Comments
- No comments found

Deep learning is gaining prominence in the field of artificial intelligence, streamlining processes, and bringing huge financial gains to businesses.
However, businesses must be aware of deep learning challenges before they employ deep learning to solve their problems.
Deep learning is everywhere. From your Google voice assistant to your ‘Netflix and chill’ recommendations to the very humble Grammarly -- they're all powered by deep learning. Deep learning has become one of the primary research areas in artificial intelligence. Most of the well-known applications of artificial intelligence, such as image processing, speech recognition and translations, and object identification are carried out by deep learning. Thus, deep learning has the potential to solve most business problems, streamlining your work procedures, or creating useful products for end customers. However, there are certain deep learning challenges that you should be aware of, before going ahead with business decisions involving deep learning.
Here are 5 deep learning challenges to watch out for:
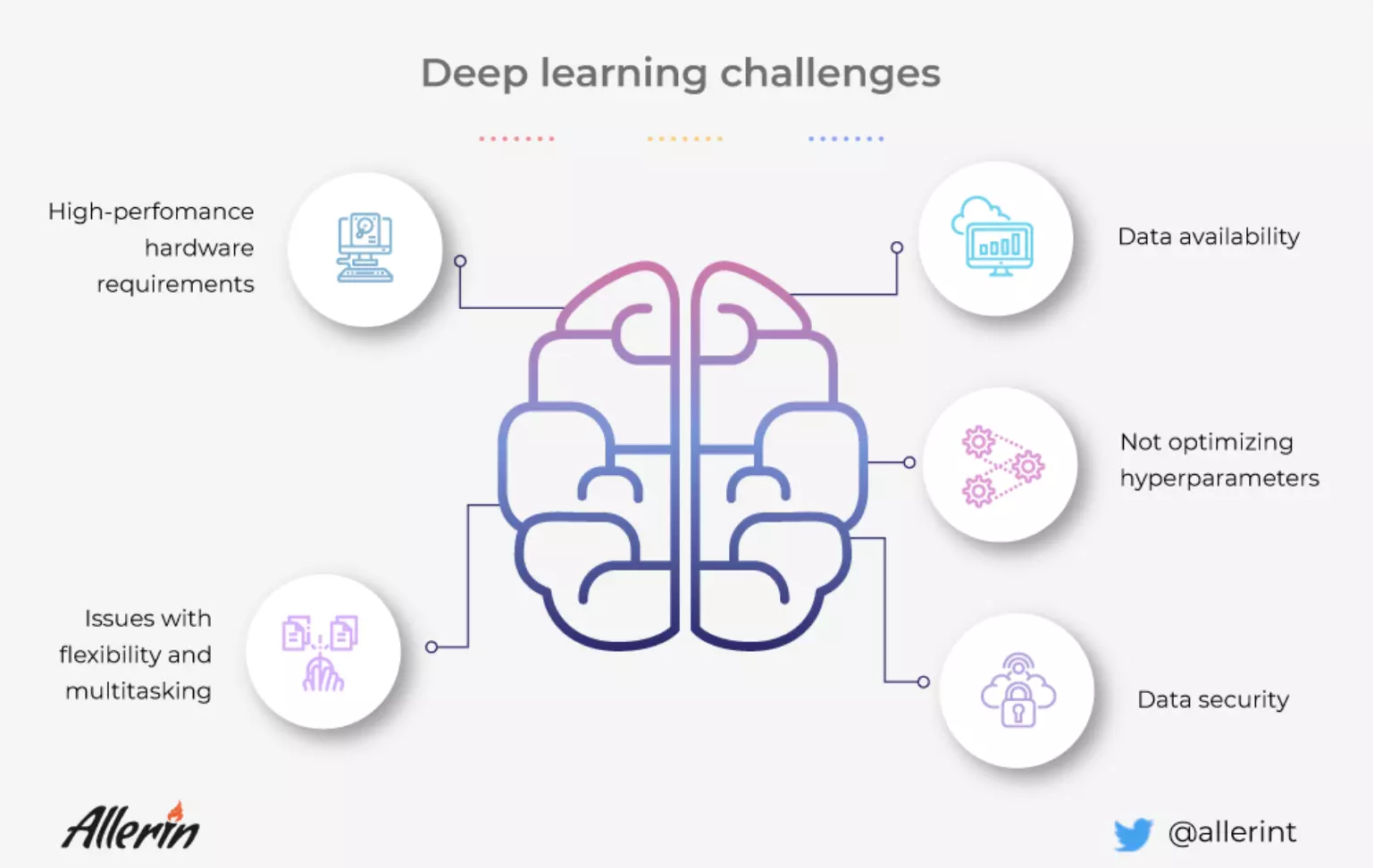
Deep learning, although useful in creating solutions has certain limitations that can affect the output of the deep learning model and not provide the intended results. Some of the challenges businesses may encounter are:
Deep learning models require tons of data to train. Additionally, the quality of the data, too, matters along with the quantity. A deep learning model with insufficient or low-quality data will not perform efficiently. The output may be vastly different than what it was intended to produce. Errors in the output of a deep learning model with low quantity and bad-quality data are common. The time required for the neural network to train itself, too, will be high in such instances. Thus, your business will end up exhausting time, money, and resources without any fruitful results, leading to disappointments.
You must, therefore, ensure that the deep learning model you wish to train and use has sufficient and appropriate data before proceeding with the solution. Generally, data is easily available for commercial applications like a smartphone app that needs to be rolled out for millions of users. But data is hard to come-by for industrial applications. Thus, if your business is looking to develop industry-specific solutions based on deep learning models, you must ensure that you have a sufficient quantity of data available with you. For example, a speech translation program will require data from multiple demographics, dialects, and age groups. Terabytes of data are required to train the deep learning model to learn and understand a single language. To train it to translate to another language is another task altogether, requiring even more time and datasets. Gathering data for such systems may be difficult in the beginning, but can become progressively easy when multiple users provide data in the form of feedback. Similarly, a solution developed to monitor and automate manufacturing data using a deep learning model requires large datasets specific to the manufacturing sector for the solution to be successful. Such data is hard to come by as it is highly use-case oriented.
Machine learning systems are employed for training neural networks in a deep learning model. In a business context, providing training datasets to such models and systems requires sensitive and real-world business information to be fed to the system. Therefore, if you’re implementing deep learning models, you must ensure that the data used in training is not compromised at any cost. Hackers can plan adversarial attacks on the neural networks that can affect the output of the deep learning program. This can fool the deep-learning models and can significantly change the output desired from the model. Such adversarial attacks can even get hackers to access sensitive information regarding your business operations and can be used wrongfully for monetary gains or for tarnishing the reputation of the organization.
For example, a deep learning model for classifying images into different classes relies on images for training. Hackers can add random noise to certain images in the training dataset that can alter the analysis and training process of the deep learning model. It will eventually result in the program being inefficient.
Hackers can add random noise to a deep learning model that classifies animals into horses or zebras. The additional malicious information may result in the deep learning model to identify horses as zebras and vice versa. Thus, the deep learning model is of no use and needs to be fed again with new datasets and retrained. This leads to the wastage of time and resources and delays the deployment of the product. Other adversarial attacks may result in sensitive information being accessed by hackers which can compromise the integrity of the organization.
As mentioned above, training deep learning models requires a lot of data. To perform operations with such large datasets, the machine needs hardware with high processing power. Low-end hardware can result in the model taking a long time to train. This eventually results in the solution being ready and deployed later than originally intended. Data scientists usually switch to CPUs and GPUs with high-processing power to speed up the process of training the deep learning model. However, the processing units are costly and consume high power. Industry-level solutions require high-end data centers while low-end consumer devices such as mobile phones and drones require small but efficient processing units. Thus, training deep learning models is a costly and power-consuming affair. However, methods like transfer learning and generative adversarial networks can be used to overcome this challenge to some extent.
Although deep learning is at the forefront of the artificial intelligence domain, it lacks flexibility and multitasking. Deep learning models can provide an efficient solution for a specific problem, but they are inefficient at carrying out multiple tasks. Even training the deep learning model to carry out a similar task requires retraining and reprogramming the model. Progressive Neural Networks and Multi-Task Learning are proving helpful in creating deep learning models that are flexible and can multitask. However, progress still needs to be made in this domain to find an efficient solution. Google DeepMind’s research scientist Raia Hadsell has perfectly summed up the inability of deep learning models to multitask, “There is no neural network in the world, and no method right now that can be trained to identify objects and images, play Space Invaders, and listen to music.” Things are however looking bright with ongoing research in this field.
Hyperparameters are the variables that determine the network structure and the variables that determine how the network is trained. They are set before optimizing the weights and bias. Changing the hyperparameters even by a small amount can affect the output of the program. It can lead to the butterfly effect, wherein a small change in the hyperparameters can spiral into the output of the deep learning model being completely changed. However, relying on the default parameters and not optimizing hyperparameters, too, is not a good practice. Also, there is the issue of overfitting data, especially when the number of parameters is more than the number of independent observations.
Deep learning may be one of the leading areas of artificial intelligence, but it surely is not flawless. While exploring new methods of research and adoption of the technology, coming across challenges and hurdles is bound to happen. However, with a clear thought process, these challenges can be mitigated to make the most use of the technology in its current form. You can foremost ensure that you have sufficient and relevant data for the deep learning algorithm you are trying to build. You must then ensure that the data is secure and adopt measures to prevent the data from being misused. Or you can simply partner with an experienced deep learning solutions provider that can ensure all these challenges are taken care of and you can focus solely on your product.
Naveen is the Founder and CEO of Allerin, a software solutions provider that delivers innovative and agile solutions that enable to automate, inspire and impress. He is a seasoned professional with more than 20 years of experience, with extensive experience in customizing open source products for cost optimizations of large scale IT deployment. He is currently working on Internet of Things solutions with Big Data Analytics. Naveen completed his programming qualifications in various Indian institutes.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest