Comments (2)
Ian Hopley
Thanks for sharing, that was so interesting.
Nick White
God damn interesting !

Having been involved in the Semantic space for more than a decade and a half, I've seen quite a few arguments that seem to be eternal.
Do you use upper ontologies or not? Is SHACL better than OWL? Property Graphs vs. Semantic Graphs? Yet of all the arguments that I've heard, one of the most common is whether it is better to use randomly generated IRIs (usually using some form of UUID) or some form of human friendly IRI?
It is likely that this one will be a key question that people first coming to knowledge graphs grapple with, and every semantic project I've worked on usually ends up taking hours to come up with a good answer to that - with the answers evenly split on both sides. For instance, which is better?
or

If the goal here is to ensure uniqueness, then there is no question that the first expression is unique. A typical type 4 UUID will be repeated about once every 100 sextillion times, which means that, even in a superfast environment with lots of data, the first form will be about as unique as you could possibly want.
What the second form provides, however, is identification. I do not know what the first IRI stands for. Neither do you? I do know what the second indicates. This is great is the goal is reducing collision of identifiers, but from a pedagological (e.g., teaching) perspective, the second expression is far more valuable.
This is especially true for the workhorses of an ontology: the classes and properties that are used to draw relationships together. If I have a situation where I want to say that a particular article is of type article, using UUIDs will give you the following very helpful assertion*:

* The statement just given was with tongue firmly in cheek.
The statement just given might very well be the same as the following:

Then again, it may be something completely different, and you would never know.
The reality is that we routinely use both uuids and friendly IRIs all the time, and even (sometimes) make efficient use of namespaces. The problem though is that all too often the either or conundrum obscures the fact that not all can you use both together, you probably should.
For instance, namespaces (which in my personal opinion are badly underutilized) are far more helpful when you do want to use friendly IRIs.

Namespaces work reasonably well in conjunction with friendly IRIs. While this seems like a lot for one statement, when you have ten billion such assertions in your database, being able to manually see what's going on makes a big difference in getting to the root of a problem. It also tends to make it easier to write queries in languages such as SPARQL:

So given this, why don't we use friendly names more often. There are actually a number of reasons, some valid, some rather bogus:
For instance, if I changed the name of my article to "Versioning and RDF objects" the IRI will no longer represent the represented content of the object in question.
However, what if a friendly name was in fact simply another property of a specific resource IRI that was a randomly generated GUID. For instance, consider the case above. Let's say that every object did have a UUID name. Blank nodes are in fact one way of talking about such UUID objects, as a Turtle blank node such as

may be represented internally as:

or perhaps (for base 64 fans):

A blank node simply says: here's a randomly generated sequence of characters that can guarantee non-collision.
So, if I create a statement:

in essence, what I am doing is associating a UUID with a friendly IRI. If you have a reasoner in use, the engine should allow you to use the friendly URI anywhere that UUID is invoked. If you don't (and increasingly that's the case), you can take advantage of sparql to follow the dereference:

This generates a table along the lines of:
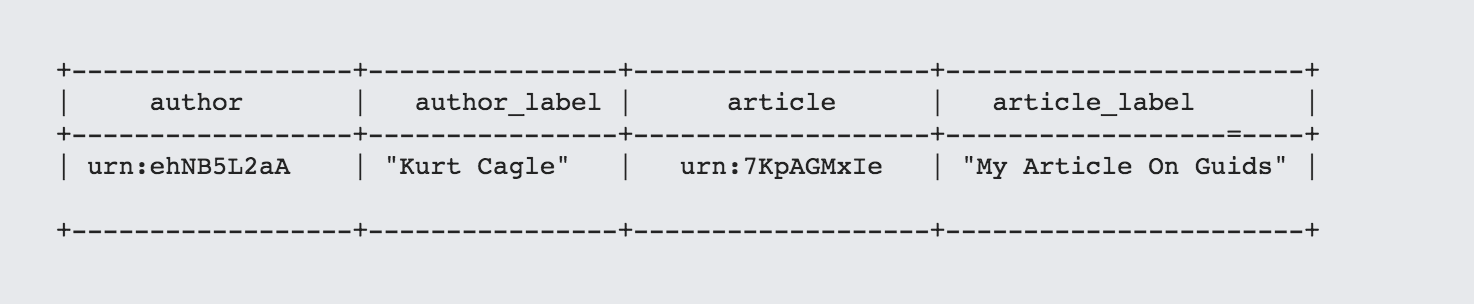
So far, this makes a good argument for using UUIDs. Where things become a little more problematic is when the resource in question is itself a property or a class. For instance, let's say that rather using rdfs:label and schema:author, we use thing:label and article:author (with appropriately defined namespaces). The Turtle requires three more assertions:

The Sparql does change:

The first statement in the select block is worth examining. In effect, the variable ?article_author gets assigned the randomly generated UUID of the blank node that has an owl:sameAs relationships with the friendly IRI article:author. Note that article:author is not itself the assigned IRI of the relationship - it only appears as an object, never a subject. So the first statement can be read as "find the UUID that has the owl:sameAs property value of article:author".
So, while making for some interesting syntactical sugar, what does this matter? It turns out that it matters a great deal in the problem of versioning. The biggest issue that you face with versioning is that triples are not really records. They don't have intrinsic cohesiveness. If I change the property value on a given entity, the collection of triples associated with that subject is now a different entity. In other words, the entities must become immutable.
If the system of triples doesn't change once created, then immutability isn't an issue, but in any reasonable system, if an entity does change, you need to both have some way to keep the identity of the object the same while at the same time have the versioning change. This can be done through this same kind of mechanism, along with SPARQL UPDATE.
For instance, let's say that you wanted to add a new triple to the entity that identifies a particular topic. The following represents the initial and updated version of the article entity:

In this case, _:_articleVersion1 and _:_articleVersion2 are both UUID based IRIs. They are bound to the same named IRI, `article:_My_article_on_guids_by_kurt_cagle. When a new version is created, the version:currentVersion triple is removed from the old version, and a version:precedingVersion is added, linking the new version to its immediate predecessor. (This is an exercise that can be done in Sparql Update, and is left to the reader).
To get the most recent version, given the friendly IRI, the query is straightforward:

The use of the variable ?publicArticle should be instructive: it is an IRI that is used outside of the current system and is publicly available. The internal IRIs, in this case, are irrelevant - they exist primarily to act as unique keys into the triple store.
Additionally, I've not covered the specific use case of blank nodes acting as a surrogate for properties, primarily because more that a few triple stores do not let you use blank nodes as predicates. This doesn't mean that you can create ersatz blank nodes (something like the above base64 or UUID based urn for instance), which can then be used to version classes and predicates That's a topic for another article, however.
Finally, it should be noted here that I've made use of the owl:sameAs statement as a way of creating an explicit relationship between a named and anonymously generated IRI. All too often people coming into the world of RDF see the property as being the same as A is the same as B. In an inferential system (one with a reasoner), this is a useful side effect, but what it really means is that there is a (potentially one-sided) relationship that ties two IRIs together. I could have just as readily called it thing:hasPublicIRI and be just as correct (and perhaps more precise).
All too often in computing circles you get an either/or mindset where one approach or the other is the ONLY way to work. That mindset, unfortunately, can blind you as a programmer or information architect to the ways that you can work with both approaches to create far more flexibility in the way that you design information spaces. Anonymous vs named IRIs is a classic example of this: be creative, use both!
Kurt Cagle is the author of The Cagle Report and is the Community Editorfor Data Science Central, a TechTarget property. When not writing about semantics or editing other people's writing, he writes science fiction and urban fantasy set in the Pacific Northwest.

Thanks for sharing, that was so interesting.
God damn interesting !
Kurt is the founder and CEO of Semantical, LLC, a consulting company focusing on enterprise data hubs, metadata management, semantics, and NoSQL systems. He has developed large scale information and data governance strategies for Fortune 500 companies in the health care/insurance sector, media and entertainment, publishing, financial services and logistics arenas, as well as for government agencies in the defense and insurance sector (including the Affordable Care Act). Kurt holds a Bachelor of Science in Physics from the University of Illinois at Urbana–Champaign.
BBN Times connects decision makers to you. Experts in their fields, worth listening to, are the ones who write our articles. We believe these are the real commentators of the future. We quickly and accurately deliver serious information around the world. BBN Times provides its readers human expertise to find trusted answers by providing a platform and a voice to anyone willing to know more about the latest trends. Stay tuned, the revolution has begun.
Leave your comments
Post comment as a guest