

Comments
- No comments found

There is an interesting tug-of-war going on right now.
On one side are the machine learning folks, those who have been harnessing neural networks for a few years. In their view of the world, everything should be a neural net, and if only everyone else would adopt neural nets, they would see that it solves all of humanity's problems. To them, everything is an LLM.
On the other side of the rope are the Symbolic AI folk, mostly rallying around knowledge graphs. A knowledge graph is a graph of information, a connected network where each node is a concept and each edge is a relationship. These people have been around for a lot longer, though it can be argued that neural nets and knowledge graphs have both been around since the 1950s. It can be further argued that the argument about which is superior has been going on for nearly as long.
The latest point of contention concerns two similar technologies that serve somewhat different functions. The first is Retrieval Augmented Generation, known by the rather inflatory appellation RAG. RAG can be thought of as an escape hatch for LLM, a way for other data stores to weigh in on matters within large language models that involves (horrors!) querying external datasets.
The second technology involves context, which can be thought of as the amount of tokens that can be held in an LLM's "memory" at any given time. The larger the context, the more memory that's available to build information used within a response, and consequently the more "accurate" (i.e., non-hallucinatory) a given response is likely to be. In the neural network world, if you could build a large enough context, you would not in fact need any other data source, because everything could be kept in the context.
There are a few limitations with context, however, that can be seen after a bit of introspection:
The larger the context, the longer it takes to read that context, and especially as some queries are actually negative in they return no reasonable responses (how many Tyrannosaurs can be found in South America, for instance), the cost of reading all of these context tokens can be prohibitive looking for an answer can be prohibitive.
Sometimes you simply can't get all the data that you're looking for within an LLM. When you consider that the information outside of LLMs (even taking into account the massive Internet crawlers that Bing, Google, etc. all have) still dwarfs by several orders of magnitude the data within LLMs. This should not be that surprising.
In both humans and LLMs, most contextual information is not relevant to the focused task at hand. Humans are remarkably adept at screening most of this out (one of the loudest sounds in the human body is the sound of blood rushing into and out of your ears, yet, except in very rare circumstances, you likely don't even realize that it's there). This doesn't hold true for contexts (though there are some interesting developments there). Determining what is not relevant within a context stream is a considerably more costly venture for a machine-learning system.
These factors don't obviate the power of contexts - you can, in fact, do a number of useful things with a sufficiently large context, just as you can with any memory system. However, after a certain point of making the context larger you get diminishing returns, and contexts generally don't solve the problem of dynamic data, which is something that RAG is much more suited for.
It's worth noting that knowledge graphs have their own set of problems, which have prevented them from gaining the same level of penetration that LLMs are beginning to enjoy.
They require a fairly significant amount of work to design, set up and manage, especially if you are unfamiliar with them.
While they can be deeply queried using SPARQL or similar languages, writing such queries often requires specialist knowledge that is not widely available.
You need to understand the schema used to query the knowledge graph, and such schemas can be complex and poorly documented.
Given these things, using knowledge graphs would seem like a non-starter. However, their advantages outweigh the disadvantages significantly:
It is possible to summarize complex, highly interdependent relationships with knowledge graphs that would be difficult or even impossible to do in relational graphs.
Knowledge graphs work with unique conceptual identifiers. This means that concepts can be related to other concepts in different systems, making them quite useful for data interchange across systems as well as for handling master data management.
Knowledge graphs can be serialized and transferred between systems because they are database agnostic. They are also designed to remove duplication. They can be represented as JSON, XML, Turtle, CSV or many other formats.
They are a superset of other formats - you can represent XML, JSON, Excel documents relational data and document structures as a graph, but its much harder to represent hierarchical JSON or XML in a traditional relational database without treating it as a BLOB of some sort.
While the way that LLMs represent information is very different from knowledge graphs, by embedding knowledge graphs into LLMs you cause considerably better inferencing and reasoning from the LLM than otherwise would be the case, as well as significantly mitigating hallucinations.
These factors combine to make knowledge graphs powerful tools for managing large language models, while at the same time LLMs can be used to simplify the process of querying these databases.
Most queries actually rely upon both structural and taxonomic ontologies the first identifying structural relationships, the second describing entities such as people, places, things, categories, and intellectual property.
One useful combination of ontologies is the schematic structure of schema.org, which provides a surprisingly comprehensive general ontology for describing general constructs, along with the use of Wikipedia URLs to describe various entities, from presidents to countries to movies to technologies and books.
The following prompt set the stage in ChatGPT:

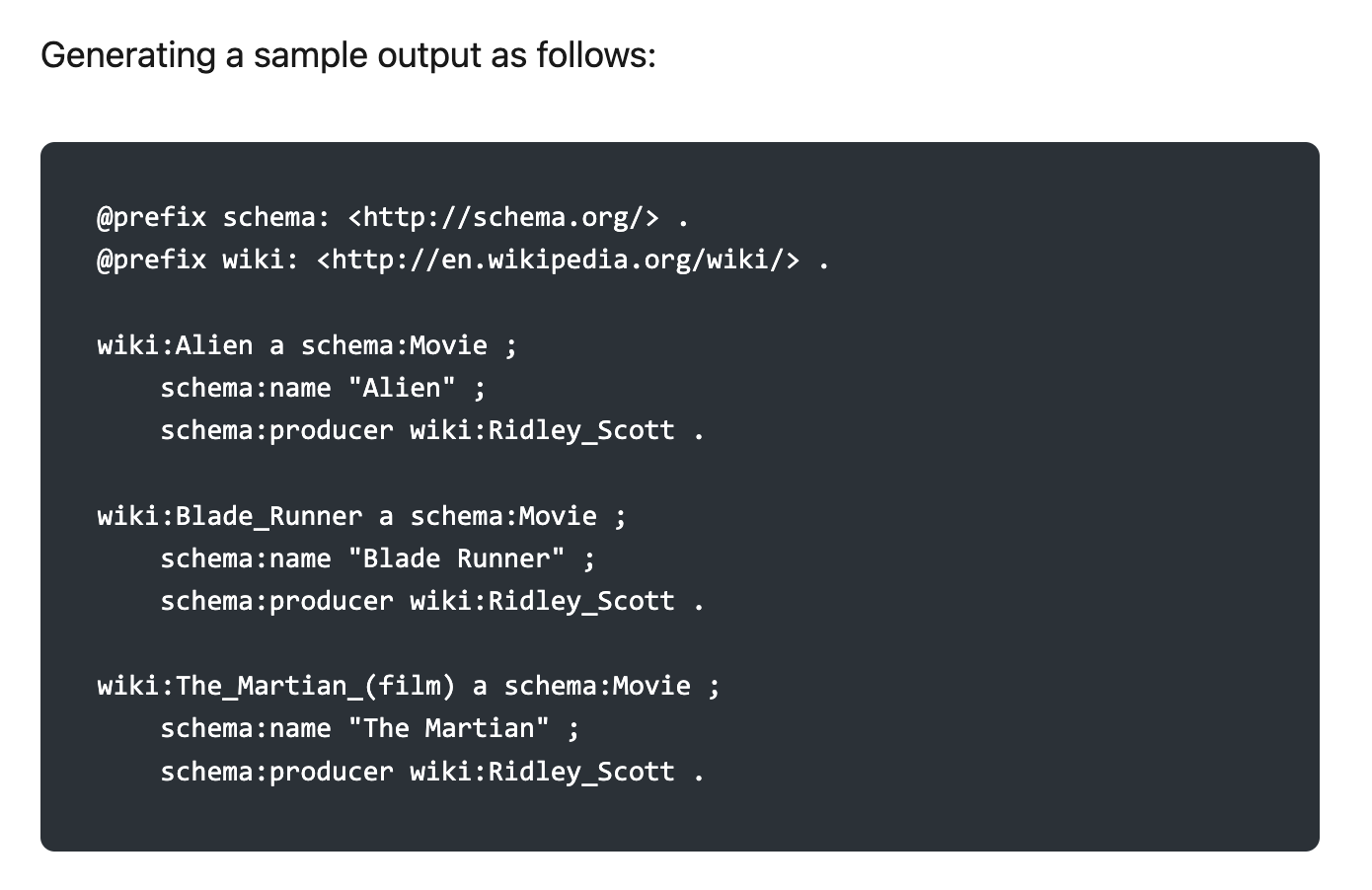
There are a few items to note: In this case, ChatGPT spidered both Wikipedia and Schema.org, and consequently has the identifiers for both in its rather capacious latent space. This can be very useful, both because it means that ChatGPT does in fact have at least one (and in fact several) schemas and reference taxonomies that are currently loaded, meaning that if you are using either ChatGPT or Copilot, you stand a good chance of being able to do inferencing if you follow the schema.org model, without having to do anything else in prep.
The second thing to note is that an intrinsic lookup has already taken place to retrieve the reference to wiki:Ridley_Scott. You can change this so that it is a parameter passed via a values statement, with an additional rule.
The $ in SPARQL queries is equivalent to the question mark, but it often is used to indicate a variable being passed into the sparql query. If no variable is passed, the value (in the above example) wiki:George_Lucas is used.

The advantage to this approach is that you can use it to build templates. Note also this made use of the CONSTRUCT command to build a set of triples. This output in turn can also be used to construct a compact JSON-LD structure document:
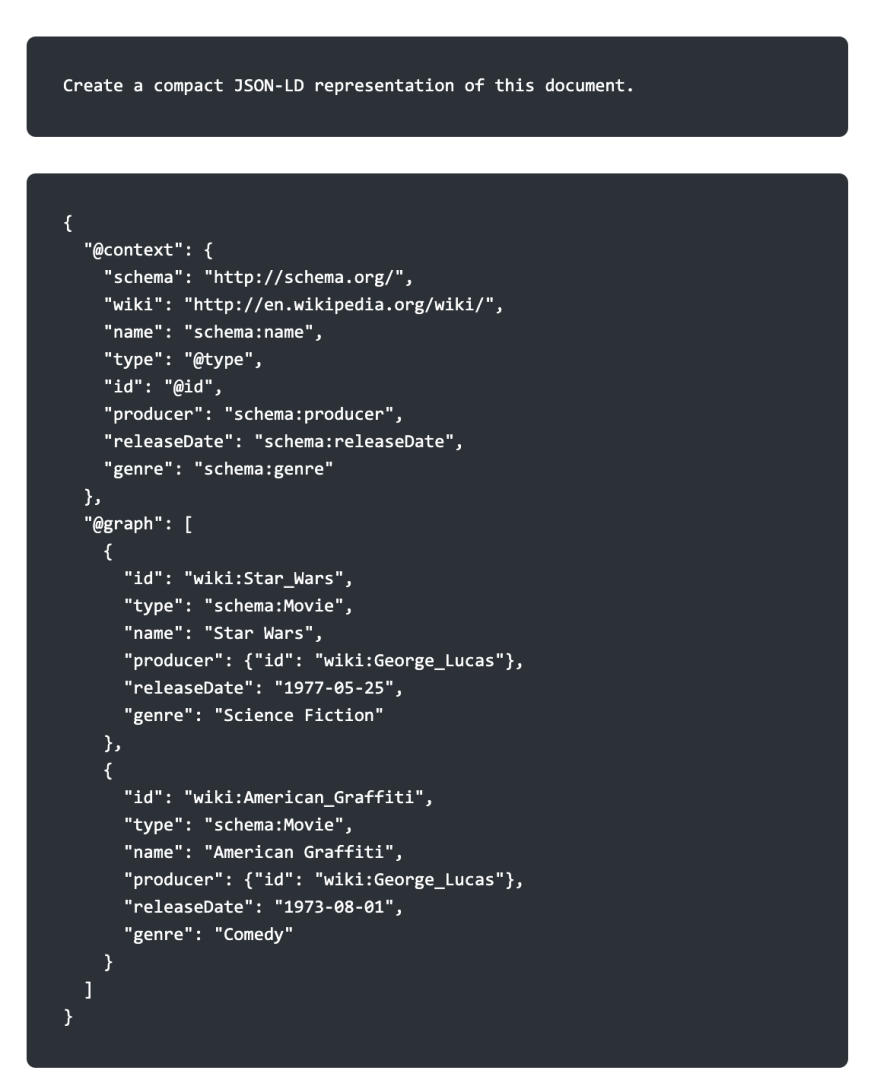
Finally, this can make use of an LLM call to convert the response from the Turtle into a form that can be passed into a LangChain as part of a RAG (Retrieval Augmented Generation) process:
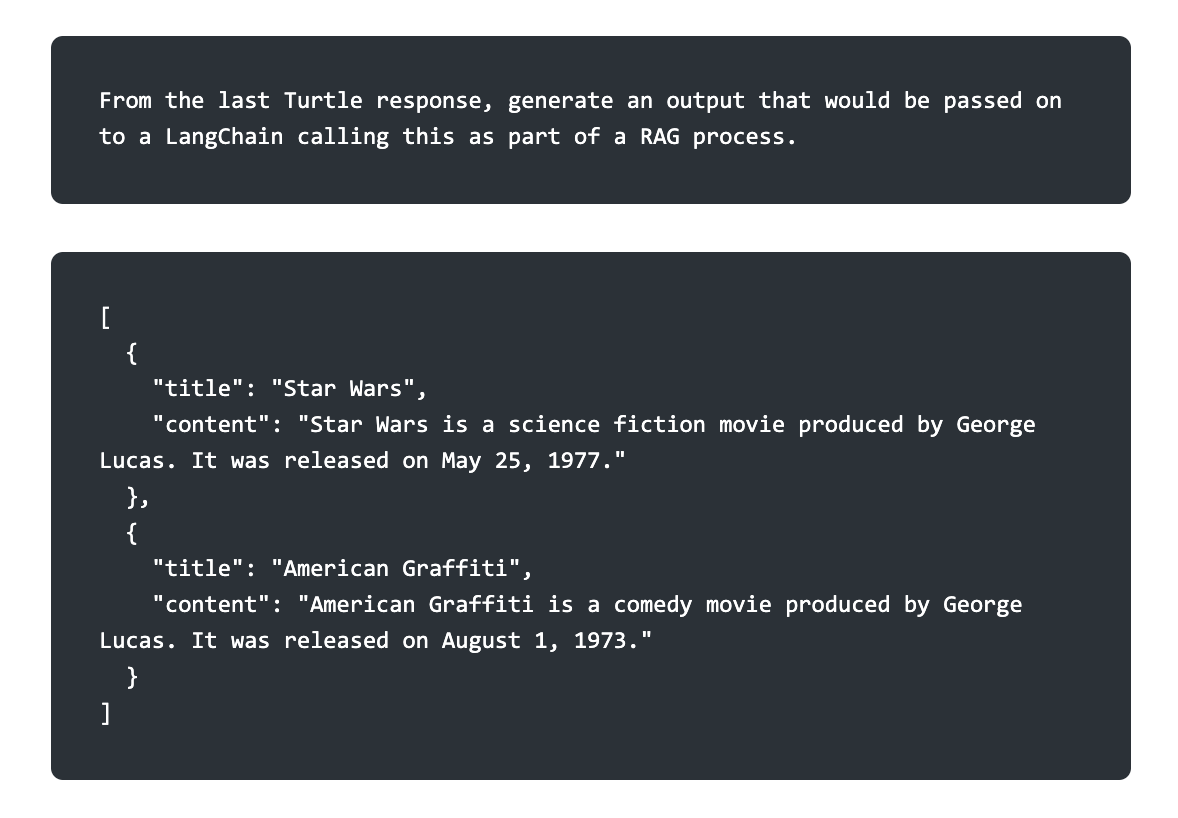
Note that the LLM has converted the content into a minimal text representation for each movie, taking advantage of the fact that it knows the identifiers in order to retrieve labels for each of the relevant fields.
You can also see that ChatGPT does have an understanding of at least Wikipedia entries:
This is a fairly basic example of what can be done with combining knowledge graphs and LLMs, and is a topic I will revisit in the near future. This approach of combining schema.org and Wikipedia is also especially useful because it is generally much easier to convert RDF into other RDF forms than it is to convert non-RDF into RDF.
Copyright 2024 Kurt Cagle / The Cagle Report
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest