Comments
- No comments found

The advent of artificial intelligence (AI) has revolutionized the way we approach complex problems in fields ranging from healthcare to finance.
One of the biggest challenges in developing AI models is the need for large amounts of data to train them. As the amount of available data increases exponentially, it is reasonable to wonder what would happen if we were to run out of data. In this article, we will explore the consequences of a data shortage for AI models, as well as possible solutions to mitigate the effects.
AI models are trained by feeding them large amounts of data. They learn from this data by finding patterns and relationships that allow them to make predictions or classify new data. Without enough data to train on, an AI model would not be able to learn these patterns and relationships, which would lead to a decrease in its accuracy.
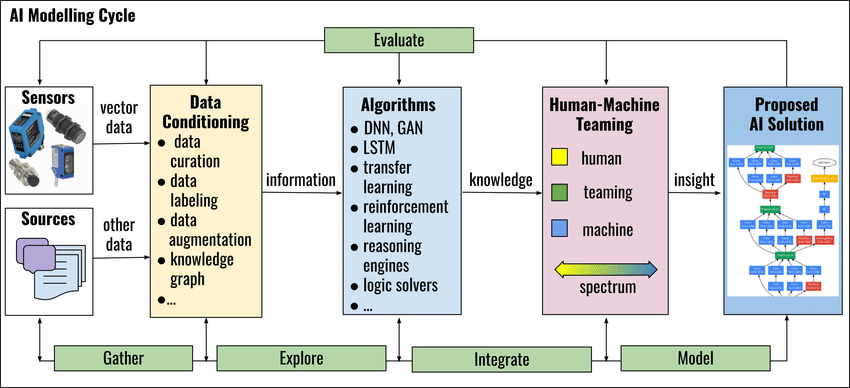
In some cases, the lack of data may also prevent an AI model from being developed in the first place. For example, in medical research, there may be limited data available on rare diseases or conditions, making it difficult to train an AI model to accurately diagnose them.
Furthermore, a lack of data could make AI models vulnerable to attacks. Adversarial attacks involve intentionally introducing subtle changes to the input data in order to fool an AI model into making incorrect predictions. If an AI model has only been trained on a limited amount of data, it may be more susceptible to these attacks.
The consequences of a data shortage for AI models would depend on the specific application and the amount of data that is available.
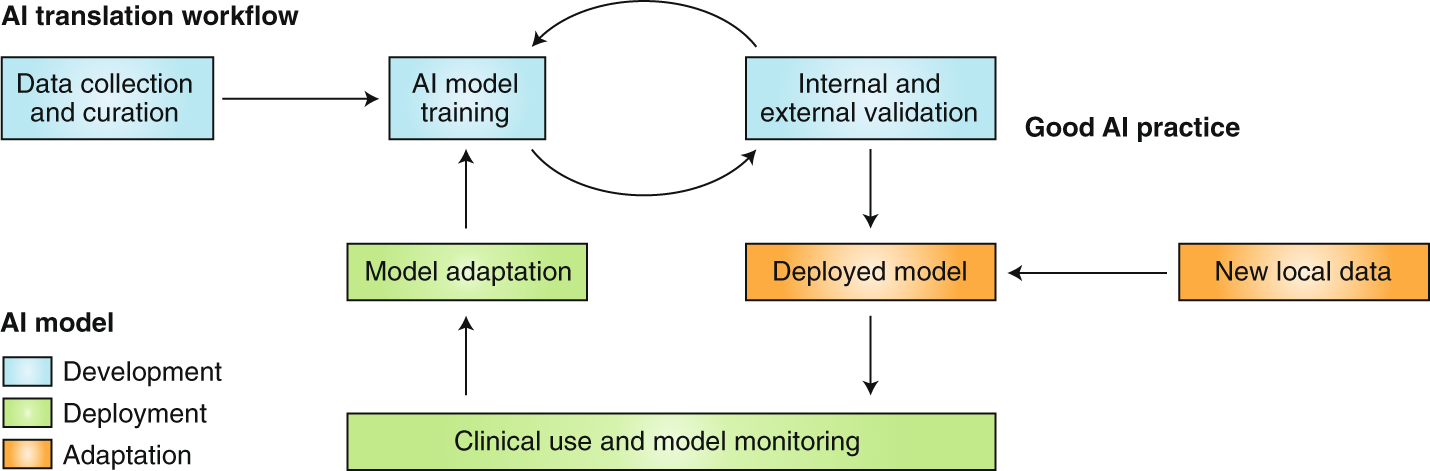
Here are some possible scenarios:
Decreased Accuracy: If an AI model has not been trained on enough data, its accuracy may decrease. This could have serious consequences in fields such as healthcare or finance, where incorrect predictions could have life-changing implications.
Limited Capabilities: Without enough data, an AI model may not be able to perform certain tasks. For example, a language translation model that has not been trained on a wide range of languages may not be able to accurately translate between them.
Increased Vulnerability: As mentioned earlier, a lack of data could make an AI model more vulnerable to adversarial attacks. This could be especially concerning in applications such as autonomous vehicles or cybersecurity, where incorrect predictions could have serious consequences.
While data shortage could have serious consequences for AI models, there are several solutions that could help mitigate the effects.
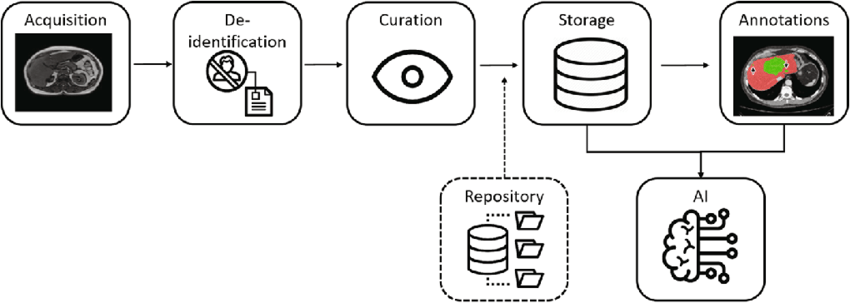
Here are some possible solutions:
Data Augmentation: Data augmentation involves artificially creating new data by making subtle changes to existing data. This can help increase the amount of data available for training, and also make the AI model more robust to variations in the input data.
Transfer Learning: Transfer learning involves using a pre-trained AI model as a starting point for training a new model on a different task or dataset. This can help reduce the amount of data needed to train a new model, as the pre-trained model has already learned many of the relevant patterns and relationships.
Active Learning: Active learning involves selecting the most informative data points to label during the training process, in order to maximize the amount of information gained from each labeled example. This can help reduce the amount of labeled data needed to achieve a certain level of accuracy.
Synthetic Data: Synthetic data involves generating new data that closely mimics the characteristics of the real data. This can be useful in situations where there is a limited amount of real data available, or where the real data is difficult or expensive to collect.
Collaborative Data Sharing: Collaborative data sharing involves pooling data resources from multiple sources to create a larger, more diverse dataset. This can help increase the amount of data available for training AI models and improve their accuracy.
Human-in-the-Loop: Human-in-the-loop involves human input in the training process, such as by having human experts label or verify data. This can help ensure that the AI model is learning from high-quality data, and also improve its accuracy in certain domains where human expertise is valuable.
Active Data Collection: Active data collection involves actively collecting new data in order to expand the dataset available for training. This could involve using sensors or other devices to collect new data, or incentivizing individuals or organizations to contribute data.
These solutions can help mitigate the effects of a data shortage for AI models. However, it is important to note that each solution has its own limitations and challenges. For example, data augmentation may not be effective in all domains, and synthetic data may not perfectly replicate the characteristics of real data.
Furthermore, some of these solutions may not be applicable in certain domains due to privacy concerns or other ethical considerations. For example, collaborative data sharing may be difficult in fields such as healthcare, where patient data privacy is a top priority.
As the use of AI continues to grow, the need for large amounts of data to train these models will only increase. A data shortage could have serious consequences for the accuracy and capabilities of AI models, as well as their vulnerability to attacks.
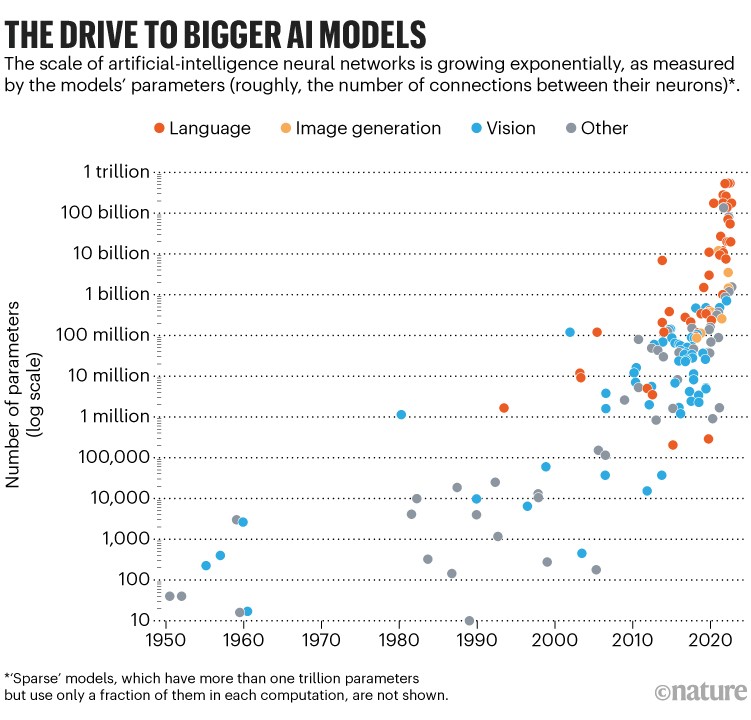
There are several solutions that can help mitigate the effects of a data shortage, such as data augmentation, transfer learning, and active learning. It is important to carefully consider the limitations and challenges of each solution, as well as any ethical or privacy concerns, when developing AI models.
In the end, a collaborative approach that involves experts from various fields and stakeholders from different domains may be the most effective way to address the challenges of a data shortage for AI models. By working together, we can ensure that AI continues to be a powerful tool for solving complex problems, even in the face of limited data.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest