Healthcare data science has been growing rapidly for several years, although the use of data to understand and address mental health problems has lagged behind the rest of the field.
In many ways, however, mental health is perfectly suited for data science approaches: the burden of mental illness in the US is enormous, often unaddressed, and not fully understood, creating enormous potential for data-driven research and solutions. In this article I will highlight the importance of applying data science methodologies to problems in mental health, walk through 3 case studies representing important advancements in this area, and describe one of my own research projects using Google search data to assess suicidality.
Data Science in Healthcare
Data science has developed an increasing presence in healthcare as new data sources and analytic techniques have become available. Although there is a somewhat blurry line between the academic research and clinical trials that have been an integral part of healthcare for decades and work that falls under the new umbrella of “data science,” it is undeniable that the use of new technologies and data sources in healthcare has boomed.
In addition to traditional sources of healthcare data such as patient medical records, hand-written doctors’ notes, billing and claims data, and data from clinical trials, researchers and data scientists now have access to genomics data, electronic medical record (EMR) data, data from wearable and mobile devices, as well as data representing social media and internet activity. The move to computerization and the development of analytic techniques such as natural language processing have unlocked new potential in existing data sources, and additional insights can be gathered using novel data sources on their own and in combination with these existing sources.
Three of the most prominent applications of data science in healthcare are as follows:
- Image recognition for diagnostic purposes (e.g., malignancies and organ abnormalities)
- Developments towards precision medicine using genomics data (such as the 1000 Genomes Project from the National Institutes of Health), which tend to focus on chronic diseases like heart disease and diabetes
- Hospital operations analyses, which often look like standard business analyses (e.g., predicting when the ER will need more staff)
These three examples represent important developments that have been made in healthcare data science, but also demonstrate that data science in healthcare has often focused on chronic diseases and the business side of healthcare. There’s been lots of advancement, but data science in mental health is lagging behind.
Burden of Mental Health Problems
The burden of mental illness in the United States is extraordinary. Approximately one in five Americans lives with a mental illness, and this rate is even higher among young people, women, LGBTQIA+ individuals, and certain minority groups. Among 10- to 34-year-olds, suicide is the second leading cause of death.
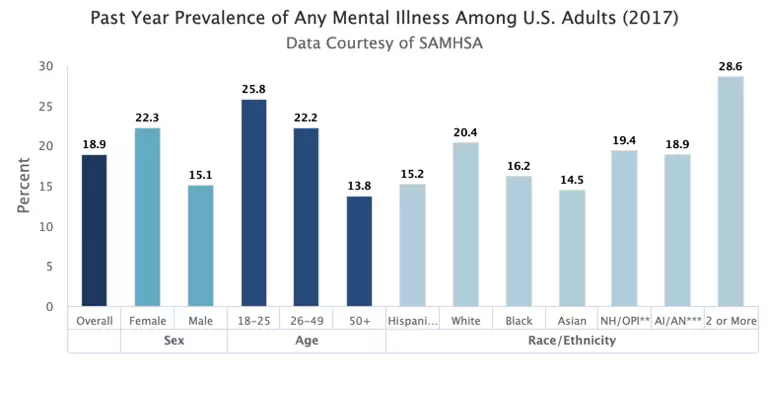
Image from:https://www.nimh.nih.gov/health/statistics/mental-illness.shtml
Unfortunately, most people with a mental health problem are not receiving appropriate treatment. In 2018, only 43.3% of adults with a mental illness received treatment for it. Among those who do eventually receive treatment, the average delay between symptom onset and treatment initiation is a staggering 11 years. While there are several contributing factors to this treatment gap, inaccessibility of mental health providers is one of the most important. About 40% of Americans live in a designated mental healthcare shortage area, and many mental health professionals are inaccessible to lower-income Americans as they do not participate in insurance plans.
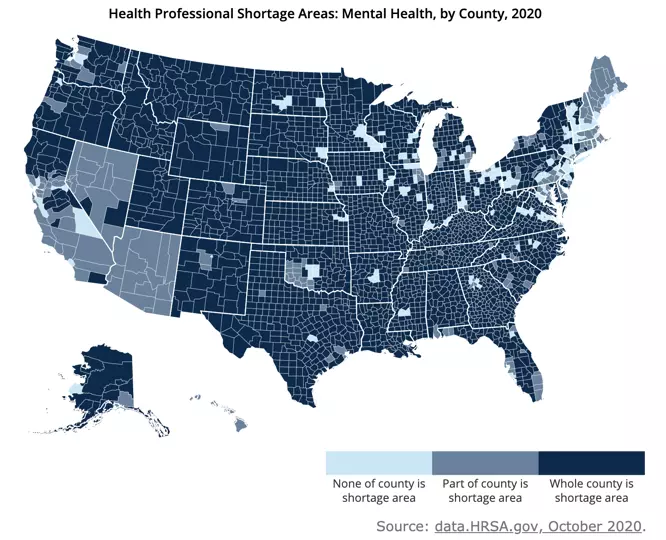
Image with permission from RHIhub (https://www.ruralhealthinfo.org/charts/7) using data from the Health Resources and Services Administration (HRSA).
Failure to treat mental illness has enormous consequences for afflicted individuals as well as for their communities. People with mental health problems are more likely to develop physical conditions such as cardiovascular and metabolic diseases, to drop out of school, to be unemployed, to experience homelessness, and to become incarcerated.
How Data Science Can Help
Clearly, there is enormous unmet need within the United States regarding mental health. There are two primary ways in which data science can help bridge this gap.
First, data science can help us to better understand mental health problems. Who is experiencing mental illness? What signs and symptoms are important diagnostic clues? What makes someone more likely to engage with and stay in treatment? What do mental health problems look like in different populations?
Data that can actually answer these questions are becoming increasingly available, or at least possible to collect. Data from wearable devices can be used to identify physiological markers associated with mental illness, social media and internet activity can provide insight into a behavioral side of mental health, doctor and therapist notes can increasingly be analyzed using natural language processing, and brain scans may be ideal candidates for diagnostic image recognition.
Second, data science can help us to better understand and effectively implement treatments for mental health problems. Many patients try numerous therapists, therapy techniques, and medications before finding something that works for them. This extensive process to find appropriate care is particularly problematic given how long most patients wait before receiving any care, as well as the cost and emotional difficulty associated with trying numerous options. It’s therefore important to be able to assess whether or not a given treatment (formal psychiatric care or otherwise) works. If so, who does it work for? How can we make it accessible to more people?
Some of these questions can be addressed using standard clinical trials, although they often are limited by small and unrepresentative samples. Analyses that evaluate new technologies such as self-guided therapy apps and chat services are also crucially important for assessing the quality of these interventions. Eventually, advancements in genomics and precision medicine may be able to help patients find a treatment that meets their individual needs far more efficiently than standard approaches. Additionally, machine learning-based chat bots and other relevant AI are still in their infancy but have demonstrated enormous potential as eventual therapy alternatives.
There are so many opportunities to use data science to improve the state of mental health care, but more companies, providers, and individuals have to push for these possibilities to become reality.
Challenges
There are several noteworthy challenges standing in the way of advancing data science in mental health, although they are far from insurmountable.
Mental health problems are still highly stigmatized, which presents both a funding issue and a data issue. Although interest in and awareness of mental health is certainly expanding, there is still not the widespread support that exists for a disease like cancer. Additionally, patients may be more concerned about how data representative of their mental health problems are used than they would be regarding data associated with other health problems. It is likely more palatable to many to think about doctors’ notes from a recent knee surgery being analyzed than notes from a recent therapy session. Patients are also more likely to feel comfortable being honest with their orthopedic doctor than with the therapist, so these notes from therapy may in fact be data of a lower quality. This stigma also contributes to the vital importance of keeping data related to mental health private and safe.
Additionally, there is serious room for improvement in our existing treatments and diagnostic capabilities. While data science can certainly help address some of these problems over time, it is far easier to use data to diagnose a disease that we thoroughly understand than one that we don’t. It is also easier to evaluate a treatment if there are clear biomarkers or other indicators that can be used to measure how well it is working. Many studies now rely on self-reporting from patients, which may not truly capture the impact of a given treatment.
Finally, it is still difficult to acquire good data. There is certainly far more useful data than ever before and lots to be done with these data, but there is often poor infrastructure for maintaining and sharing data related to mental health care. HIPAA laws also typically present some challenges to acquiring any healthcare data. Further complicating data quality is the fact that most people do not receive treatment for their mental health problems, which means that any treatment data represents the population in treatment, not the population who needs treatment.
CASE STUDIES
Although data science in mental health is less developed than data science in other areas of healthcare, crucially important and incredibly exciting work is already happening in this area. Below, I will describe 3 promising case studies that demonstrate the enormous potential for data science to revolutionize the state of mental health care in the United States.
Case Study 1: Crisis Text Line
The Crisis Text Line provides free, 24/7 crisis counseling by trained volunteers via text. These volunteer counselors have handled over 5 million text conversations since the line’s inception in 2013. A tech company at heart, Crisis Text Line embraces the importance of using their data to improve the care which they provide and to enhance our broader understanding of mental health problems.
Sometimes, the texters in need of crisis intervention outnumber the available volunteers. While this situation is unideal for anyone in need of help, the Crisis Text Line knows that some people are much more urgently in need of assistance than others. The company has used machine learning models to identify words and emojis that indicate higher suicide risk, allowing them to move the most high-risk texters to the front of the queue. The models use data from text conversations that led to an active rescue (i.e., use of emergency services), which is a new and vitally important kind of data. Prediction of suicide attempts and suicide fatalities is notoriously difficult, and the field lacks an effective screening tool or other effectively predictive mechanism. Having the ability to predict these events through text messaging behavior, therefore, has enormous potential to eventually address this diagnostic weakness in a broader manner.
Findings produced by these machine learning models underscore the importance of using data-driven approaches in mental health, as the indicators of higher suicide risk aren’t particularly intuitive. In fact, use of the words “Advil” and “Ibuprofen” are 14 times more predictive of a suicide attempts than use of words like “cut,” “die,” “suicide,” or “kill,” and the crying-face emoji is 11 times more predictive than the word “suicide.” By relying on data rather than intuition, the Crisis Text Line is able to identify persons in serious crisis more accurately and efficiently and to provide assistance more rapidly.
In addition to the development of this risk-detection tool, the Crisis Text Line is committed to putting their data to use for the overall betterment of mental health. In addition to a regular blog in which insights gleaned from their data are published, the Crisis Text Line hosts an interactive dashboard built from their data that allows users to explore patterns in emotional distress across the United States. Users can filter by topic and geographic area to explore co-occurring problems, geographic differences, time-series patterns, as well as the language frequently used to describe a given problem:
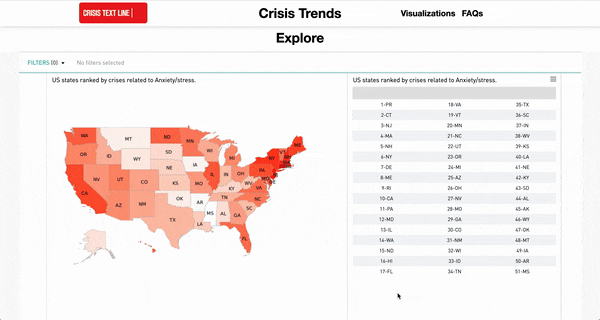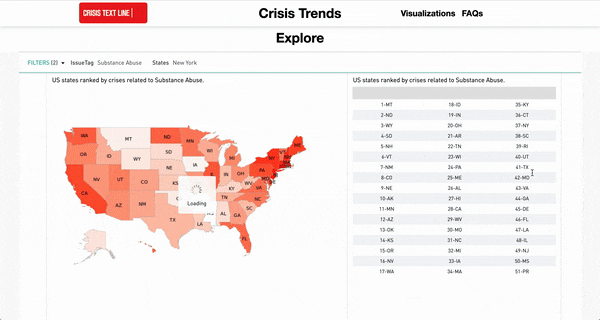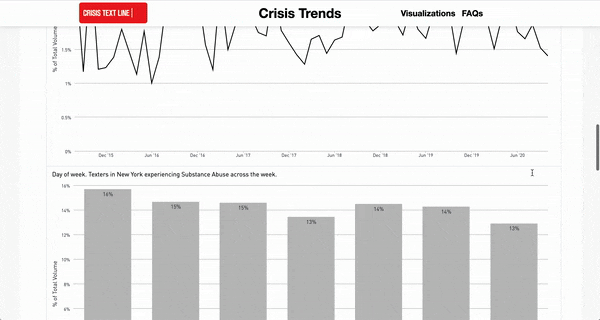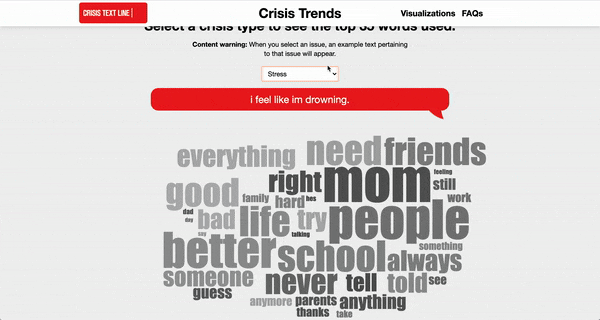
Screen capture of www.crisistrends.org
The Crisis Text Line has also taken steps to ensure that the sensitive data shared with them by texters remains safe. Texters can request that their data be scrubbed at any point, and a built-in algorithm removes personally-identifiable information such as names, phone numbers, and places.
Case Study 2: Ellie the 3-D Chat Bot
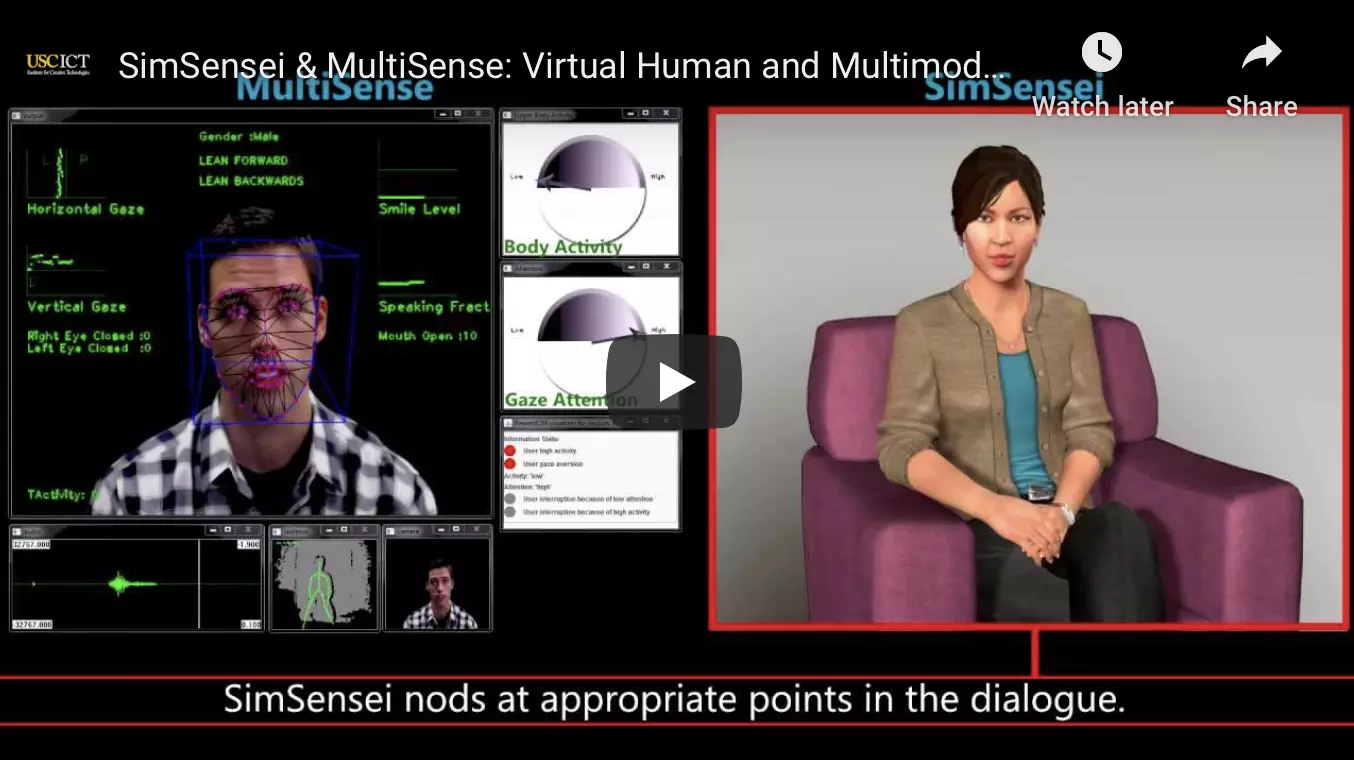
Ellie in action: https://www.youtube.com/watch?v=ejczMs6b1Q4
“Ellie,” pictured above, was created by researchers at the University of Southern California’s Institute for Creative Technologies. The project was funded by the Defense Advanced Research Projects Agency with the goal of addressing PTSD among veterans.
Ellie’s creators based her body language and speech patterns off of many hours of recorded video depicting real-life mental health professionals, and she allows patients to be more open and honest than they might be with a real person. Patients often do not want to disclose information if they are afraid that they will be judged or identified, and this is especially true among veterans given the strong stigma attached to mental illness in that community.
Ellie is not capable of replacing traditional treatment, and is instead designed as a “data gatherer” to improve the diagnostic process. When a patient speaks to Ellie, data is collected regarding their rate of speech and the amount of time that they pause before answering questions, as well as the movement and position of 66 unique points on the patient’s face. This process has indicated that patients with PTSD touch their heads and hands more frequently than patients without PTSD, a diagnostic clue that may have been missed entirely without the extensive data collected and analyzed by Ellie. In fact, in a study with patients in Afghanistan, Ellie identified more symptoms of PTSD than the standard Post-Deployment Health Assessment administered to veterans.
Right now, Ellie is an extremely valuable, data-driven treatment support tool. However, the success of this model provides hope that advancements in similar AI may be able to provide alternatives to traditional therapy. Such technology could increase access to care and address the treatment shortage that is so rampant in the United States.
Case Study 3: Quartet Health
Quartet Health is a NYC-based mental health tech company that is committed to improving the quality and accessibility of mental health care through their four-pronged, wraparound approach.
The first part of their model involves connecting to people who need mental healthcare. This can happen through provider referrals, direct patient sign-ups, and screening for people who may be in need of care. This innovative screening process is where data science comes in, as machine learning models are applied to patient medical histories and behavioral patterns to look for signs of undiagnosed mental health problems. This analytic strategy has led to several interesting findings, such as that a patient repeatedly testing negative for cardiac issues is indicative of a possible anxiety disorder.
Identified patients are next matched to an appropriate form of care. The patient’s personal preferences, clinical indications, and insurance coverage are all taken into consideration when selecting a type of care. Possibilities include traditional therapy and psychiatric care, as well as online programs.
The third prong of the Quartet model is aligned with the company’s overall approach of using data-driven decisions to improve mental health care. Once patients are enrolled in care, the quality of this care is monitored over time by Quartet. By continuously collecting and analyzing data on how patients are doing over time, Quartet can quickly identify when a therapeutic approach is not working and adjust the care that a given patient is receiving.
Finally, Quartet makes sure to support enrolled patients along the way. Referring providers often do not receive any updates regarding their patient’s experience with mental health treatment, but Quartet connects referring providers and mental health care providers to ensure communication between these vitally important stakeholders. Quartet also provides additional support to those who need it through their team of “Care Navigators.”
This data-driven model has proved effective and is being picked up by insurance companies. Quartet has been able to identify patients who might have mental health struggles following a difficult diagnosis or treatment, has reduced emergency department visits by 15–25% for some of their patients, and has connected significantly more patients to mental health care and in less time than traditional approaches.
Using Google Search Data to Understand COVID-19's Impact on Suicidality
My final example comes from a study that I personally contributed to. As COVID-19 spread rapidly throughout the United States in March and April, my team and I became curious about the impact that this virus and the lockdowns used to contain it might have on suicidality and suicide risk factors.
We theorized that the pandemic may influence the following suicide risk factors: financial strain and unemployment, loneliness, anxiety, grief, and increased stress levels. We decided to use Google searches (via Google Trends data) to assess these risk factors for several reasons. First, Google Trends data was immediately accessible in April and did not rely on healthcare systems which were overwhelmed with COVID-19 patients. Additionally, there is significant prior research establishing association between Google search behavior and suicidal behavior.
We analyzed 18 queries representing four domains:
- Suicide-specific queries: suicide -squad, kill myself, kill yourself, suicide method(s), commit suicide, fast/easy/quick/painless suicide
- Help-seeking queries: crisis text line, national suicide prevention lifeline + national suicide hotline, disaster distress helpline + disaster distress hotline
- General mental health queries: depression, panic attack, anxiety
- Financial difficulty queries: unemployment, I lost my job, laid off, furlough, loan
- Uncategorized queries: loneliness
We used weekly search data from March 1, 2020 through April 18, 2020, which we had defined as the early pandemic period for the purposes of this study. Autoregressive integrated moving average (ARIMA) models were trained on one year of data (March 3, 2019 through February 29, 2020) and used to predict weekly relative search volume during the early pandemic period. Percent differences were then calculated between observed and expected observations:
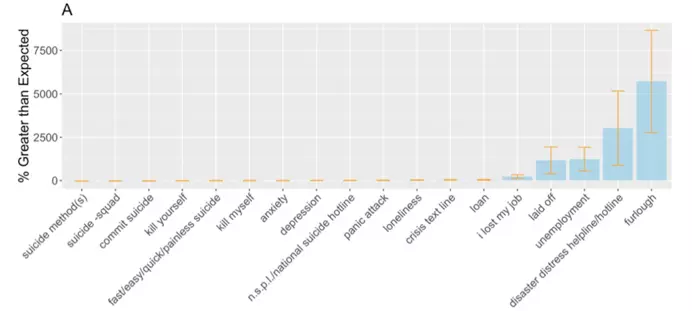
Percent difference with 95% CIs for all included queries. Image by author.
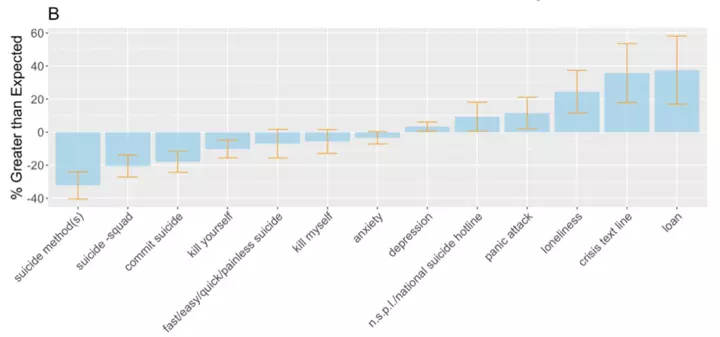
Percent difference with 95% CIs, limited to queries with smaller percent differences for visualization purposes. Image by author.
As can be seen above, queries representative of financial difficulty (a known risk factor for suicide) and the Disaster Distress Helpline (promoted extensively during the pandemic’s early stages) were drastically elevated. Elevation of the financial difficulty queries is particularly concerning, and one study even found searches for “laid off” to be the strongest predictor of actual suicides with a 2-month delay.
When we zoom in on those queries which were dwarfed by changes in the financial queries, we see that searches explicitly related to suicide were actually moderately decreased. This may be due to the national sense of community in the early stages of the pandemic as we all grappled with its immediate stressors together. There is a precedent for this pattern, as decreases in suicidality have been seen after national disasters such as the 9/11 attacks. Unfortunately, however, long-term increases in suicide deaths were seen after the 1918 flu and the 2003 SARS outbreak, and we expect that a long-term increase in suicidality and suicide deaths may occur if appropriate interventions are not made.
Studies such as ours are important in that they have been used to draw attention and resources toward the impact of COVID-19 on mental health. Our study was published on July 24, 2020 in PLOS ONE and can be found here.
Conclusions
Although the mental health field stands to benefit enormously from an increased use of data science, developments in this area lag behind those made in other areas of healthcare. That being said, exciting advancements have been made by organizations such as the Crisis Text Line, University of Southern California’s Institute for Creative Technologies, and Quartet Health. The success of these projects underscores the importance and potential benefit of data science applications in mental health.


Leave your comments
Post comment as a guest