Comments
- No comments found

Today’s artificial intelligence (AI) is limited. It still has a long way to go.
Some AI researchers are getting an insight that machine learning algorithms, in which computers learn through trial and error, have become a form of "alchemy."
Recent advances in artificial intelligence (AI) are improving many aspects of our lives.
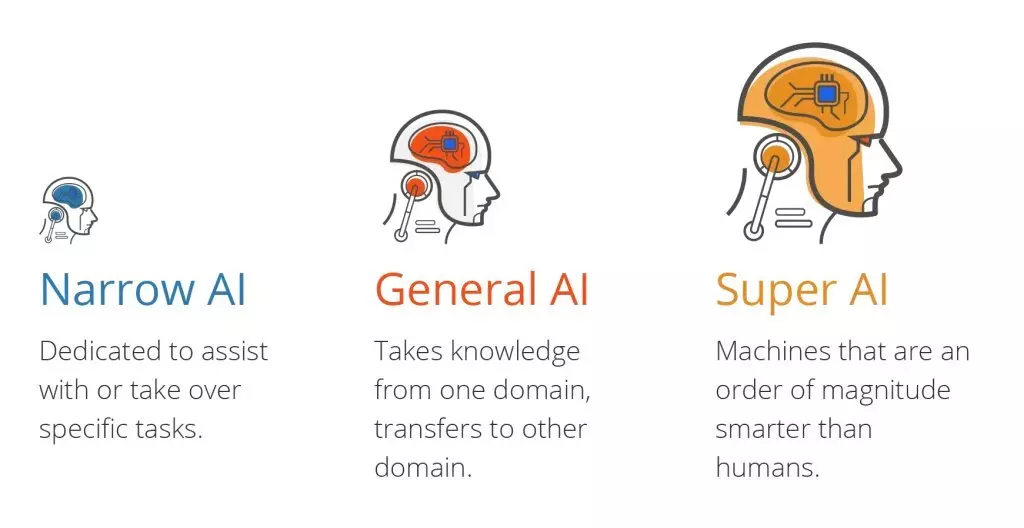
There are three types of artificial intelligence:
Artificial narrow intelligence (ANI), which has a narrow range of abilities.
Artificial general intelligence (AGI), which is on par with human capabilities.
Artificial superintelligence (ASI), which is more capable than a human.
Today's AI is mostly driven by statistical learning models and algorithms, designated as data analytics, machine learning, artificial neural networks or deep learning. It is implemented as a combination of IT infrastructure (ML platform, algorithms, data, compute) and development stack (from libraries to languages, IDE, workflow and visualisation).
In all, it involves:
some applied maths, probability theory and statistics,
some statistical learning algorithms, logic regression, linear regression, decision trees and random forests,
some machine learning algorithms, supervised, unsupervised and reinforced.
some ANNs, DL algorithms and models, filtering the input data through many layers to predict and classify information,
some optimized (compressing and quantizing) trained neural network models,
some statistical patterns and inferences, like the Qualcomm Neural Processing SDK,
some programming languages, as Python and R., with their libraries and packages,
some ML platforms, frameworks and runtimes such as PyTorch, ONNX, Apache MXNet, TensorFlow, Caffe2, CNTK, SciKit-Learn, and Keras,
some integrated development environments (IDE), such as PyCharm, Microsoft VS Code, Jupyter, MATLAB, etc.,
some physical servers, virtual machines, containers, specialized hardware such as GPUs, cloud-based computational resources including VMs, containers, and Serverless computing.
Most AI applications in use today can be categorized as being narrow AI, referred to as weak AI.
They all are missing general artificial intelligence and machine learning, which is defined by three critical interacting engines:
World Model [Representation, Learning and Inference] Machine, or Reality Simulating Machine (World Hypergraph Network).
World Knowledge Engine (Global Knowledge Graph)
World Data Engine (Global Data Graph Network)
General AI and ML and DL programs/machines/systems are distinguished by understanding the world as multiple plausible world state representations with its Reality Machine and Global Knowledge Engine and World Data Engine.
It is the most essential component of General/Real AI Stack, interacting with its real-world Data Engine, and providing the intelligent functions/capacities:
to process information about the world
to estimate/compute/learn the state of the world models
to generalize its data elements, points, sets
to specify its data structure and types
to transfer its learning
to contextualize its content
to form/discover causal data patterns, as causal regularities, rules, and laws
to infer causality within all possible interactions, causes, effects, loops, systems and networks
to predict/retrodict the states of the world at different scopes and scales and different levels of generalization and specification
to effectively and efficiently interact with the world, adjusting to it, navigating it and manipulating its environment according to its intelligent predictions and prescriptions
AI researchers allege that machine learning is alchemy
In fact, it is largely about statistical inductive inference machines relying on big data computing, algorithmic innovations and statistical learning theory and connectionist philosophy.
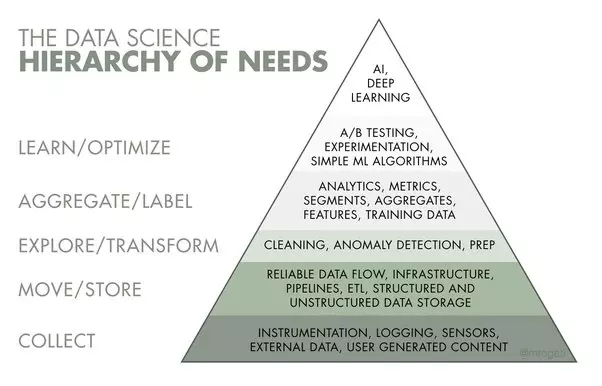
For most people it is merely building a machine learning (ML) model with an easy journey, going via data collection, curation, exploration, feature engineering, model training, evaluation, and finally, deployment.
EDA: Exploratory Data Analysis
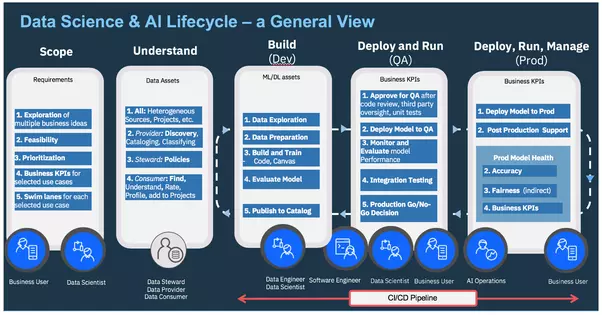
AI Ops — Managing the End-to-End Lifecycle of AI
Today's AI Alchemy is coming from "Machine Learning", which algorithms need to be configured and tuned for every different real-world scenario. This makes it very manually intensive and takes a huge amount of time from a human supervising its development. This manual process is also error-prone, not efficient, and difficult to manage. Not to mention the scarcity of expertise out there to be able to configure and tune different types of algorithms.
The configuration, tuning, and model selection is increasingly automated, and all big-tech companies, such as Google, Microsoft, Amazon, IBM, are coming with the similar AutoML platforms, automating the Machine Learning model building process.
AutoML involves automating the tasks that are required for building a predictive model based on machine learning algorithms. These tasks include data cleansing and preprocessing, feature engineering, feature selection, model selection, and hyperparameter tuning, which can be tedious to perform manually.
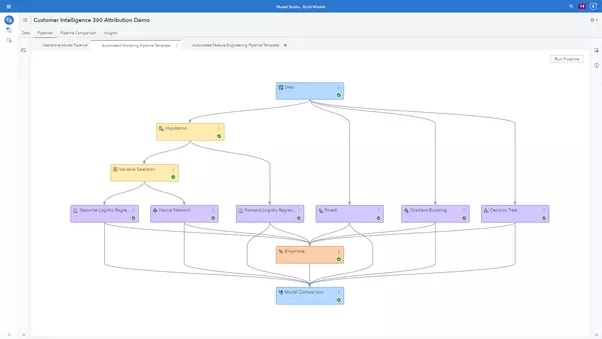
And the end-to-end ML pipeline presented is consisting of 3 key stages, while missing the source of all data, the world itself:
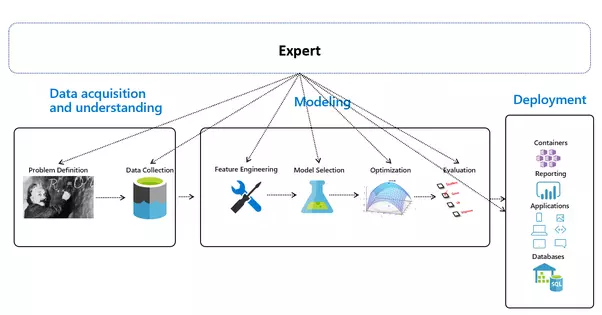
Automated Machine Learning — An Overview
The key secrecy of the Big-Tech AI alchemists is the Skin-Deep Machine Learning going as Dark Deep Neural Networks, which models demand training by a large set of labeled data and neural network architectures that contain as many layers as impossible.
Each task needs its special network architecture:
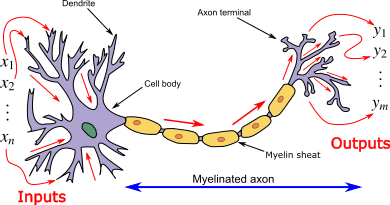
ANN was introduced as an information processing paradigm as if to be inspired by the way the biological nervous systems/brain process information. And such ANN is represented as “Universal Function Approximators”, which can learn/compute all sorts of activation functions.
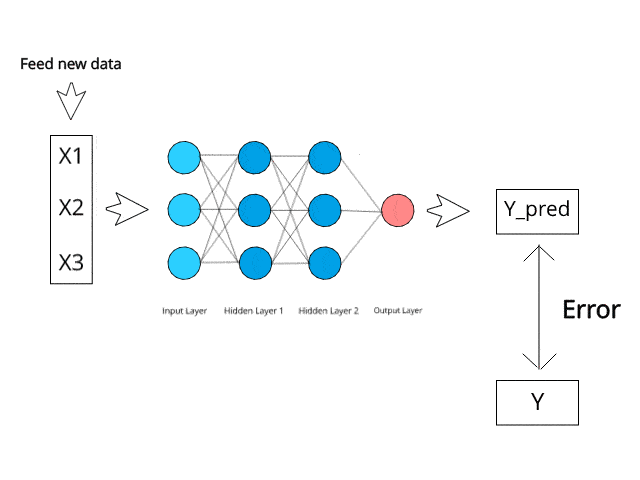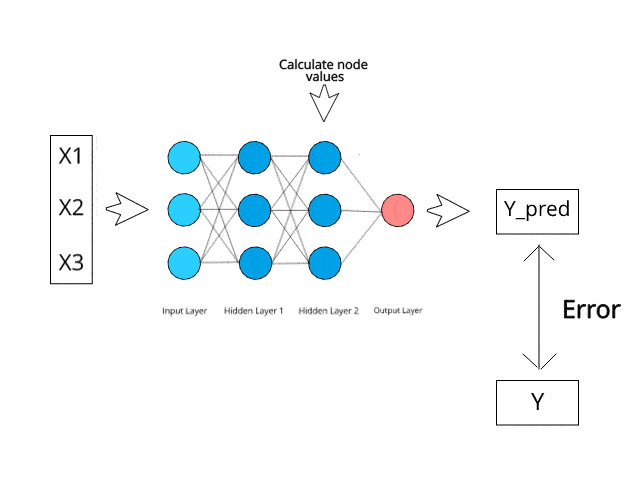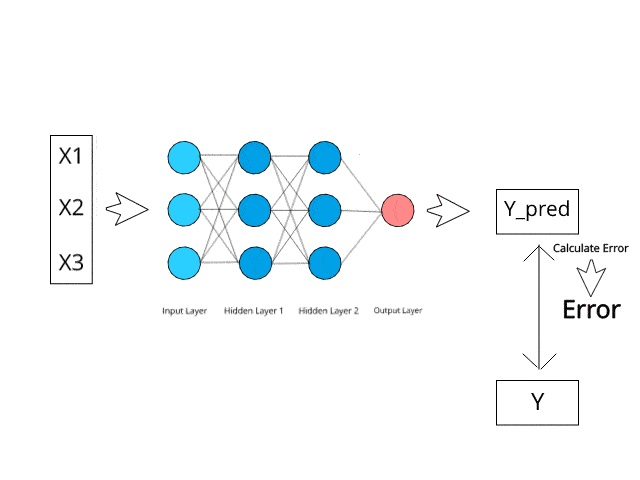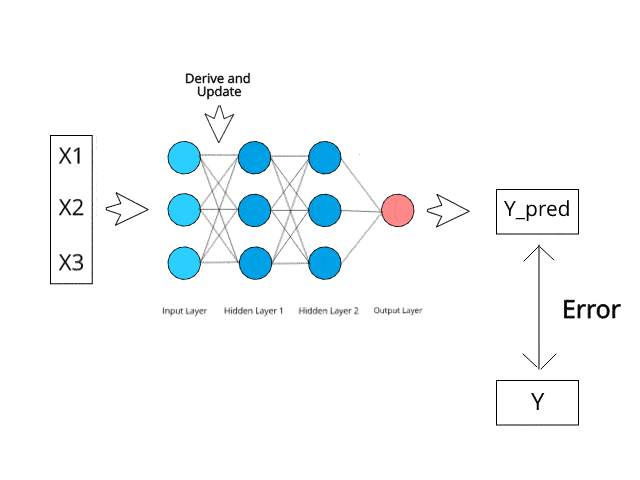
Neural networks compute/learn through a specific mechanism of backpropagation and error correction during the testing phase.
Just imagine that by minimizing the error, these multi-layered systems are expected one day to learn and conceptualize ideas by themselves.
Introduction to Artificial Neural Networks (ANN)
In all, a few lines of R or Python code will suffice for a piece of machine intelligence and there’s a plethora of resources and tutorials online to train your quasi-neural networks, like all sorts of deepfake networks, manipulating image-video-audio-text, with zero knowledge of the world, as Generative Adversarial Networks, BigGAN, CycleGAN, StyleGAN, GauGAN, Artbreeder, DeOldify, etc.
They create and modify faces, landscapes, universal images, etc., with zero understanding what it is all about.




Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
14 Deep and Machine Learning Uses That Made 2019 a New AI Age.
There is a myriad of digital alchemy tools and frameworks going in their own ways:
Open languages — Python is the most popular, with R and Scala also in the mix.
Open frameworks — Scikit-learn, XGBoost, TensorFlow, etc.
Approaches and techniques — Classic ML techniques from regression all the way to state-of-the-art GANs and RL
Productivity-enhancing capabilities — Visual modeling, AutoAI to help with feature engineering, algorithm selection and hyperparameter optimization
Development tools — DataRobot, H2O, Watson Studio, Azure ML Studio, Sagemaker, Anaconda, etc.
As a sad result, a Data Scientist’s working environment: scikit-learn, R, SparkML, Jupyter, R, Python, XGboost, Hadoop, Spark, TensorFlow, Keras, PyTorch, Docker, Plumbr, and the list goes on and on, is providing the whole "Fake AI Stack" for your alchemy of AI.
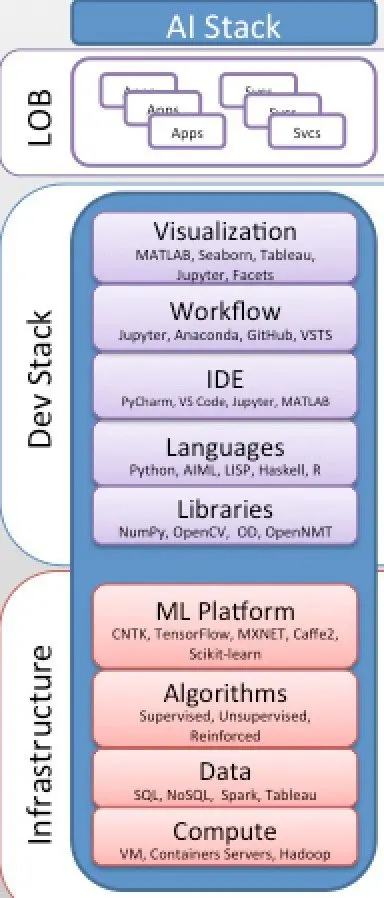
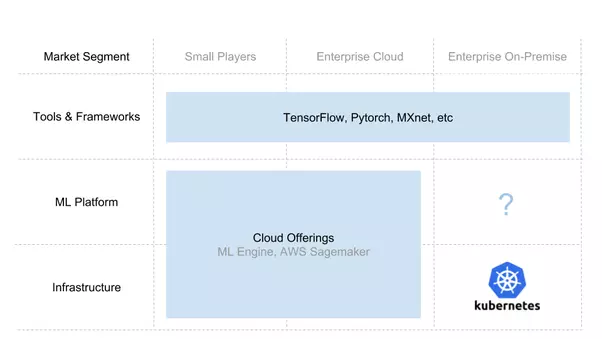
Modern AI Stack & AI as a Service Consumption Models
What is impersonated as AI, is in fact, a false and counterfeit AI. At the very best, it is a sort of automatic learning technologies, ML/DL/NN pattern-recognizers, which are essentially mathematical and statistical in nature, unable to act intuitively or model their environment, being with zero intelligence, nil learning and NO understanding.
Despite its numerous advantages, artificial intelligence isn’t perfect. Here are 8 issues that are harming the progress of artificial intelligence and what's fundamentally wrong:
Artificial intelligence requires massive data sets to train on, and these should be inclusive/unbiased, and of good quality. There can also be times where they must wait for new data to be generated.
Artificial intelligence requires enough time to let the algorithms learn and develop enough to fulfill their purpose with a considerable amount of accuracy and relevancy. It also needs massive resources to function. This can mean additional requirements of computer power for you.
Another major challenge is the ability to accurately interpret results generated by the algorithms. You must also carefully choose the algorithms for your purpose.
Artificial intelligenceis autonomous but highly susceptible to errors. Suppose you train an algorithm with data sets small enough to not be inclusive. You end up with biased predictions coming from a biased training set. This leads to irrelevant advertisements being displayed to customers. In the case of machine learning, such blunders can set off a chain of errors that can go undetected for long periods of time. And when they do get noticed, it takes quite some time to recognize the source of the issue, and even longer to correct it.
The idea of trusting data and algorithms more than our own judgment has its pros and cons. Obviously, we benefit from these algorithms, otherwise, we wouldn’t be using them in the first place. These algorithms allow us to automate processes by making informed judgments using available data. Sometimes, however, this means replacing someone’s job with an algorithm, which comes with ethical ramifications. Additionally, who do we blame if something goes wrong?
Artificial intelligence is still a relatively new technology. From the start code to the maintenance and monitoring of the process, machine learning experts are required to maintain the process. Artificial Intelligence and machine learning industries are still freshers to the market. Finding enough resources in the form of manpower is also difficult. Hence, there is a lack of talented representatives available to develop and manage scientific substances for machine learning. Data researchers regularly need a mix of space insight just as top to bottom knowledge of mathematics, technology, and science.
Artificial intelligencerequires a tremendous amount of data stirring abilities. Inheritance frameworks can’t deal with the responsibility and clasp under tension. You should check if your infrastructure can deal with issues in artificial intelligence. If it can’t, you should hope to upgrade it completely with good hardware and adaptable storage.
Artificial intelligence is time-consuming. Due to an overload of data and requirements, it takes longer than expected to provide results. Focusing on particular features within the database in order to generalize the outcomes is very common in machine learning models, which lead to bias.
Artificial intelligence has taken over many aspects of our life. Although it's not perfect, artificial intelligence is a continuously evolving field with high demand. Without human intervention, it delivers real-time results using the already existing and processed data. It generally helps analyze and assess large amounts of data with ease by developing data-driven models. Although there are many issues in artificial intelligence, it's an evolving field. From medical diagnosis, vaccine development to advanced trading algorithms, artificial intelligencehas become vital to scientific progress.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest