmond de Belamy, from La Famille de Belamy,” by the French art collective Obvious, was sold on Thursday at Christie’s New York. Credit Christie's.
The research publication of Andrej Karpathy and Dr Fei-Fei Li from Stanford in 2015 Deep Visual-Semantic Alignments for Generating Image Descriptions featured in the New York Times " Two groups of scientists, working independently, have created Artificial Intelligence software capable of recognizing and describing the content of photographs and videos with far greater accuracy than ever before, sometimes even mimicking human levels of understanding."
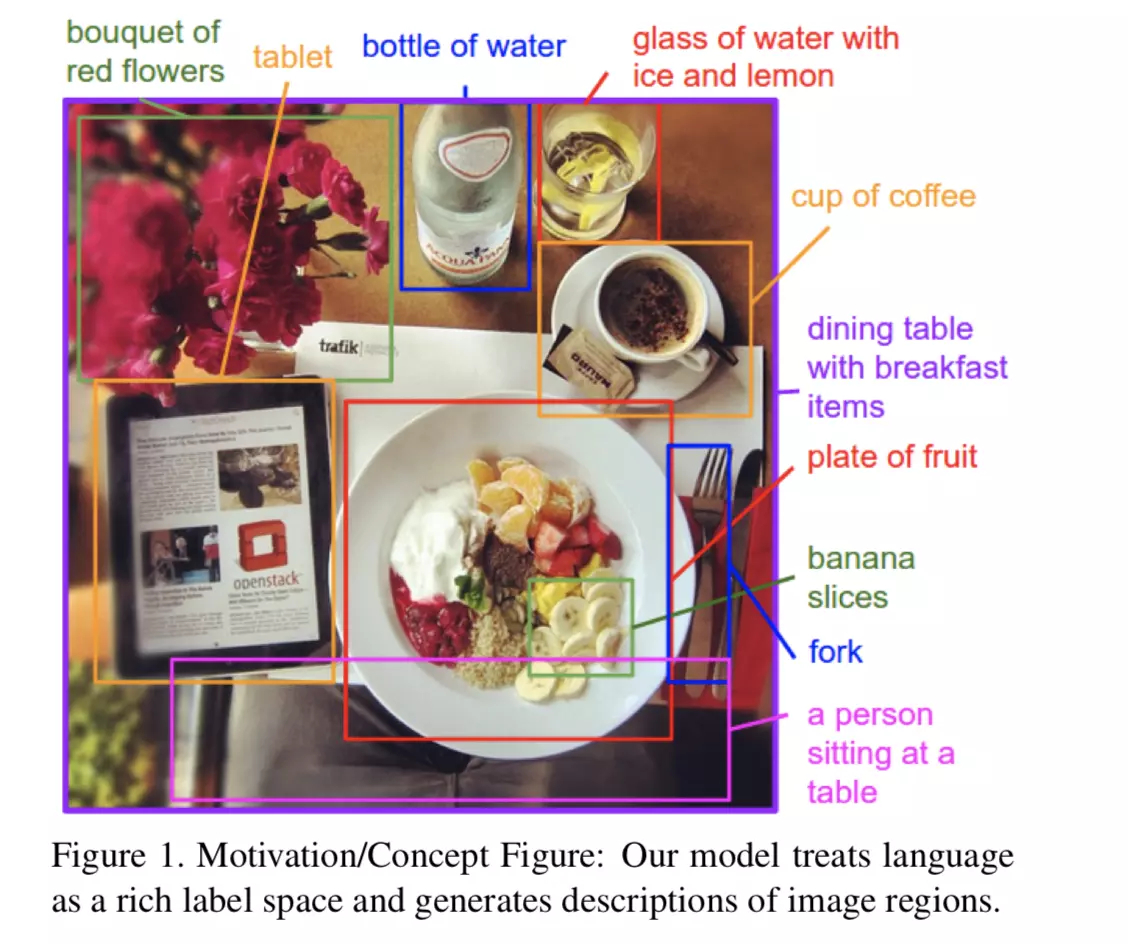
Source For Image Above: Deep Visual-Semantic Alignments for Generating Image Descriptions
In 2015 Yoshua Bengio et al. published "Towards Biologically Plausible Deep Learning" stating "We explore more biologically plausible versions of deep representation learning, focusing here mostly on unsupervised learning but developing a learning mechanism that could account for Supervised, Unsupervised and Reinforcement Learning."
Reinforcement Learning entails Q-Learning and involves an agent taking appropriate actions in order to maximize a reward in a particular situation. It is used by an intelligent agent to solve for the optimal behaviour or path that the agent should take in a specific situation.
Ronald Parr and Stuart Russell of UC Berkeley in 1998 published "Reinforcement Learning with Hierarchies of Machines" and observed that "This allows for the use of prior knowledge to reduce the search space and provides a framework in which knowledge can be transferred across problems and in which component solutions can be recombined to solve larger and more complicated problems."
Robotics expert Pieter Abbeel of UC Berkeley is well known for his work on reinforcement learning. In 2004 Abeel and Andrew NG published Apprenticeship Learning via Inverse Reinforcement Learning. The task of learning from an expert is called apprenticeship learning (also learning by watching, imitation learning, or learning from demonstration)
Francoise-Levet et al. observed that "Deep Reinforcement Learning is the combination of Reinforcement Learning (RL) and Deep Learning. This field of research has been able to solve a wide range of complex decision-making tasks that were previously out of reach for a machine. Thus, Deep RL opens up many new applications in domains such as healthcare, robotics, smart grids, finance, and many more."
The British company DeepMind Technologies was founded in 2010 before being acquired by Google in 2014. DeepMind used Deep Q- Learning with an application of CNNs whereby the layers were tiled to mimic the effects of receptive fields.
They obtained fame when they produced a Neural Network that was able to learn to play video games by analysing the behaviour of pixels on a screen. As Minh et at. 2013 "Playing Atari with Deep Reinforcement Learning" observed "We present the first Deep Learning model to successfully learn control policies directly from high-dimensional sensory input using Reinforcement Learning."
Furthermore DeepMind built a Neural Network with the ability to access external memory – a Neural Turing Machine, Saturo et al. 2016 "One-shot Learning with Memory-Augmented Neural Networks".
Moreover, in 2016 DeepMind's AlphaGo achieved headlines in the BBC news in March 2016 by beating the second ranked player in the World, and then the number one ranked player Ke Jie in 2017. The AlphaGo Neural Network also utilises a Monte Carlo Tree Search Algorithm to discover moves. It was considered an important milestone in AI history as the game of GO was considered a difficult challenge that computers would not defeat humans as quickly as AlphaGo did.

Source for Image above BBC Artificial intelligence: Google's AlphaGo beats Go master Lee Se-dol
In 2017, Google DeepMind published a paper relating to AlphaGo Zero where it was noted that:
"The paper introduces AlphaGo Zero, the latest evolution of AlphaGo, the first computer program to defeat a world champion at the ancient Chinese game of Go. Zero is even more powerful and is arguably the strongest Go player in history."
"It is able to do this by using a novel form of Reinforcement Learning, in which AlphaGo Zero becomes its own teacher. The system starts off with a neural network that knows nothing about the game of Go. It then plays games against itself, by combining this neural network with a powerful search algorithm. As it plays, the neural network is tuned and updated to predict moves, as well as the eventual winner of the games."
"After just three days of self-play training, AlphaGo Zero emphatically defeated the previously published version of AlphaGo - which had itself defeated 18-time world champion Lee Sedol - by 100 games to 0. After 40 days of self training, AlphaGo Zero became even stronger, outperforming the version of AlphaGo known as “Master”, which has defeated the world's best players and world number one Ke Jie."
Deep Reinforcement Learning is an exciting field of cutting edge AI research with potential applications in areas such as autonomous cars, for example in 2018 Alex Kendall demonstrated the first application of Deep Reinforcement Learning to autonomous driving in a paper entitled "Learning to Drive in A Day."

In 2019 Alex Lee observed that DeepMind has finally thrashed humans at StarCraft for real. For more detail see: AlphaStar: Mastering the Real-Time Strategy Game StarCraft II.
In 2020 Jason Dorrier noted in an article entitled "DeepMind’s Newest AI Programs Itself to Make All the Right Decisions" stating that "In a paper recently published on the pre-print server arXiv, a database for research papers that haven’t been peer reviewed yet, the DeepMind team described a new deep reinforcement learning algorithm that was able to discover its own value function—a critical programming rule in deep reinforcement learning—from scratch."
John Holland published a book on Genetic Algorithms (GAs) in 1975 and taken further by David E Goldberg in 1989 .
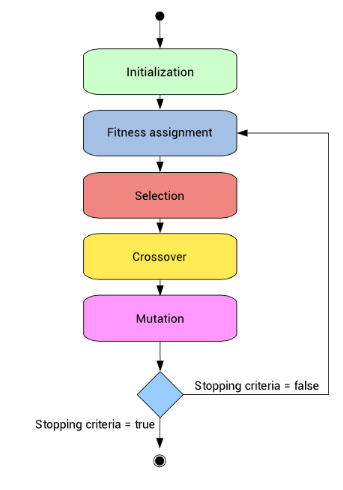
Image Source for GA above AnalyticsVidya
GAs are a variant of local beam search whereby a successor state is generated by combining two parent states. A state is represented as a binary string and the population is a number of states that are randomly generated. The quality of a particular state is assessed via a fitness function and the next generation of states are produced with the higher quality states having larger values. A process known as Crossover entails selecting pairs using a Roulette Wheel or a Tournament. The crossover point is randomly selected and the resulting chromosomes represent new states. However, Crossover might not be enough if the population does not contain examples that have each bit of the chromosome at both possible values parts of the search space are inaccessible. Hence mutation is used that entails a low probability of flipping a random bit at each cross-over step. The process is repeated from “selection” until the desired fitness levels are attained. For more details on GAs see Analytics Vidhya Introduction to Genetic Algorithm & their application in Data Science.
The field of Neuroevolution is an area of research where Neural Networks are optimized through evolutionary algorithms. Kenneth O'Stanely describes the field as follows"Put simply, Neuroevolution is a subfield within AI and Machine Learning that consists of trying to trigger an evolutionary process similar to the one that produced our brains, except inside a computer. In other words, Neuroevolution seeks to develop the means of evolving Neural Networks through evolutionary algorithms."
Uber Labs proposed Genetic algorithms as a competitive alternative for training Deep Neural Networks stating "Using a new technique we invented to efficiently evolve DNNs, we were surprised to discover that an extremely simple Genetic Algorithm (GA) can train Deep Convolutional Networks with over 4 million parameters to play Atari games from pixels, and on many games outperforms modern deep reinforcement learning (RL) algorithms (e.g. DQN and A3C) or evolution strategies (ES), while also being faster due to better parallelization. "
For more on Neuroevolution see O' Stanley et al. who provide an overview in a paper entitled "Designing neural networks through Neuroevolution"
Transformers with Self-Attention mechanisms have been revolutionising the fields of NLP and text data since their introduction in 2017.
The most high profile and advanced Transformer based model GPT-3 (see below) has attained a great deal of attention in the press recently including authoring an article that was published in the Guardian.
Attention first appeared in the NLP domain in 2014 with Cho et al. and Sutskever et al.with both groups of researchers separately arguing in favour of the use of two recurrent neural networks (RNN), that were termed an encoder and decoder.
For a more detailed look at the history of the development of Attention and Transformers in this domain see the article by Buomsoo Kim "Attention in Neural Networks - 1. Introduction to attention mechanism."
A selection of key papers to note are show below:
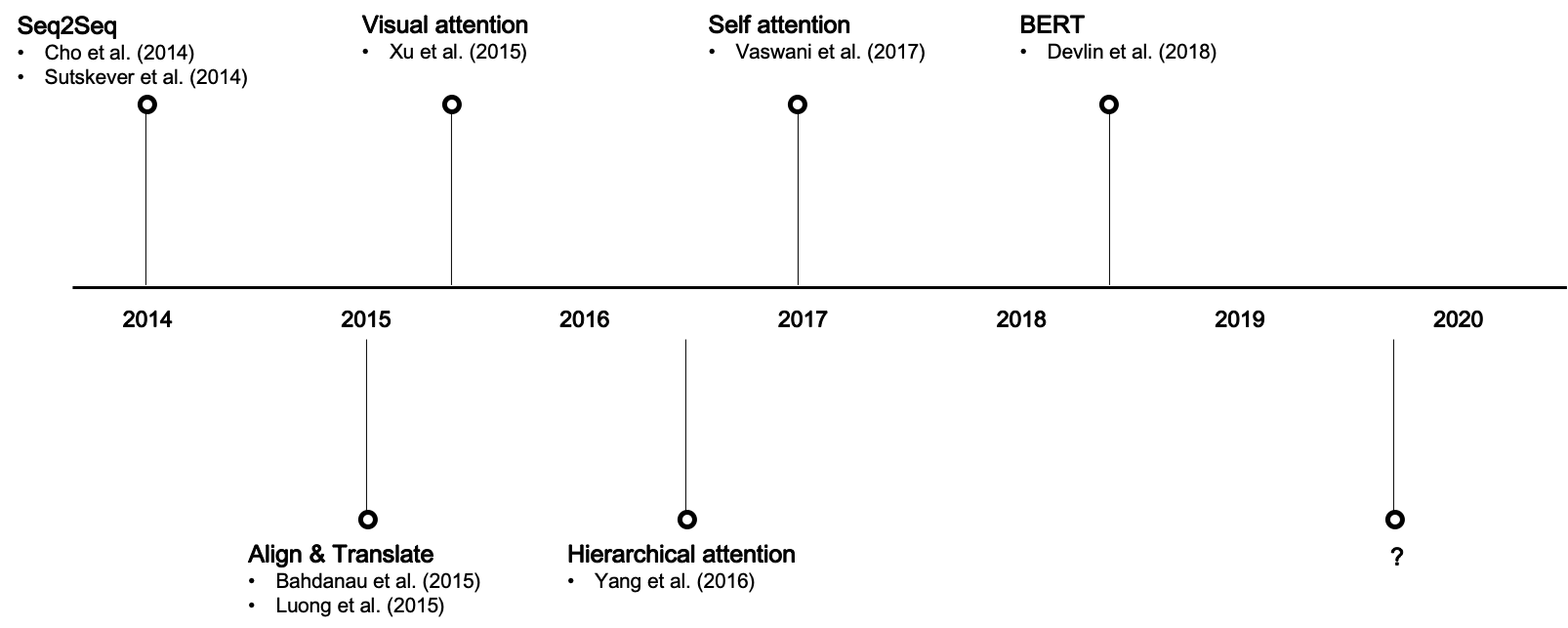
Source for image above Bum Soo Kim "Attention in Neural Networks - 1. Introduction to attention mechanism."
Some notable Transformer models to be aware of (non-exhaustive list):
Bidirectional Encoder Representations from Transformers (BERT) Google 2018
GPT-2 February 14, 2019 Open AI
DeepSpeed Microsoft AI & Research
GPT-3 May / June 2020 Open AI
For a more detailed overview of Transformers see Transformers on the rise in AI! The Rise of the Transformers: Explaining the Tech Underlying GPT-3.
In recent years we've also noted increasing research in the field of Neuro Symbolic AI that combines Symbolic (or Logical AI) with Deep Neural Networks. An example from 2019 would be The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision
NeuroSymbolic AI: is defined by MIT-IBMWatsonAILab as a fusion of AI methods that combine neural networks, which extract statistical structures from raw data files – context about image and sound files, for example – with symbolic representations of problems and logic. "By fusing these two approaches, we’re building a new class of AI that will be far more powerful than the sum of its parts. These neuro-symbolic hybrid systems require less training data and track the steps required to make inferences and draw conclusions. They also have an easier time transferring knowledge across domains. We believe these systems will usher in a new era of AI where machines can learn more like the way humans do, by connecting words with images and mastering abstract concepts."
A key paper in the history of Federated Learning was presented by Google in 2016 and entitled " Communication-Efficient Learning of Deep Networks from Decentralized Data"
The paper noted that "Modern mobile devices have access to a wealth of data suitable for learning models, which in turn can greatly improve the user experience on the device. For example, language models can improve speech recognition and text entry, and image models can automatically select good photos. However, this rich data is often privacy sensitive, large in quantity, or both, which may preclude logging to the data center and training there using conventional approaches. We advocate an alternative that leaves the training data distributed on the mobile devices, and learns a shared model by aggregating locally-computed updates. We term this decentralized approach Federated Learning. "
Federated Learning: also known as collaborative learning is a technique in Machine Learning that enables an algorithm to be trained across many decentralised servers (or devices) that possess data locally without exchanging them. Differential Privacy aims to enhance data privacy protection by measuring the privacy loss in the communication among the elements of Federated Learning. The technique may deal with the key challenges of data privacy and security relating to heterogeneous data and impact sectors such as the Internet of Things (IoT), healthcare, banking, insurance and other areas with data privacy and collaborative learning are of key importance and may well become a key technique in the era of 5G and Edge Computing as the AIIoT scales.
Machine Learning has continued to grow in use cases and across sectors. The development of open source libraries such as TensorFlow in 2015 and the decision in 2017 to support Keras (authored by François Chollet) in TensorFlow's core library has helped drive the continued deployment of Deep Learning across sectors.
In 2017 it was reported that Facebook brought Pytorch open source library, based upon Torch framework to users.
Although significant challenges remain in relation to achieving AGI, Google DeepMind published a paper entitled PathNet: Evolution Channels Gradient Descent in Super Neural Networks in 2017 that showed a potential path way to AGI.

Source for image above: PathNet: Evolution Channels Gradient Descent in Super Neural Networks
In 2017 Hinton et al. published a paper “Matrix Capsules with EM Routing” proposing capsules. It remains an area of research and an article by Aurélien Géronprovides a good overview of Capsules, noting that an advantage that they have is that "CapsNets can generalize well using much less training data."
Adam Conner-Simons reported that in 2019 researchers at MIT were working on Smarter training of neural networks and observed that the “MIT CSAIL project shows the neural nets we typically train contain smaller “subnetworks” that can learn just as well, and often faster”.
In March 2019, The Verge reported that Yoshua Bengio, Geoffrey Hinton, and Yann LeCun, the ‘Godfathers of AI’ were honored with the Turing Award, the Nobel Prize of computing for laying the foundations for modern AI with Deep Learning.
I believe that the journey of AI will continue onto the edge (on device), further facilitated with the roll out of 5G networks around the world as we move to a world of Intelligent Internet of Things with sensors and devices communicating with each other and with humans.
Furthermore, leading AI practitioners and researchers believe that further understanding of our now brain will be key for the continued development of AI. Dr Anna Becker, CEO of Endotech.io and PhD in AI, explained that "understanding the human brain in more detail will be the key to the next generation of AI during the 2020s". This view is echoed in an interview with AI researcher Sejnowski published in TechRepublic "If we want to develop machines with the same cognitive abilities as humans — to think, reason and understand — then Sejnowski says we need to look at how intelligence emerged in the brain."
We've been experiencing AI entering our everyday world over the past decade and this trend is set to continue to accelerate as we move into the era of 5G and Edge Computing.
Furthermore, in 2017 CNBC reported that Billionaire Mark Cuban said that "the world’s first trillionaire will be an AI entrepreneur." Mark Cuban further stated “Whatever you are studying right now if you are not getting up to speed on Deep Learning, Neural Networks, etc., you lose.” The article added that Google had added $9Bn to its revenues due to AI.
In relation to the finance sector, Jim Marous stated in an article posted in 2018 in the Financial Brand (@JimMarous) that "AI is poised to massively disrupt traditional financial services... Ongoing developments in AI have the potential to significantly change the way back offices operate and the experiences consumers receive from financial institutions."
Blake Morgan (@BlakeMichelleM) in 2019 provided 20 Examples Of Machine Learning Used In Customer Experience with examples including "Guests at Disney parks use MagicBand wristbands as room keys, tickets and payment. The wristband collects information of where the guests are in the park to recommend experiences and even route people around busy areas."
Blake Morgan also observed that "JP Morgan streamlines correspondence with machine learning that analyzes documents and extracts important information. Instead of taking hours to sort through complicated documents, customers can now have information in seconds."
In May 2019 the BBC reported that researchers at Northwestern University in Illinois and Google conducted studies with Deep Learning for the screening of lung cancer and found that their approach was more effective than the radiologists when examining a single CT scan and was equally effective when doctors had multiple scans to go on. The results published in Nature showed the AI could boost cancer detection by 5% while also cutting false-positives (people falsely diagnosed with cancer) by 11%.
Increasingly AI will also be about successful deployment and scaling across the sectors of the economy such as finance and health care. Spiros Magaris (@SpirosMargaris) observed in a discussion with Brett King and myself that those financial institutions that adopt AI and use it to successfully solve customer experience are the ones that will thrive in the next decade.
As Brett King's book Augmented (@BrettKing) notes "Ongoing developments in AI have the potential to significantly change the way back offices operate and the experiences consumers receive from financial institutions...This new era will be based on four themes: AI, experience design, smart infrastructure, and health care technology."
The impact of the Covid-19 crisis that the world has been experiencing in 2020 is that it is likely to accelerate the adoption of AI and Digital Transformation. This was noted by the EU Commission who observed that "The pandemic boosted AI adoption "The researchers noted an increased adoption and use of AI in scientific and medical research, in particular in applications such as telemedicine, medical diagnosis, epidemiological studies, and clinical management of patients.
"Similarly, the crisis made it possible to overcome barriers in the sharing of data between commercial entities, and between business and governments."
"The pandemic gave a boost to the digital transition of companies, public administrations and schools. Plans that had maybe dragged on for years, had to be implemented at very short notice, overcoming many technological, organisational, skill gaps, and cultural barriers."
McKinsey expressed similar views in an article entitled "Digital strategy in a time of crisis" stating that "In one European survey, about 70 percent of executives from Austria, Germany, and Switzerland said the pandemic is likely to accelerate the pace of their digital transformation." In addition McKinsey also noted "Companies that have already invested in AI capabilities will find themselves significantly advantaged."
The next stages of the AI journey will be research breakthroughs in enabling Deep Learning techniques to train with smaller data sets, advancements in Deep Reinforcement learning, Neuroevolution and NeuroSymbolic AI, and continued development of Transformer models including the type of research that Facebook proposed in 2020 with Detection Transformer (DETR) model that combines CNNs with Transformers into an model architecture that can recognize objects in an image in a single pass all at once, see End-to-end object detection with Transformers.
The significantly faster speed and reduced latency that 5G will enable along with substantially increased capacity to connect devices and hence enable machine to machine communication on the edge as well as emerging new technologies (AR, VR) working alongside AI techniques such Deep Learning that will in turn lead to new opportunities across the economy. In addition I expect more diversity in AI development in the future including both racial diversity and also more women in cutting edge AI research in addition to Dr Fei Fe Li and Regina Barzilay and as noted by Mariya Yao.
Imtiaz Adam is a Hybrid Strategist and Data Scientist. He is focussed on the latest developments in artificial intelligence and machine learning techniques with a particular focus on deep learning. Imtiaz holds an MSc in Computer Science with research in AI (Distinction) University of London, MBA (Distinction), Sloan in Strategy Fellow London Business School, MSc Finance with Quantitative Econometric Modelling (Distinction) at Cass Business School. He is the Founder of Deep Learn Strategies Limited, and served as Director & Global Head of a business he founded at Morgan Stanley in Climate Finance & ESG Strategic Advisory. He has a strong expertise in enterprise sales & marketing, data science, and corporate & business strategist.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest