Comments
- No comments found

One of the challenges facing businesses in post-COVID-19 world is the fact that consumer behavior won’t go back to pre-pandemic norms.
Consumers will purchase more goods and services online, and increasing numbers of people will work remotely just to mention a few major changes . As companies begin to navigate the post-COVID-19 world as economies slowly begin to reopen, the use of data analytics tools will be extremely valuable in helping them adapt to these new trends. Data analytics tools will be particularly useful for detecting new purchasing patterns and delivering a greater personalized experience to customers, in addition to better understanding of consumers' new behavior.
However, many companies are still dealing with obstacles to successful big data projects. Across industries, the adoption of big data initiatives is way up. Spending has increased, and the vast majority of companies using big data expect return on investment. Nevertheless, companies still cite a lack of visibility into processes and information as a primary big data pain point. Modeling customer segments accurately can be impossible for businesses who don’t understand why, how and when their customers decide to make purchases for example.
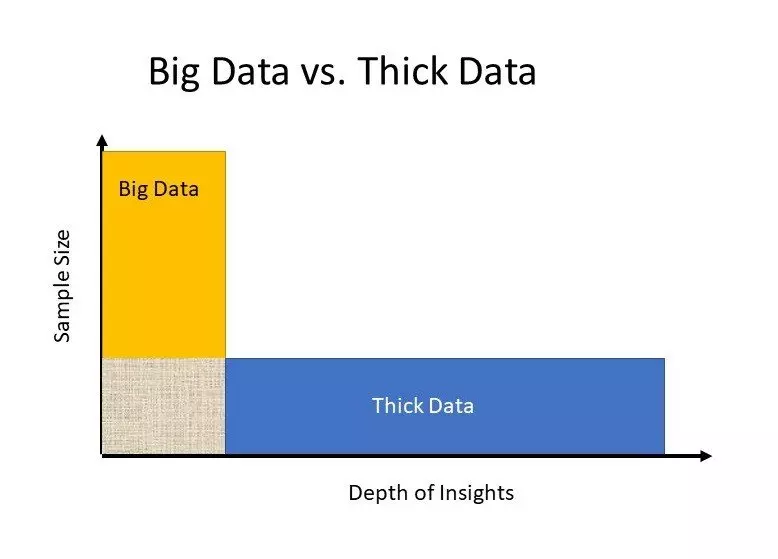
To tackle this pain point companies might need to consider an alternative to big data, namely thick data, it’s helpful to define both terms, Big Data vs. Thick Data.
Big Data is large and complex unstructured data, defined by 3 V’s; Volume, with big data, you’ll have to process high volumes of low-density, unstructured data. This can be data of unknown value, such as Facebook actions, Twitter data feeds, clickstreams on a web page or a mobile app, or sensor-enabled equipment. For some organizations, this might be tens of terabytes of data. For others, it may be hundreds of petabytes. Velocity: is the fast rate at which data is received and acted on. Variety refers to the many types of data that are available. Unstructured and semi-structured data types, such as text, audio, and video, require additional preprocessing to derive meaning and support metadata.
Thick Data is about a complex range of primary and secondary research approaches, including surveys, questionnaires, focus groups, interviews, journals, videos and so on. It’s the result of the collaboration between data scientists and anthropologists working together to make sense of large amounts of data. Together, they analyze data, looking for qualitative information like insights, preferences, motivations and reasons for behaviors. At its core, thick data is qualitative data (like observations, feelings, reactions) that provides insights into consumers' everyday emotional lives. Because thick data aims to uncover people's emotions, stories, and models of the world they live in, it can be difficult to quantify.
Thick Data can be a top-notch differentiator, helping businesses uncover the kinds of insights they sometimes hope to achieve from big data alone. It can help businesses look at the big picture and put all the different stories together, while embracing the differences between each medium and using them to pull out interesting themes and contrasts. Without a counterbalance the risk in a Big Data world is that organizations and individuals start making decisions and optimizing performance for metrics—metrics that are derived from algorithms, and in this whole optimization process, people, stories, actual experiences, are all but forgotten.
If the big tech companies of Silicon Valley really want to “understand the world” they need to capture both its (big data) quantities and its (thick data) qualities. Unfortunately, gathering the latter requires that instead of just ‘seeing the world through Google Glass’ (or in the case of Facebook, Virtual Reality) they leave the computers behind and experience the world first hand. There are two key reasons why:
Rather than seeking to understand us simply based on what we do as in the case of big data, thick data seeks to understand us in terms of how we relate to the many different worlds we inhabit.
Only by understanding our worlds can anyone really understand “the world” as a whole, which is precisely what companies like Google and Facebook say they want to do. To “understand the world” you need to capture both its (big data) quantities and its (thick data) qualities.
In fact, companies that rely too much on the numbers, graphs and factoids of Big Data risk insulating themselves from the rich, qualitative reality of their customers’ everyday lives. They can lose the ability to imagine and intuit how the world—and their own businesses—might be evolving. By outsourcing our thinking to Big Data, our ability to make sense of the world by careful observation begins to wither, just as you miss the feel and texture of a new city by navigating it only with the help of a GPS.
Successful companies and executives work to understand the emotional, even visceral context in which people encounter their product or service, and they are able to adapt when circumstances change. They are able to use what we like to call Thick Data which comprises the human element of Big Data.
One promising technology that can give us the best of both worlds (Big Data and Thick Data) is affective computing.
Affective computing is the study and development of systems and devices that can recognize, interpret, process, and simulate human affects. It is an interdisciplinary field spanning computer science, psychology, and cognitive science. While the origins of the field may be traced as far back as to early philosophical enquiries into emotion ("affect" is, basically, a synonym for "emotion."), the more modern branch of computer science originated with Rosalind Picard's 1995 paper on affective computing. A motivation for the research is the ability to simulate empathy. The machine should interpret the emotional state of humans and adapt its behavior to them, giving an appropriate response for those emotions.
Using affective computing algorithms in gathering and processing data will make the data more human and show both sides of data: quantitative and qualitative.
Ahmed Banafa is an expert in new tech with appearances on ABC, NBC , CBS, FOX TV and radio stations. He served as a professor, academic advisor and coordinator at well-known American universities and colleges. His researches are featured on Forbes, MIT Technology Review, ComputerWorld and Techonomy. He published over 100 articles about the internet of things, blockchain, artificial intelligence, cloud computing and big data. His research papers are used in many patents, numerous thesis and conferences. He is also a guest speaker at international technology conferences. He is the recipient of several awards, including Distinguished Tenured Staff Award, Instructor of the year and Certificate of Honor from the City and County of San Francisco. Ahmed studied cyber security at Harvard University. He is the author of the book: Secure and Smart Internet of Things Using Blockchain and AI.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest