Comments
- No comments found

Machine learning (ML), a subset of artificial intelligence (AI), has revolutionized the world but it has some fundamental flaws.
The rapid development of technology, processor power and computer parallelization, has now made it possible to obtain and study large amounts of data with relative ease.
Although, there are some variations of how to define the types of machine learning algorithms but commonly they can be divided into categories according to their purpose. The main machine learning categories are as follow:
Here is the list of supervised learning algorithms in machine learning:
There are many different models in machine learning. Here are some of the most commonly used algorithms in the world today:
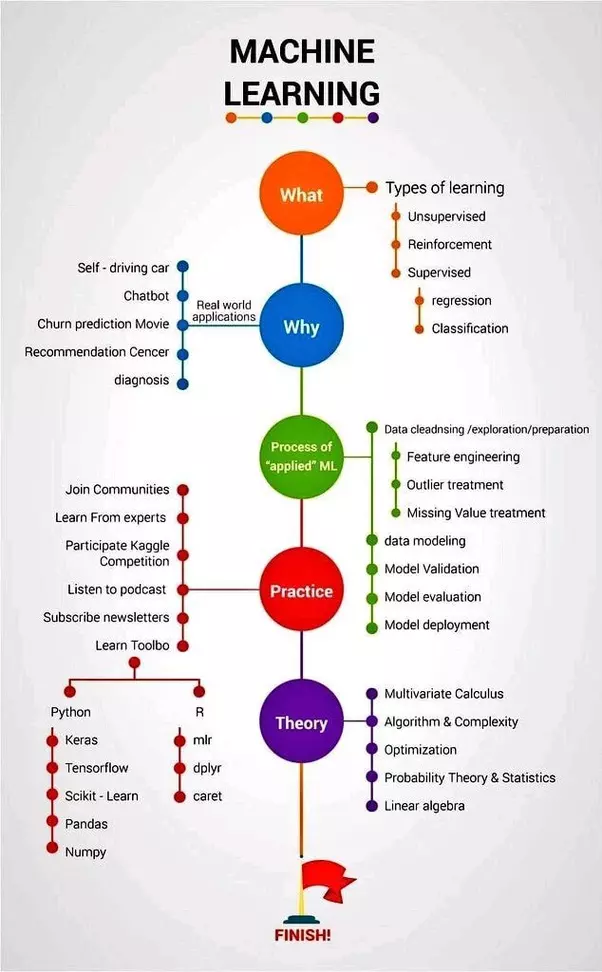
Despite its numerous advantages, machine learning isn’t perfect. Here are 8 issues that are harming the progress of machine learning and what's fundamentally wrong:
Machine Learning requires massive data sets to train on, and these should be inclusive/unbiased, and of good quality. There can also be times where they must wait for new data to be generated.
Machine learning requires enough time to let the algorithms learn and develop enough to fulfill their purpose with a considerable amount of accuracy and relevancy. It also needs massive resources to function. This can mean additional requirements of computer power for you.
Another major challenge is the ability to accurately interpret results generated by the algorithms. You must also carefully choose the algorithms for your purpose.
Machine Learning is autonomous but highly susceptible to errors. Suppose you train an algorithm with data sets small enough to not be inclusive. You end up with biased predictions coming from a biased training set. This leads to irrelevant advertisements being displayed to customers. In the case of machine learning, such blunders can set off a chain of errors that can go undetected for long periods of time. And when they do get noticed, it takes quite some time to recognize the source of the issue, and even longer to correct it.
The idea of trusting data and algorithms more than our own judgment has its pros and cons. Obviously, we benefit from these algorithms, otherwise, we wouldn’t be using them in the first place. These algorithms allow us to automate processes by making informed judgments using available data. Sometimes, however, this means replacing someone’s job with an algorithm, which comes with ethical ramifications. Additionally, who do we blame if something goes wrong?
Machine learning is still a relatively new technology. From the start code to the maintenance and monitoring of the process, machine learning experts are required to maintain the process. Artificial Intelligence and machine learning industries are still freshers to the market. Finding enough resources in the form of manpower is also difficult. Hence, there is a lack of talented representatives available to develop and manage scientific substances for machine learning. Data researchers regularly need a mix of space insight just as top to bottom knowledge of mathematics, technology, and science.
Machine learning requires a tremendous amount of data stirring abilities. Inheritance frameworks can’t deal with the responsibility and clasp under tension. You should check if your infrastructure can deal with issues in Machine Learning. If it can’t, you should hope to upgrade it completely with good hardware and adaptable storage.
Machine learning is time-consuming. Due to an overload of data and requirements, it takes longer than expected to provide results. Focusing on particular features within the database in order to generalize the outcomes is very common in machine learning models, which lead to bias.
Machine Learning has taken over many aspects of our life. Although it's not perfect, machine learning is a continuously evolving field with high demand. Without human intervention, it delivers real-time results using the already existing and processed data. It generally helps analyze and assess large amounts of data with ease by developing data-driven models. Although there are many issues in machine learning, it's an evolving field. From medical diagnosis, vaccine development to advanced trading algorithms, machine learning has become vital to scientific progress.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest